-
LLM 서빙하기 (2) - Triton Inference Server로 LLM 서빙하기 (HuggingFace 모델을 Triton으로 배포하는 방법)AI/NLP 2025. 4. 5. 20:03728x90
LLM 서빙하기 (2) - Triton Inference Server로 LLM 서빙하기
(HuggingFace 모델을 Triton으로 배포하는 방법)아래에선 HuggingFace 모델을 Triton으로 배포하는 방법을 배워보자
https://github.com/triton-inference-server/tutorials/tree/main/HuggingFace
Triton에 HuggingFace 모델 배포하는 2가지 방법:
✅ 방법 1: Python Backend 사용 (전체 파이프라인 통째로 배포)
빠르고 간단하게 배포하고 싶을 때 사용
- Python 코드 안에 전처리 → 모델 추론 → 후처리 모두 포함
- model.py에서 TritonPythonModel 클래스를 만들고,
- initialize()에서 모델 로딩
- execute()에서 추론 실행
- finalize()는 선택
- 서버에서 tritonserver --model-repository=/models로 실행
- 클라이언트는 Python SDK로 추론 요청
🟢 장점:
- 설정 간단, 빠르게 실행 가능
- HuggingFace 모델 그대로 사용 가능
🔴 단점:
- 모든 단계가 CPU에서 실행될 수도 있음
- 추론 성능 최적화가 어려움
✅ 방법 2: Triton Ensemble 사용 (전처리/모델/후처리 분리)
성능 최적화와 확장성을 원할 때 사용
- 파이프라인을 구성 요소별로 분리:
- 전처리: Python Backend (예: feature extractor)
- 모델: ONNX, TensorRT 등 고성능 backend
- 후처리: 필요 시 Python Backend
- 각 구성 요소를 Triton의 Ensemble 기능으로 연결
- BLS: preprocessing - tensorrt_llm - postprocessing을 하나의 chain으로 구성
- preprocessing: 전처리
- tensorrt_llm: LLM 모델 (우리는 TensorRT-LLM을 통해 LLM 속 연산들을 최적화할 것임)
- postprocessing: 후처리
- BLS: preprocessing - tensorrt_llm - postprocessing을 하나의 chain으로 구성
- 모델 저장 구조 예:
model_repository/ ├── ensemble_model/ │ └── config.pbtxt ├── preprocessing/ │ ├── 1/model.py │ └── config.pbtxt └── vit/ ├── 1/model.onnx └── config.pbtxt🟢 장점:
- **모델 추론을 GPU + 고성능 백엔드(TensorRT, ONNX)**에서 실행 가능
- 병렬화 및 파이프라인 최적화 용이
🔴 단점:
- 설정이 조금 복잡하고 구성요소가 더 많음
방법 1 Python Backend로 전체 파이프라인 배포 (빠르고 유연함) 방법 2 Ensemble로 전처리/모델/후처리 분리 (최적화에 유리) 추천 개발 초기엔 방법 1 → 서비스 단계에선 방법 2로 전환
2번 방법에 대해서 더 알아보자
Triton Inference Server의 Ensemble 기능을 사용하여 HuggingFace 모델 중 ViT을 배포하는 방법을 단계별로 살펴본다
✅ 전체 과정 요약: Triton Ensemble 배포 흐름
- HuggingFace 모델 다운로드 및 ONNX 변환
- Triton 모델 저장소(모델 리포지토리) 구조 구성
- Triton Python Backend를 이용한 전처리
- ONNX Runtime으로 모델 추론
- Ensemble로 위 두 단계를 연결
- Triton Server 실행 & 클라이언트 요청
🧩 1. 모델 다운로드 및 ONNX 변환
docker run -it --gpus=all -v ${PWD}:/workspace nvcr.io/nvidia/pytorch:23.05-py3- PyTorch NGC 컨테이너 실행
- GPU 사용 가능하고, PyTorch 환경이 사전 설정됨
pip install transformers pip install transformers[onnx]- HuggingFace Transformers 라이브러리 설치
- ONNX 변환 기능도 함께 설치
python -m transformers.onnx --model=google/vit-base-patch16-224 --atol=1e-3 onnx/vit- ViT 모델을 ONNX 형식으로 변환 (onnx/vit/model.onnx 생성됨)
- --atol=1e-3은 변환 시 허용 오차
🧩 2. Triton 모델 저장소 구조
model_repository/ ├── ensemble_model/ ← Ensemble 전체를 정의 │ ├── 1/ │ └── config.pbtxt ← 연결 정보 작성 ├── preprocessing/ ← 전처리: Python backend │ ├── 1/model.py │ └── config.pbtxt └── vit/ ← ONNX 추론 모델 ├── 1/model.onnx └── config.pbtxt (auto-generated 가능)🧩 3. 전처리: Python Backend
model_repository/preprocessing/1/model.py
from transformers import ViTFeatureExtractor import triton_python_backend_utils as pb_utils class TritonPythonModel: def initialize(self, args): # 모델/리소스 로딩 pass def execute(self, requests): # 매 요청마다 실행 (추론 수행) pass def finalize(self): # 모델 종료 시 실행 passTriton에서 Python Backend를 쓸 경우, 모델 코드를 직접 Python으로 작성해야 하고, TritonPythonModel 클래스를 정의한 뒤 다음 함수들을 구현합니다.
✅ 1. initialize(self, args)
Triton이 모델을 처음 로딩할 때 1번만 실행됨
🔹 역할:
- 모델이나 관련 객체를 초기화할 때 사용
- 예: HuggingFace 모델, 토크나이저, 설정값 등 로딩
🔹 코드 예시:
def initialize(self, args): self.feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224-in21k') self.model = ViTModel.from_pretrained("google/vit-base-patch16-224-in21k")✅ 요약:
- Triton이 처음 시작할 때 모델 메모리에 올려두는 함수
- **선택적(optional)**이지만 대부분 정의하는 것이 좋음
✅ 2. execute(self, requests)
클라이언트가 요청을 보낼 때마다 매번 실행됨
🔹 역할:
- 실제 추론 로직을 수행하는 함수
- 입력 → 전처리 → 추론 → 출력 변환 → 응답
🔹 코드 예시:
def execute(self, requests): responses = [] for request in requests: # 입력 텐서 받기 inp = pb_utils.get_input_tensor_by_name(request, "image") input_image = np.squeeze(inp.as_numpy()).transpose((2,0,1)) # 전처리 inputs = self.feature_extractor(images=input_image, return_tensors="pt") # 추론 outputs = self.model(**inputs) # 결과 반환 inference_response = pb_utils.InferenceResponse(output_tensors=[ pb_utils.Tensor("label", outputs.last_hidden_state.numpy()) ]) responses.append(inference_response) return responses✅ 요약:
- 실제 추론이 수행되는 메인 함수
- 여러 요청을 한 번에 받을 수 있으므로 for request in requests 사용
- pb_utils를 통해 Triton과 데이터 교환
✅ 3. finalize(self)
Triton이 모델을 **종료(unload)**할 때 실행
🔹 역할:
- 메모리 해제, 로그 저장, 정리 작업 등
- 사용하지 않아도 무방하지만 리소스 정리가 필요하면 정의
✅ 요약:
- 리소스 반환 용
- 선택적(optional)
🧩 4. 모델 추론: ONNX Backend
- vit/1/model.onnx는 ONNXRuntime backend가 자동 인식
- config.pbtxt는 자동 생성되지만, 명시하고 싶으면 수동으로 작성 가능
🧩 5. Ensemble 구성
ensemble_model/config.pbtxt 예: (protobuf 형식)
name: "ensemble_model" platform: "ensemble" input [ { name: "INPUT_IMAGE" data_type: TYPE_UINT8 dims: [3, 224, 224] } ] output [ { name: "OUTPUT_LABEL" data_type: TYPE_FP32 dims: [768] } ] ensemble_scheduling { step [ { model_name: "preprocessing" model_version: -1 input_map { key: "image" value: "INPUT_IMAGE" } output_map { key: "features" value: "EXTRACTED_FEATURES" } }, { model_name: "vit" model_version: -1 input_map { key: "pixel_values" value: "EXTRACTED_FEATURES" } output_map { key: "last_hidden_state" value: "OUTPUT_LABEL" } } ] }- ensemble_scheduling 안에서 각 모델 연결
- 입력/출력을 매핑해서 파이프라인 구성
🖥️ Terminal 실행
🔹 Terminal 1: Triton Server
# 모델 디렉토리 구성 mv ensemble_model_repository model_repository mkdir -p model_repository/vit/1 mv vit/model.onnx model_repository/vit/1/ mkdir model_repository/ensemble_model/1 # Triton 컨테이너 실행 (예: 23.05 버전) docker run --gpus=all -it --shm-size=256m --rm \ -p8000:8000 -p8001:8001 -p8002:8002 \ -v ${PWD}:/workspace/ \ -v ${PWD}/model_repository:/models \ nvcr.io/nvidia/tritonserver:23.05-py3 bash # 의존성 설치 pip install torch torchvision torchaudio transformers Image # Triton 서버 실행 tritonserver --model-repository=/models🔹 Terminal 2: Triton Client
docker run -it --net=host -v ${PWD}:/workspace/ \ nvcr.io/nvidia/tritonserver:23.05-py3-sdk bash python3 client.py --model_name "ensemble_model"- client.py는 HTTP/gRPC를 통해 ensemble_model에 요청을 보냄
- 입력 이미지 전처리 → ONNX 모델 추론 → 결과 반환
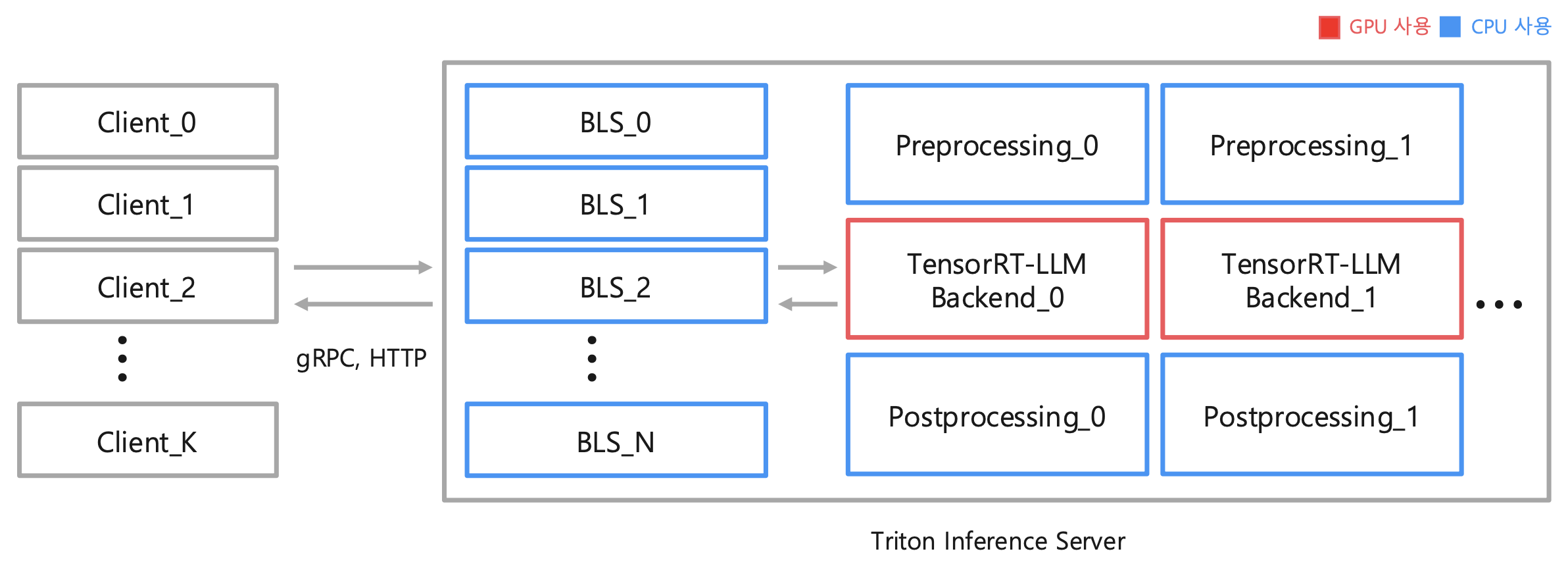
위 방법은 Python Backend로 LLM을 서빙하는 것이기 때문에
TensorRT-LLM이나 vLLM를 Backend로 사용하는 것보다는 당연히 느릴 수 밖에 없다
TensorRT-LLM이나 vLLM를 Backend로 사용하는 것이 궁금하다면 아래의 repo를 봐보자
우리 회사는 TensorRT-LLM + Triton 조합으로 쓰는데,
TensorRT-LLM에서 지원하지 않는 모델이 있다면 vLLM에서 지원하는지 확인해보고 사용하는 것도 좋을 듯하다
https://github.com/triton-inference-server/tensorrtllm_backend
GitHub - triton-inference-server/tensorrtllm_backend: The Triton TensorRT-LLM Backend
The Triton TensorRT-LLM Backend. Contribute to triton-inference-server/tensorrtllm_backend development by creating an account on GitHub.
github.com
https://github.com/triton-inference-server/vllm_backend
GitHub - triton-inference-server/vllm_backend
Contribute to triton-inference-server/vllm_backend development by creating an account on GitHub.
github.com
728x90'AI > NLP' 카테고리의 다른 글
[Team Seminar] Why do LLMs attend to the first token? (0) 2025.05.10 [AI Agent] AI Agent with LangChain / LangGraph / LangSmith (0) 2025.05.10 LLM 서빙하기 (1) - Triton Inference Server란? (0) 2025.03.23 LLM 빠르게 추론하기 (1) - Quantization - 양자화 방법론과 원리 (PTQ, QWA, bitsandbytes, GPTQ, AWQ, SmoothQuant) (0) 2025.03.23 시간, 메모리 효율적으로 LLM 학습하기 (2) (DP, DDP, FSDP, DeepSpeed ... ) (4) 2024.11.04