-
Word Embedding 3 : Deep Contextualized Word Representations (ELMo) 정리AI/NLP 2022. 1. 17. 16:40728x90
Deep Contextualized Word Representations (ELMo) 정리
들어가기 전 ... Word Embedding
https://asidefine.tistory.com/152
Word Embedding 01 (One-hot Encoding / Word2Vec ) 정리
[논문 목록] 1. Word2Vec : Efficient Estimation of Word Representations in Vector Space (https://arxiv.org/abs/1301.3781) 들어가기 앞서 컴퓨터는 텍스트 그 자체보다는 숫자를 더 잘 처리합니다 따라서,..
asidefine.tistory.com
https://asidefine.tistory.com/154
Word Embedding 02 ( Glove / FastText ) 정리
[논문 제목] 1. GloVe : global vectors for word representation (https://nlp.stanford.edu/pubs/glove.pdf) 2. FastText : Enriching Word Vectors with Subword Information (https://arxiv.org/abs/1607.0460..
asidefine.tistory.com
1. Introduction
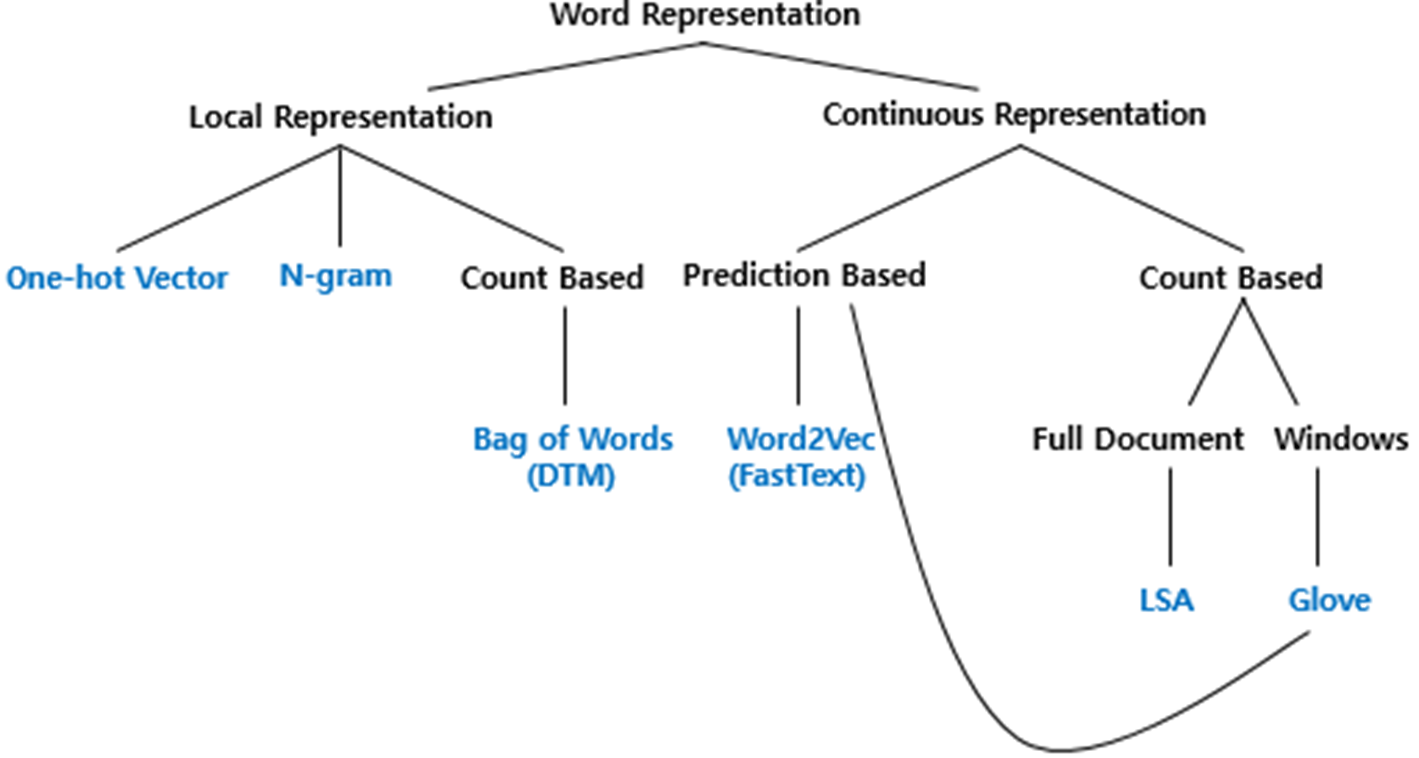
컴퓨터는 텍스트 그 자체보다 숫자를 더 잘 처리합니다. 따라서 자연어처리에서는 텍스트를 숫자로 바꾸기 위한 여러 방법들을 사용하는데 이를 word embedding이라고 합니다.
ELMo 등장 이전에는 이전에 말씀드렸던 것처럼 word2vec, GloVe와 같은 모델을 주로 사용하였습니다.
하지만 기존의 word2vec이나 glove와 같은 word embedding 기법은 다의어의 모든 의미를 담아 내기 힘들다는 한계점을 가지고 있습니다. Spring이라는 단어를 예로 들어 설명하겠습니다.
첫번째 문장에서의 spring은 봄을 의미하고, 두번째 문장에서의 spring은 용수철을 의미합니다. 이처럼 spring은 여러 의미를 가진 다의어로, 문맥에 따라 전혀 다른 의미를 가지는데 Word2Vec이나 Glove로 표현된 임베딩 벡터는 이를 제대로 반영하지 못합니다. 두 방법 모두 Spring이란 단어를 하나의 임베딩 벡터로 표현했을 때, 봄이라는 의미를 가지는 문장과 용수철이라고 쓰이는 문장에서 모두 똑같은 벡터를 사용하게 됩니다.
오늘 볼 ELMO 논문에서는 같은 표기의 단어라도 문맥에 따라 word embedding을 하여 구분하겠다는 아이디어를 사용합니다.
다시 한번 정리하자면 ELMo 논문에서는, 문맥을 반영하여 단어를 표현하는 word embedding 방법에 대해서 소개합니다. ELMO는 context 내의 syntax와 semantic 정보를 모두 활용하여 다의어에 대해서 효과적으로 대응합니다.
또한 큰 corpus에 대해 pretrain된 bidirectional language model을 사용한다는 것이 가장 큰 특징입니다.
2. Related Work
3. ELMo: Embeddings from Language Models
3.1. Bidirectional language models
ELMO 모델의 구조에 대해서 바로 말씀드리겠습니다. 앞서 ELMO는 pretrain된 bidirectional 모델을 사용한다고 말씀드렸는데요.
input sequence가 N개의 token들 (t1,t2,...,tNt1,t2,...,tN)일 때, forward LSTM은 t1,...,tk−1t1,...,tk−1이 주어졌을 때 tk를 예측합니다. 반대로 backward LSTM은 tk+1,tk+2,...,tNtk+1,tk+2,...,tN이 주어졌을 때 tk를 예측합니다.
biLM은 위의 두 LSTM을 결합한 것으로, 두 방향에 대한 log likelihood를 최대화하는 것을 목표로 합니다.
이때 biLM의 각 시점의 입력이 되는 단어 벡터는 임베딩 층(embedding layer)을 사용해서 얻은 것이 아니라 합성곱 신경망을 이용한 문자 임베딩(character embedding)을 통해 얻은 단어 벡터입니다. 예를 들어, 단어 'have'를 'h', 'a', 'v', 'e'와 같이 문자 단위로 분리합니다. 그리고 임베딩 층(Embedding layer)을 이용한 임베딩을 단어에 대해서 하는 것이 아니라 문자에 대해서 하게 됩니다. (https://wikidocs.net/116193)

Forward LM : computes the probability of the sequence by modeling the probability of token t_k given the history (t1, ..., tk−1)

backward LM : is similar to a forward LM, except it runs over the sequence in reverse, predicting the previous token given the future context

A biLM combines both a forward and backward LM. Our formulation jointly maximizes the log likelihood of the forward and backward directions

- the token representation (Θx) and Softmax layer (Θs)
- 이 두 parameter는 전체 direction에 관계 없이 같은 값을 공유하지만, LSTM의 parameter들은 두 LSTM model이 서로 다른 값을 갖는다.
3.2. ELMo

ELMo의 구체적인 과정을 이어서 설명드리도록 하겠습니다. 이 예제에서는 play란 단어가 임베딩이 되고 있다는 가정 하에 ELMo를 설명합니다. play라는 단어를 임베딩 하기위해서 ELMo는 위의 점선의 사각형 내부의 각 층의 결과값을 재료로 사용합니다.
1) 각 층의 출력값을 연결(concatenate)한다.
첫번째로, play라는 단어의 시점에서의 BiLM의 각 층의 출력값을 가져옵니다. 그리고 순방향 언어 모델과 역방향 언어 모델의 각 층의 출력값을 연결합니다.
ELMo에서는 새로운 representation을 사용하는데, 이를 얻기 위해서는 LSTM layer의 개수를 L이라고 했을 때 총 2L+1개의 representation을 concatenate해야 한다. input representation layer 1개와 forward, backward LSTM 각각 L개입니다.



2) 각 층의 출력값 별로 가중치를 준다.
각 LSTM layer의 output인 hk,jhk,j를 모두 더하는데 이 때 각각에 softmax-normalized weights sjsj를 곱한 뒤 더하게 된다. 당연하게도 ∑Lj=0staskj=1=이다

3) 각 층의 출력값을 모두 더한다.
이어서 세번째로 가중치를 곱한 모든 값들을 더하여, 각 층의 출력값의 가중 합을 구해줍니다.

4) 벡터의 크기를 결정하는 스칼라 매개변수를 곱한다.
마지막으로 벡터의 크기를 결정하는 스칼라 매개변수 감마를 곱해줌으로써 ELMo 벡터를 얻습니다.


s_j와 γ는 모두 learnable parameter이면서 optimization에서 매우 중요한 역할을 담당한다.
3.3 Using biLMs for supervised NLP tasks
이렇게 만든 ELMO를 어떻게 NLP task들에 적용하는지 살펴보겠습니다. 대부분의 supervised NLP model들의 input은 모두 context-independent token들의 sequence입니다. 이러한 공통점 덕분에 동일한 방법으로 대부분의 task에 ELMo를 적용할 수 있습니다. 우선 NLP model의 input layer와 다음 layer 사이에 ELMo를 넣습니다. 이렇게 완성된 벡터는 기존의 임베딩 벡터와 함께 사용할 수 있습니다. 즉 input token과 ELMo embedding vector의 concatenation을 NLP model의 input으로 사용합니다.
(NLP model을 train할 때에는 ELMo의 weight들은 모두 freeze시킨다. 즉, ELMo model은 NLP model이 train될 때 함께 train되지 않습니다)

3.4. Pre-trained bidirectional language model architecture

또한 ELMo는 기존의 pre-trained biLM와 큰 구조는 비슷하지만 몇가지 차이점이 존재하는데, 가장 큰 차이점은 LSTM layer 사이에 residual connection을 사용했다는 점입니다. 이를 통해 input의 feature를 더 잘 전달하고 gradient vanishing을 해결할 수 있습니다. L=2개의 biLSTM layer를 사용했습니다.
4. Evaluation
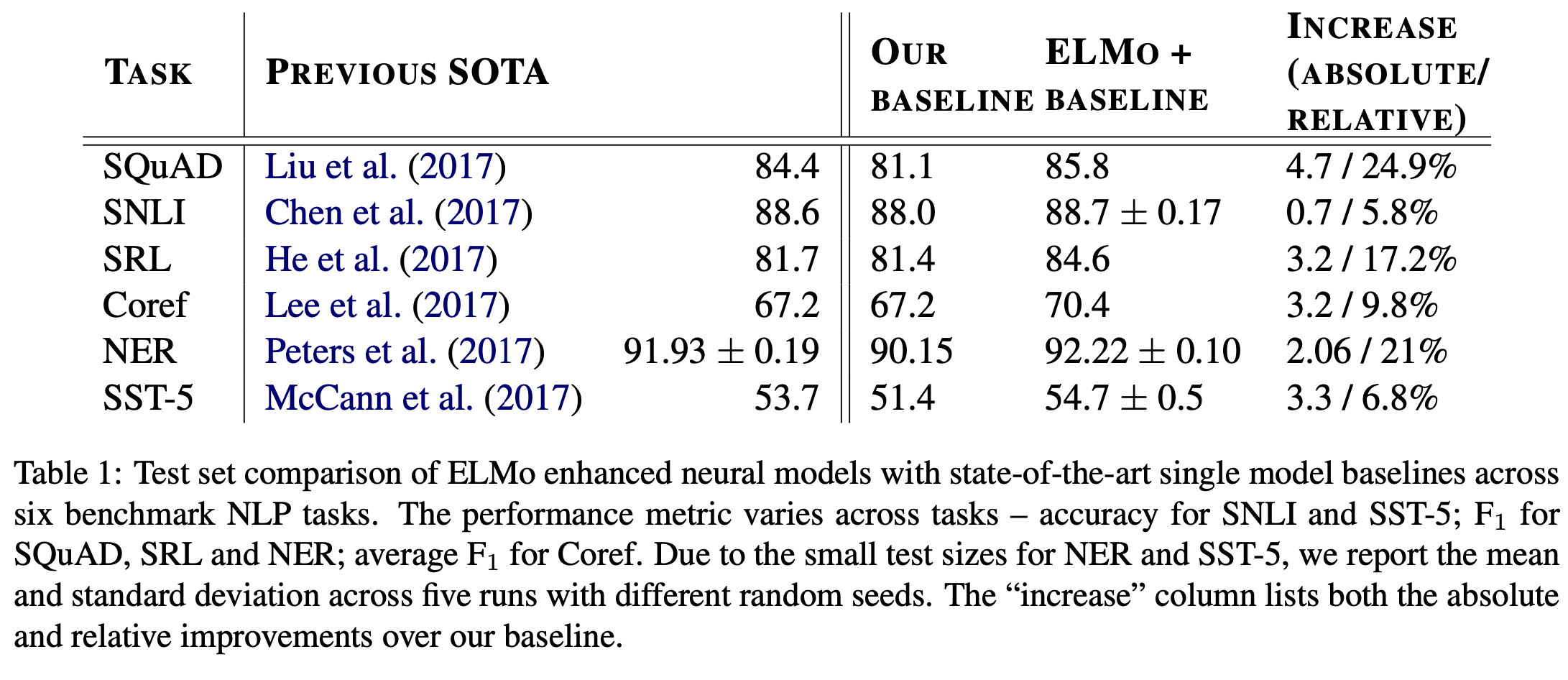
다음으로 ELMO을 자연어처리의 여러 task에 적용한 결과를 보여드리도록 하겠습니다.
Question Answering, Textual Entailment 등 자연어 처리의 task 5가지에 대해 각각의 SOTA모델과 baseline 모델, 그리고 Baseline 모델에 ELMO을 적용한 모델의 성능을 비교해본 결과, ELMo를 적용했을 때 모든 Task에 대해서 SOTA 을 경신했음을 알 수 있습니다.
- Semantic Role Labeling : 문장의 중심적 의미와 관련하여 who did what to whom, when, why를 발견하는 것
- Textual Entailment: 두 문장이 주어졌을 때, 첫 번째 문장이 두 번째 문장을 수반하는가 혹은 위배되는가?
- Coreference Resolution: 문장 내 대명사 “it”이 존재하고 해당 대명사가 지칭할 수 있는 명사가 많을 때, “it”이 지칭하는 정확한 대상은 무엇인가?
- Named Entity Recognition: 문장 내 특정 단어가 고유 명사, 기관명 혹은 엔티티인가?
5. Analysis
5.1. Alternative layer weighting schemes

앞에서 살펴봤듯이 λ는 softmax-normalized weights sjsj에 대한 regularization parameter인데, 0~1 사이의 값을 갖습니다. λ가 1에 가까울수록 각 layer에서의 output들을 평균에 가깝게 계산해 최종 vector를 생성해내고 (s_j가 모두 유사한 값), λ가 0에 가까울수록 각 layer에서의 output들에 다양한 값들이 곱해서 더해집니다.
위 결과에서 보듯이 단지 마지막 layer만 쓰는 것보다 모든 layer를 쓰는 것이 더 좋으며, 각각을 단순평균하는 것이 아닌 가중합을 하였을 때, 더 성능이 좋아지는 것을 볼 수 있습니다.
5.2. Where to include ELMos?

위에서 언급했듯 supervised NLP model에 ELMo를 적용할 때에는 input layer의 직후에 ELMo를 삽입했습니다. SQuAD, SNLI, SRL의 baseline model은 모두 biRNN model인데, ELMo를 biRNN 직후에도 삽입을 한 뒤 성능을 비교했습니다.
SQuAD와 SNLI에 있어서는 ELMo를 biRNN 이후에도 추가하는 것이 더 좋은 성능을 보여줬는데, 이는 SNLI와 SQuAD는 biRNN 직후 attention layer가 있는데, biRNN과 attention layer 사이에 ELMo를 추가함으로써 ELMo representation에 attention이 직접적으로 반영됐기 때문이라고 유추해 볼 수 있습니다.
5.3. What information is captured by the biLM's representation?
Word sense disambiguation

WSD는 다의어의 의미를 구분짓는 task로 embedding이 얼마나 semantic 정보를 잘 담고 있는지에 대한 지표입니다. 주목할만한 점은 ELMo의 first LSTM layer의 output보다는 second layer (top layer)의 output이 WSD에서 좋은 성능을 보였다는 점입니다.
POS tagging

POS tagging은 word의 품사를 tagging하는 task로 embedding이 얼마나 syntax 정보를 잘 담고 있는지에 대한 지표입니다. WSD와는 다르게 오히려 first LSTM layer의 output이 top layer의 output보다 POS tagging에서 더 좋은 성능을 보였습니다.
결론적으로 ELMo에서 각 layer는 담고 있는 정보의 종류가 다르다고 할 수 있는데, 층이 낮은 layer(input layer에 가까운 layer)일수록 syntax 정보를, 층이 높은 layer(output layer에 가까운 layer)일수록 semantic 정보를 저장합니다.
5.4. Sample Efficiency

ELMo의 사용은 일정 수준 이상의 성능 달성에 필요한 parameter update 횟수 및 전체 training set size를 획기적으로 줄여즙니다. ELMo를 추가했을 때는 그렇지 않을 때보다 학습속도도 빠르며(최대 49배 정도) 학습데이터가 적을 때도 훨씬 효율적으로 학습합니다.
5.5. Visualizataion of learned weights

입력 layer에서 task 모델은, 특히 corefenrece와 SQuAD에서 첫번째 biLSTM layer를 선호합니다. 출력 layer에서 낮은 레이어에 조금 더 중점을 두지만 상대적으로 균형잡힌 모습을 보여줍니다.
6. Conclusion
1. biLM을 사용해 높은 수준의 context를 학습하는 ELMo model을 제안
[introduced a general approach for learning high-quality deep context-dependent representations from biLMs]
2. ELMo model을 사용하면 대부분의 NLP task에서 성능 향상
[shown large improvements when applying ELMo to a broad range of NLP tasks]
3. layer의 층이 올라갈수록 syntax보다는 semantic한 정보를 담아낸다는 사실도 발견
[the biLM layers efficiently encode different types of syntactic and semantic information about words-in-context]
4. 때문에 어느 한 layer를 사용하는 것보다는 모든 layer의 representation을 결합해 사용하는 것이 전반적인 성능 향상에 도움이 된다는 결론
[using all layers improves overall task performance]
Reference
09) 엘모(Embeddings from Language Model, ELMo)
 논문 링크 : https://aclweb.org/antho ...
wikidocs.net
https://aclanthology.org/N18-1202/
Deep Contextualized Word Representations
Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, Luke Zettlemoyer. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Vol
aclanthology.org
https://www.youtube.com/watch?v=zV8kIUwH32M
https://cpm0722.github.io/paper-review/deep-contextualized-word-representations
[NLP 논문 리뷰] Deep Contextualized Word Representations (ELMo)
Paper Info
cpm0722.github.io
https://www.mihaileric.com/posts/deep-contextualized-word-representations-elmo/
Deep Contextualized Word Representations with ELMo - Mihail Eric
In this post, I will discuss a recent paper from AI2 entitled Deep Contextualized Word Representations that has caused quite a stir in the natural language processing community due to the fact that the model proposed achieved state-of-the-art on literally
www.mihaileric.com
[논문 리뷰] Deep contextualized word representations
Deep contextualized word representations 리뷰
medium.com
728x90'AI > NLP' 카테고리의 다른 글
NLP Benchmark Datasets 정리 (GLUE / SQuAD/RACE) (0) 2022.02.04 RoBERTa: A Robustly Optimized BERT Pretraining Approach 정리 (0) 2022.02.04 Word Embedding 01 (One-hot Encoding / Word2Vec ) 정리 (0) 2021.12.31 Word Embedding 02 ( Glove / FastText ) 정리 (0) 2021.12.31 Seq2Seq & Attention & Transformer 정리 (0) 2021.12.31