LLM Decoding Strategy 정리 (Greedy, Beam Search, Top-K, ... )
LLM Decoding Strategy 정리 (Greedy, Beam Search, Top-K, ... )

- Decoding Strategy이란
- 언어 모델이 생성한 logit을 softmax을 적용해 확률로 변환한다면, 그 확률을 바탕으로 다음 토큰을 어떻게 선택할지 결정하는 방식
- 모델이 생성한 출력을 최종 사용자가 이해할 수 있는 형태로 변환하는 방법론

Greedy Search
- 가장 간단한 방법, 각 단계에서 가장 높은 확률을 가진 토큰을 선택
- 언어 모델에서 타임스텝 t에서 가장 높은 확률을 갖는 토큰을 다음 토큰으로 선택하는 전략
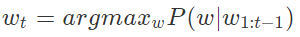
- 장점
- 빠르고 직관적
- 단점
- 문맥적으로 부적합하거나 의미가 불분명한 문장을 생성할 수 있다
- 전체적으로 최적의 문장을 생성하지 못할 수 있음
# 그리디 디코더
def greedy_decoder(data):
# 각 데이터에서 가장 큰 값을 가지는 인덱스들의 배열을 반환
return [argmax(s) for s in data]
- hugging face에서는 do_sample=False
with torch.no_grad():
generated_ids = model.generate(
input_ids,
do_sample=False,
min_length=10,
max_length=50,
)
Beam Search
- 해당 시점에서 유망하다고 판단되는 빔 K개를 골라서 진행하는 방식
- 수식
- 단어를 하나하나씩 생성하여 그 때의 확률값 모두 곱하고 log 붙여 곱셈에서 덧셈으로 식 변경

- 단점
- 계산 비용이 높아질 수 있습니다(빔의 크기에 따라 증가).
- 매우 긴 시퀀스에서는 효율성이 감소할 수 있습니다.

# beam search
def beam_search_decoder(data, k):
sequences = [[list(), 1.0]] # 빈리스트와 점수 1.0으로 초기화
# data에 대해서 반복
for row in data:
all_candidates = list()
#sequences만큼 순회
#최초에는 길이 1
for i in range(len(sequences)):
seq, score = sequences[i]
for j in range(len(row)): # data의 한 row 만큼 순회
candidate = [seq + [j], score * -log(row[j])] # [순서, 1.0 * -log(row의 j번째 요소)]
all_candidates.append(candidate) # 계산된 후보를 list에 삽입
# 후보들을 점수에 따라 정렬
ordered = sorted(all_candidates, key=lambda tup:tup[1])
# 그중에 k개를 반환
sequences = ordered[:k]
return sequences
with torch.no_grad():
generated_ids = model.generate(
input_ids,
do_sample=False,
min_length=10,
max_length=50,
num_beams=3,
)
Top-K Sampling
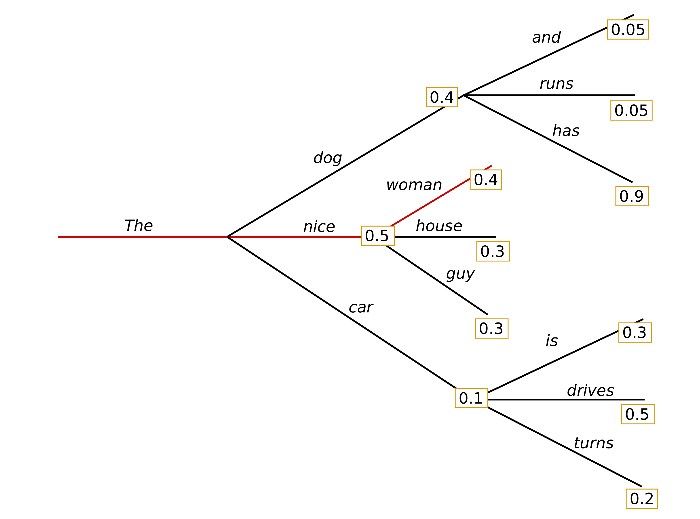
- Sampling 방식 중 하나
- Sampling이란 해당 시점 t의 확률에 따라서 선택하는 것
- Top-K Sampling
- 다음 토큰으로 가능성이 높은 상위 K개의 토큰을 선택한 다음, 이 중에서 확률적으로 하나를 선택
- 가능성이 적은 토큰들이 선택될 여지는 제거
- 단점
- 창의성 떨어짐

with torch.no_grad():
generated_ids = model.generate(
input_ids,
do_sample=True,
min_length=10,
max_length=50,
top_k=50,
)
Top-P Sampling (Nucleus sampling)

- 기준 확률 p를 설정함
- 누적 확률이 p 이상이 되는 최소한의 집합으로부터 샘플링을 하게 하는 전략
- 특정 토큰의 확률이 굉장히 높을 때 사용하는게 좋음

with torch.no_grad():
generated_ids = model.generate(
input_ids,
do_sample=True,
min_length=10,
max_length=50,
top_p=0.92,
)
+) GPT에서의 Temperature
Random Sampling
- 랜덤 샘플링은 토큰이 갖는 확률에 따라 토큰을 선택
- 예를 들어서 '나', '응', '좋은', '한다', '잘'과 같은 토큰들이 들어있는 단어사전 목록
- 각 토큰이 다음에 올 확률을 구한다고 했을 때, '나'가 0.2, '잘'이 0.0001이었다고 가정
- greedy search였다면 확률이 가장 높은 '나'를 선택했을 테지만, random sampling에서는 '나'가 나올 확률은 0.2, '잘'이 나올 확률은 0.0001
- 확률이 적은 토큰이라도 다음 토큰으로 선택될 가능성이 존재
Random Sampling with Temperature
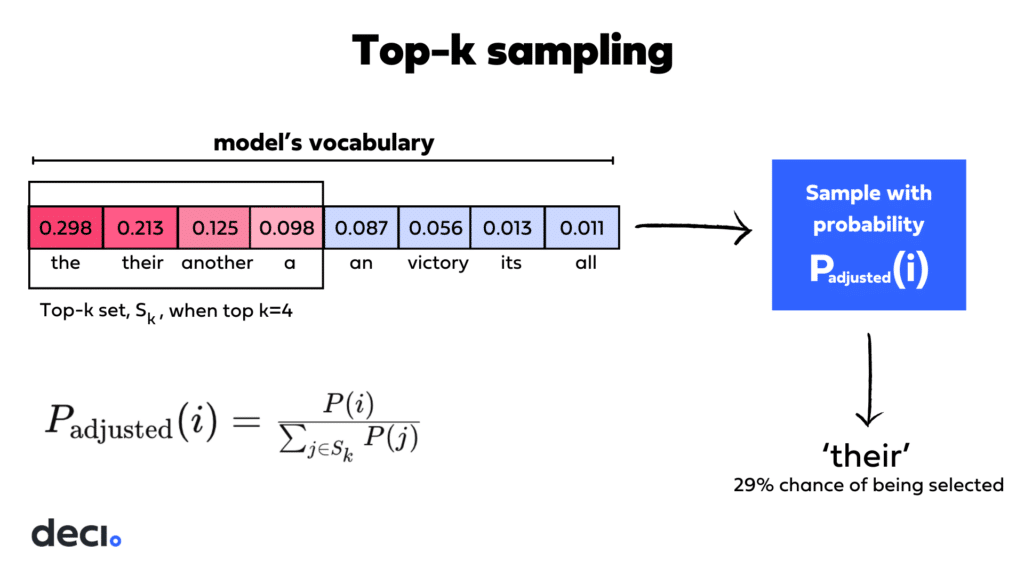
- Temperature는 가능성이 높은 토큰의 확률은 높여주고, 가능성이 낮은 토큰의 확률은 낮춰주는 역할
- OpenAI (link)
- 낮은 값의 temperature는 더욱 일관된 답변을 생성 (예: 0.2)
- 높은 값의 temperature는 더욱 다양하고 창의적인 답변을 생성 (예: 1.0)
- temperature 범위는 0에서 2로 제공
- HuggingFace (link)
- temperature가 0으로 갈수록 greedy decoding과 유사
Related Paper
https://arxiv.org/abs/2402.06196
Large Language Models: A Survey
Large Language Models (LLMs) have drawn a lot of attention due to their strong performance on a wide range of natural language tasks, since the release of ChatGPT in November 2022. LLMs' ability of general-purpose language understanding and generation is a
arxiv.org
https://arxiv.org/abs/1904.09751
The Curious Case of Neural Text Degeneration
Despite considerable advancements with deep neural language models, the enigma of neural text degeneration persists when these models are tested as text generators. The counter-intuitive empirical observation is that even though the use of likelihood as tr
arxiv.org
Ref.
https://hipster4020.tistory.com/194
Huggingface generate 문장 생성
huggingface의 transformer 라이브러리에서 model.generate는 모든 자동 회귀 auto-regressive 언어 모델에 적용 가능합니다. 이 generate 함수를 이용해서 문장 생성 하는데 보다 적은 노력으로 훌륭한 문장을 생
hipster4020.tistory.com
https://deci.ai/blog/from-top-k-to-beam-search-llm-decoding-strategies/
디코딩 전략: Greedy, Beam Search, Random, Temperature, Top-K, Nucleus
디코딩 전략 정리 (greedy, beam search, random sampling, top-k, top-p, and temperature)
velog.io
https://deci.ai/blog/from-top-k-to-beam-search-llm-decoding-strategies/
From Top-k to Beam Search: All About LLM Decoding Strategies
Learn about LLM decoding strategies, including top-k and beam search, in our guide to better control your language model's outputs.
deci.ai