-
시간, 메모리 효율적으로 LLM 학습하기 (2) (DP, DDP, FSDP, DeepSpeed ... )AI/NLP 2024. 11. 4. 22:14728x90
시간, 메모리 효율적으로 LLM 학습하기 (2)
(DP, DDP, FSDP, DeepSpeed ... )모델을 학습시키다 보면 OOM 문제를 맞닥뜨리게도 되고, 또 학습하는 시간 때문에도 골머리를 앓게 된다...!
본인에게 가능한 환경에서 최대한의 퍼포먼스를 낼 수 있는 방법을 찾아보자!
본 포스트에서는 Multi GPU 환경에서 할 수 있는 방안에 대해서 살펴본다
아래의 글과 영상을 참고한다.
https://huggingface.co/docs/transformers/perf_train_gpu_many
Efficient Training on Multiple GPUs
If training a model on a single GPU is too slow or if the model’s weights do not fit in a single GPU’s memory, transitioning to a multi-GPU setup may be a viable option. Prior to making this transition, thoroughly explore all the strategies covered in
huggingface.co
https://www.youtube.com/watch?v=gXDsVcY8TXQ&list=LL&index=2&t=844s
감사합니다, 선생님 ... 들어가기 앞서 ... 내 GPU에 몇 Billion LLM 올라갈 수 있는가?
- 8bits = 1bytes
- 16bits = 2bytes
VRAM Requirements → 한 파라미터당 최소 16bytes 필요하게 됨!!!!!
= Model Parameters [최소 16 bits = 2 bytes]
+) Gradients [최소 16 bits = 2 bytes]
+) Optimizer States (Optimizer가 안정적이기 위해선 무조건 32bits 사용해야 됨)
- Adam Optimizer를 사용할 때엔 아래와 같이 필요함
- Momentum terms (gradient history) [32 bits = 4 bytes]
- Adaptive terms (Gradient Variance History) [32 bits = 4 bytes]
- Parameter in 32 bits [32 bits = 4 bytes]
+) Activations
- Seq length와 Batch Size에 따라 달라짐
- → Activation = weight * Input
- → Input = Batch Size * Seq Length
따라서 1B 모델이라면 16GB VRAM, 70B라면 70*16VRAM!
하지만 현존하는 가장 큰 VRAM은 A100의 VRAM 80GB..... 필연적으로 Multi GPU 환경에서 학습이 필요하게 된다
분산 학습 - Model Sharding & Data Sharding (Parallel)
멀티 GPU에 학습을 분산하는 방법에는 두 가지가 있다.
- 모델을 나누는 방법
- 한 모델이 쪼개져 worker에 할당되어 훈련
- 데이터를 나누는 방법
- worker마다 모델을 복사하여 로드한 후, 각자 다른 훈련 데이터를 넣어 훈련
1. DP
- 단순히 데이터를 분배한 후 평균을 취한다.
- → GPU 사용 불균형 문제 발생, Batch 사이즈 감소 (한 GPU가 병목), GIL
# 모델을 DataParallel로 래핑합니다. parallel_model = torch.nn.DataParallel(model) # 멀티 GPU에서 순전파를 수행합니다. predictions = parallel_model(inputs) # 손실 함수를 계산합니다. loss = loss_function(predictions, labels) # 역전파를 수행합니다. loss.mean().backward() # GPU 손실 평균값을 계산하고 역전파를 수행합니다. optimizer.step() # 새로운 매개변수로 순전파를 수행합니다. predictions = parallel_model(inputs)net = torch.nn.DataParallel(model,device_ids=[0,1,2]) output = net(input_var) # input_var can be on any device, including CPUPyTorch를 이용한 학습 코드는 아래와 같이 수정이 가능합니다. 먼저 모델을 DataParallel 클래스로 감싸는 과정이 필요하고, forward의 결과도 기존과는 조금 다른 형태이기 때문에 이를 수정해주어야 합니다. loss 값을 각 GPU에서 가져오기 때문에 결과의 크기가 GPU의 개수만큼 나오게 되므로 이를 압축해주면 됩니다.
import torch.nn as nn def train(device, batch_size, epochs=100): model = T5ForConditionalGeneration.from_pretrained("t5-large") **model = nn.DataParallel(model) # DataParallel로 모델을 감싸야 함** model.to(device) dataset = DummyDataset() dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, drop_last=True) optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9) for epoch in range(epochs): for data in tqdm(dataloader): **data = {k: data[k].to(device) for k in data}** **optimizer.zero_grad()** output = model(**data) **# output이 scalar 형태가 아니므로, 압축이 필요함 torch.mean(output.loss).backward()** optimizer.step()- 먼저 모델을 DataParallel 클래스로 감싸는 과정이 필요하고, forward의 결과도 기존과는 조금 다른 형태이기 때문에 이를 수정해주어야 합니다.
- loss 값을 각 GPU에서 가져오기 때문에 결과의 크기가 GPU의 개수만큼 나오게 되므로 이를 압축해주면 됩니다
- 여러 개의 GPU에서 딥러닝을 실행하려면, 모델을 복사해서 각 GPU에 할당해야한다.
- 그 뒤 batch size를 batch_size/num_gpu만큼 나눈다. 이것을 scatter 한다고 표현한다. (실제로 scatter 함수가 있다.)
- 각 GPU에서 모델이 입력을 받아 출력하는 것을 forward 한다고 표현하고, 이 출력들을 하나의 GPU로 모은다.
- 이렇게 여러 tensor들(출력들)을 하나의 device로 모으는 것을 gather라고 한다.
- 그리고 back propagation (gradient를 구하는 과정)을 GPU 개별로 하기 때문에 각 GPU에 있는 모델들이 각각의 gradient를 가지고 있다. 모델을 업데이트 시키려면 또 이 gradient들을 하나의 GPU로 모아서 업데이트를 해야 한다.
- DataParallel에서는 이 replicate -> scatter -> gather을 아래의 코드로 간단하게 실행할 수 있다.
def data_parallel(module, input, device_ids, output_device): **replicas = nn.parallel.replicate(module, device_ids**) **inputs = nn.parallel.scatter(input, device_ids)** replicas = replicas[:len(inputs)] **outputs = nn.parallel.parallel_apply(replicas, inputs)** return **nn.parallel.gather(outputs, output_device)**- 하지만, gather가 하나의 GPU로 모아주기 때문에 이 GPU는 메모리 사용량이 너무 많아지게 된다.
- GPU를 한 곳에 몰아주는 nn.DataParellel의 설정 때문에 극심한 GPU memory 불균형이 일어난다.
- DataParellel에서 하나의 GPU로 출력을 모아준 이유는 loss function을 계산했어야했기 때문

2. DDP
- 만약 올리고자 하는 모델이 GPU 한 개의 VRAM에 다 맞는 경우, DDP를 사용할 수 있다
- DDP에서는 모델 파라미터, gradient, optimizer에서 사용하는 states 등을 모두 각 GPU에서 보관하고, 데이터만 병렬적으로 쪼개서 학습 -> 개별적으로 연산의 평균을 냄
3. FSDP (Fully Sharded Data Parallel)

- 만약 올리고자 하는 모델이 GPU 한 개의 VRAM에 다 맞지 않는 경우, FSDP를 사용하는 것이 좋다
- DDP와 달리, FSDP는 Model Parallel까지 해준다 - 각 GPU에 Layer를 나눠서 할당한다
- 통신에 대한 overhead가 늘어나는 대신, GPU가 다룰 수 있는 모델의 크기는 더 커질 수 있다
- 과정
- forward 과정에서 모델의 각 layer를 통과할 때마다 다른 GPU에 저장되어 있는 파라미터를 가져와 사용하고 제거합니다 (All Gather 연산)
- 이후 backward 과정에서 다시 gradients를 계산하기 위해 다른 GPU에 저장되어 있는 파라미터를 가져와서 사용하고 (All Gather 연산)
- 각 GPU에서 계산된 gradients를 다시 원래 속해 있던 GPU에 전달하기 위해서 Reduce Scatter 연산을 사용
- 각 GPU에는 각 GPU가 갖고 있던 모델에 대한 gradients만 남기 때문에, 이후 optimizer의 step 연산을 통해 모델의 파라미터를 업데이트할 수 있습니다
- 통신에 대한 overhead가 발생하기 때문에 DDP보다 빠른 시간은 보장할 수 없다.
4. DeepSpeed
- *) DeepSpeed의 Stage3과 FSDP가 같은 것이라고 생각하면 쉽다
- DeepSpeed는 ZeRO(Zero Redundancy Optimizer)로도 불리우는데, optimizer states에 대한 GPU memory burden을 줄이는 것이 핵심이기 때문이다.
- ZeRO는 stage 1, stage 2, stage 3, 총 3개의 stage가 있고, stage 2와 3은 offload 방법이 존재한다.
- Offload는 optimizer states와 gradients를 cpu에 내려서 계산하는 방법이다. cpu는 gpu에 비해 느리기 때문에 딥러닝 학습에서 계산 비용이 높은 것들은 cpu에서 수행하면 안 된다. (따라서 Optimizer States에선 offload 없다)
- 딥러닝에서 시간 복잡도는 보통 O(modelsize∗batchsize)를 따르며, GPU에서 대부분의 메모리는 optimizer states에서 차지한다. optimizer states는 계산 비용이 Forward, Backward 연산에 비해 적은 편으로 CPU에서 계산하게 된다면, GPU의 메모리를 절약할수 있다.
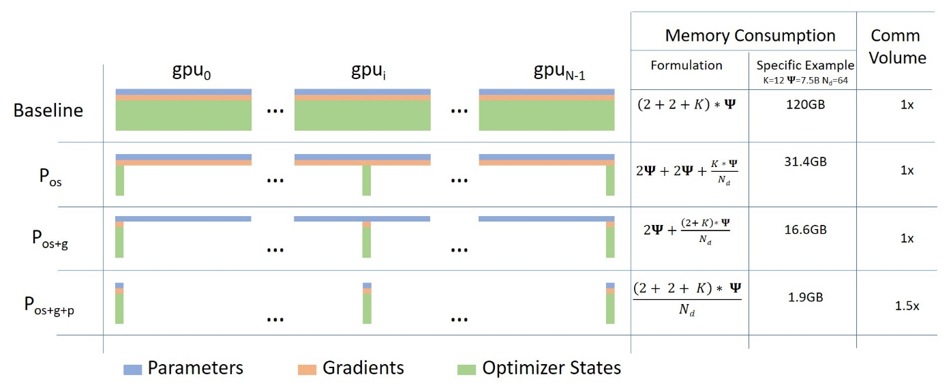
Stage 1
Stage 1의 핵심은 Optimizer States Partitioning이다.
Multi-GPU training에서 model을 GPU에 올릴 때 크게 parameters, gradients, optimizer states 3개로 구분할 수 있다.
여기서 optimizer states는 계산 부담이 큰 forward와 backward 연산에는 참여하지 않으면서, 메모리의 대부분을 차지한다.
optimizer states를 분산시켜 저장한다면, 연산 속도는 유지하면서 GPU 메모리를 상당히 절약할 수 있다.
Microsoft blog에 따르면 메모리를 최대 4배 절약할 수 있으며, PyTorch Lightning DeepSpeed 문서에 따르면 DDP와 동등한 속도를 유지하며, 메모리를 더욱 절약할 수 있다고 한다.
Stage 2
Stage 2는 Stage 1에 Gradients Partitioning을 더한 것이다.
Gradients까지 partitioning한다면 더욱 메모리를 절약할 수 있다.
Microsoft blog에 따르면 메모리를 최대 8배 절약할 수 있으며, PyTorch Lightning DeepSpeed 문서에 따르면 Gradients Partitioning으로 인한 GPU간 통신 비용의 증가에도 불구하고, DeepSpeed 팀의 최적화를 통해 DDP와 동등하거나 더 나은 속도를 제공하며, 메모리를 stage 1보다 더 절약할 수 있다고 한다.
Basic usage
from pytorch_lightning import Trainer from pytorch_lightning.plugins import DeepSpeedPlugin model = MyModel() trainer = Trainer(gpus=4, plugins="deepspeed_stage_2_offload", precision=16) trainer.fit(model)More speed benefit
DeepSpeedCPUAdam을 사용해, 기존에 PyTorch 구현체에서 사용하던것 보다 빠르고, CPU에서 계산 가능한 Optimizer를 제공한다.
import pytorch_lightning from pytorch_lightning import Trainer from pytorch_lightning.plugins import DeepSpeedPlugin from deepspeed.ops.adam import DeepSpeedCPUAdam class MyModel(pl.LightningModule): ... def configure_optimizers(self): # DeepSpeedCPUAdam provides 5x to 7x speedup over torch.optim.adam(w) return DeepSpeedCPUAdam(self.parameters()) model = MyModel() trainer = Trainer(gpus=4, plugins="deepspeed_stage_2_offload", precision=16) trainer.fit(model)Stage 3
Stage 3은 Stage 2에 Parameters Partitioning을 더한 것이다.
Stage 3에서는 model의 모든 구성 요소를 다 쪼개는 것이다.
Microsoft blog에 따르면 메모리 절약 정도는 GPU 개수에 비례한다고 하며, 대규모 모델, 대규모 서버에 적용되면 모든 stage 중에 가장 메모리 효율적이다.
Stage 2와 같이 offload 옵션 사용 시, CPU로 메모리를 전송 및 연산하게 하여 메모리 공간을 더 확보할 수 있다.
이외 추가 이점들
- Offload의 경우 single GPU에서도 사용 가능하고 GPU VRAM 공간을 더 확보할 수 있음(stage 2도 마찬가지).
- Infinity offload라 불리는 CPU와 NVMe 메모리를 모두 사용하여 엄청난 메모리 절약을 할 수 있음.
ZeRO Stage 3 Offload
from pytorch_lightning import Trainer from pytorch_lightning.plugins import DeepSpeedPlugin # Enable CPU Offloading model = MyModel() trainer = Trainer(gpus=4, plugins="deepspeed_stage_3_offload", precision=16) trainer.fit(model) # Enable CPU Offloading, and offload parameters to CPU model = MyModel() trainer = Trainer( gpus=4, plugins=DeepSpeedPlugin( stage=3, offload_optimizer=True, offload_parameters=True, ), precision=16, ) trainer.fit(model)토치 라이트닝으로 DeepSpeed ZeRO Stage 3를 사용할때 팁.
- Adam 또는 AdamW를 사용하는 경우 기본 토치 옵티마이저 대신 FusedAdam 또는 DeepSpeedCPUAdam(CPU 오프로딩용)을 사용.
- GPU/CPU 메모리를 하나의 큰 풀로 다룰것. 어떤 경우에는 모델 매개변수를 오프로드하기 위해 더 많은 공간을 제공하기 위해 특정 항목(예: Activations)을 오프로드하고 싶지 않을 수 있다.
- CPU로 오프로드할 때 GPU 메모리가 해제되므로 배치 크기를 늘릴것.
- 분할된 체크포인트를 지원. save_full_weights=False하여 DeepSpeedPlugin을 통해 매우 큰 모델을 저장할 수 있는 모델의 조각을 저장할수 있다. 그러나 모델을 로드하고 테스트/검증/예측을 실행하려면 Trainer 개체를 사용해야 한다.
Accelerate로도 FSDP, DeepSpeed 모두 사용할 수 있다.
Accelerate는 Config 파일을 사용해서 동작하는데, Config 파일을 설정하려면 다음과 같이 커맨드라인을 입력합니다.
compute_environment: LOCAL_MACHINE **deepspeed_config: {}** **distributed_type: FSDP** **fsdp_config: min_num_params: 2000 offload_params: false** **sharding_strategy: 1** machine_rank: 0 main_process_ip: null main_process_port: null main_training_function: main mixed_precision: 'no' num_machines: 1 num_processes: 2 use_cpu: falseConfig 파일은 아래와 같이 설정해야 하는데, 홈 폴더 아래의 .cache/huggingface/accelerate/default_config.yaml를 직접 수정해 주셔도 됩니다. distributed_type에 FSDP, fsdp_config가 잘 작성되어 있는 걸 볼 수 있습니다.
compute_environment: LOCAL_MACHINE debug: false **deepspeed_config: deepspeed_multinode_launcher: standard gradient_accumulation_steps: 4 offload_optimizer_device: none offload_param_device: none zero3_init_flag: true zero3_save_16bit_model: true zero_stage: 3 distributed_type: DEEPSPEED** downcast_bf16: 'no' machine_rank: 0 main_training_function: main mixed_precision: bf16 num_machines: 1 num_processes: 8 rdzv_backend: static same_network: true tpu_env: [] tpu_use_cluster: false tpu_use_sudo: false use_cpu: false**accelerate launch --config_file "configs/deepspeed_config.yaml" train.py \\** --seed 100 \\ --model_name_or_path "meta-llama/Llama-2-70b-hf" \\ --dataset_name "smangrul/ultrachat-10k-chatml" \\ --chat_template_format "chatml" \\ --add_special_tokens False \\ --append_concat_token False \\ --splits "train,test" \\ --max_seq_len 2048 \\ --num_train_epochs 1 \\ --logging_steps 5 \\ --log_level "info" \\ --logging_strategy "steps" \\ --eval_strategy "epoch" \\ --save_strategy "epoch" \\ --push_to_hub \\ --hub_private_repo True \\ --hub_strategy "every_save" \\ --bf16 True \\ --packing True \\ --learning_rate 1e-4 \\ --lr_scheduler_type "cosine" \\ --weight_decay 1e-4 \\ --warmup_ratio 0.0 \\ --max_grad_norm 1.0 \\ --output_dir "llama-sft-lora-deepspeed" \\ --per_device_train_batch_size 8 \\ --per_device_eval_batch_size 8 \\ --gradient_accumulation_steps 4 \\ --gradient_checkpointing True \\ --use_reentrant False \\ --dataset_text_field "content" \\ --use_flash_attn True \\ --use_peft_lora True \\ --lora_r 8 \\ --lora_alpha 16 \\ --lora_dropout 0.1 \\ --lora_target_modules "all-linear" \\ --use_4bit_quantization FalseReference.
다중 GPU를 효율적으로 사용하는 방법: DP부터 FSDP까지
안녕하세요. 테서의 연구개발팀에서 의료 용어 해석을 진행하고 있는 노수철입니다.
medium.com
https://brunch.co.kr/@chris-song/96
GPU 분산 학습 기법: All-Reduce
All-Reduce | All-Reduce를 공부하는 중에 좋은 아티클이 있어서 번역해봤습니다. 제가 좋아하는 AutoML 라이브러리 optuna를 만든 일본 PFN의 인턴 분이 작성했던 글이네요. https://tech.preferred.jp/en/blog/technol
brunch.co.kr
DDP보다 더 발전된 전략 탐색
FSDP, DeepSpeed
dimensionstp.github.io
728x90'AI > NLP' 카테고리의 다른 글