-
Fully convolutional networks for semantic segmentation (FCN) 정리AI/Computer Vision 2022. 1. 15. 22:47728x90
Fully convolutional networks for semantic segmentation (FCN) 정리
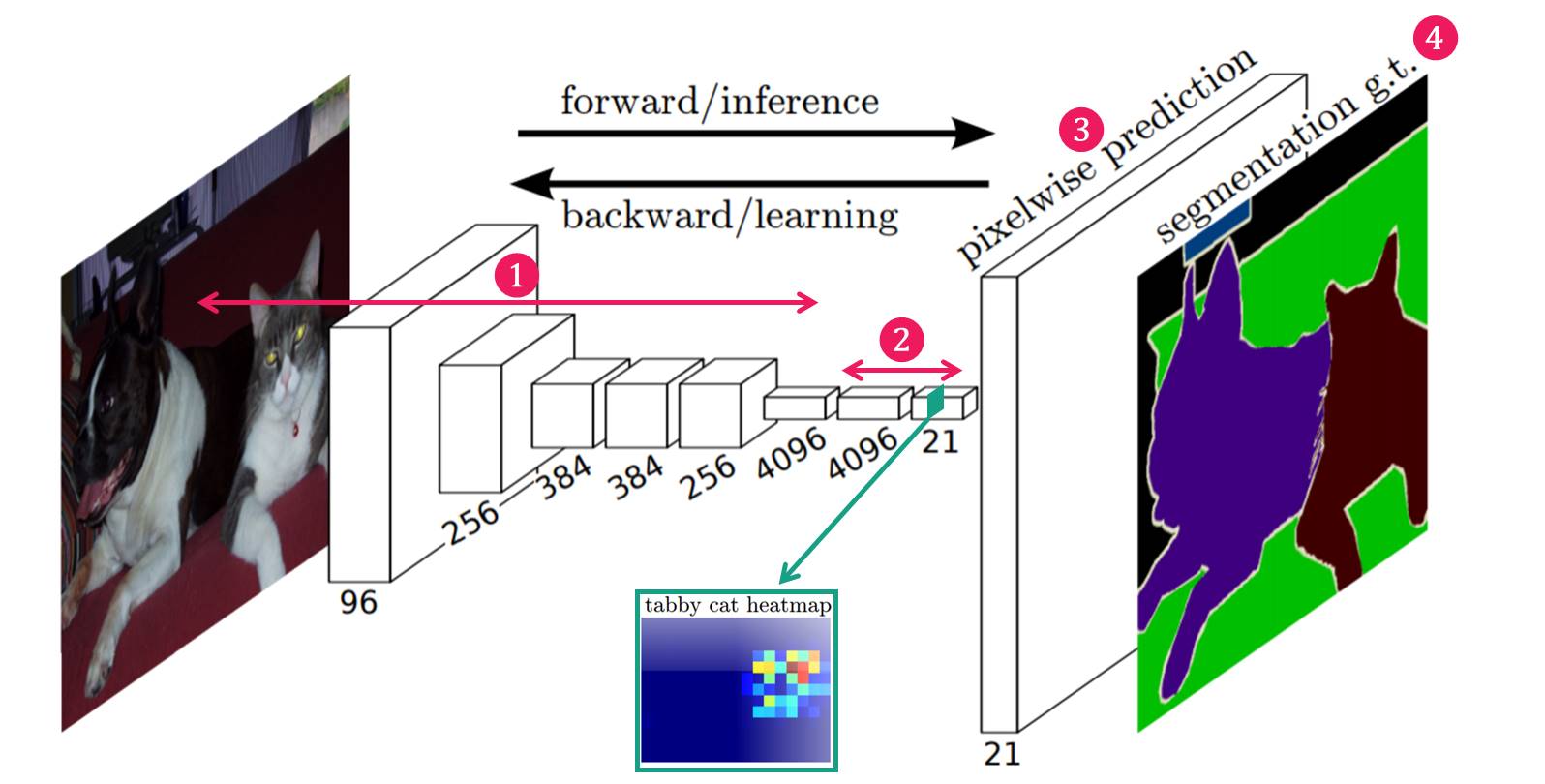
- FCN = Fully Convolutional Network : classifcation을 수행하는 FC layer (Fully Connected Layer)없이, 오직 convolution으로만 모델 구성! -> semantic segmentation을 수행한다!
- 이 논문에서는 모든 부분을 크게 (1) Fully convolutional networks와 (2) semantic segmentation 두 부분으로 나눠서 설명한다.
Introduction과 Related Work 내에서도 이렇게 크게 두 개로 나눠서 설명하므로 유념할 것!
(1) 이 논문에서 Fully Convolutional Networks를 수행하는 방법은 크게 3가지 Pairwise Prediction+supervised pre-training+In-network upsampling layers
(2) semantic segmentation은 Skip Architecture을 사용하여 깊은 층의 sematic 정보와 얕은 층의 appearance 정보를 결합했다는 것!
들어가기 전에 ....
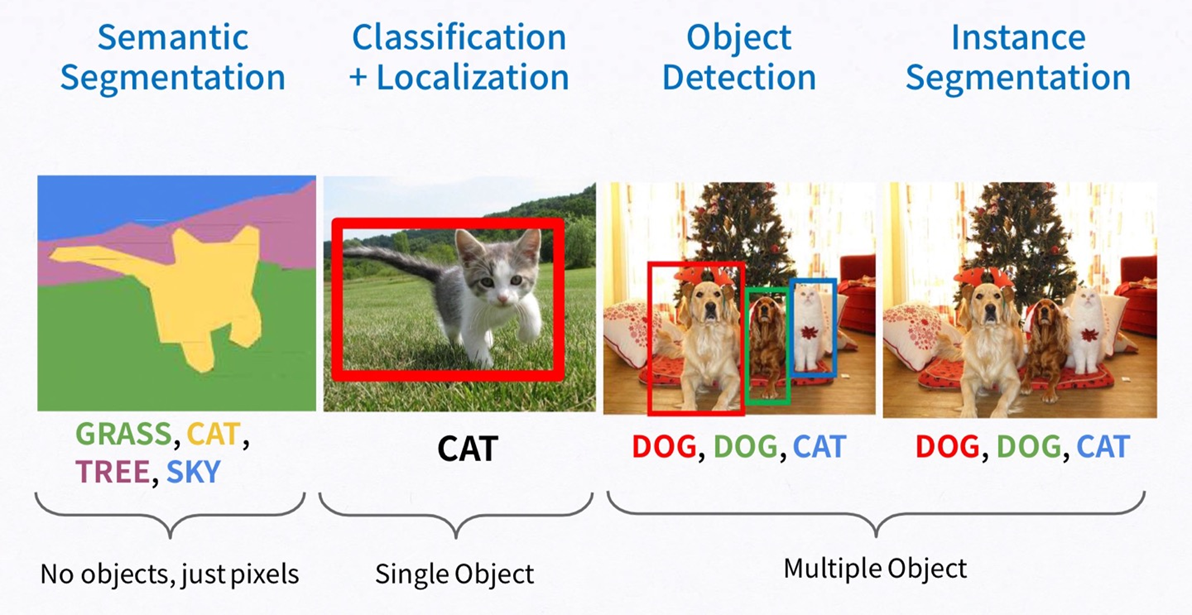
Image와 관련된 여러 task 중에 오늘 볼 논문은 Semantic Segmentation에 관한 논문입니다. Semantic Segmentation이란 이미지를 pixel 단위로 어떤 object인지 classification하는 것이라고 할 수 있습니다.
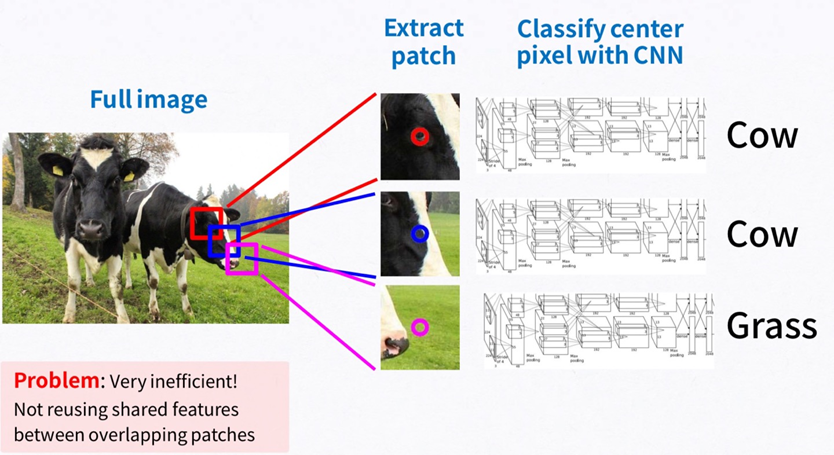
Semantic Segmentation을 수행하는 방법 중 첫번째로 Sliding window, 즉 patchwise방법을 생각해볼 수 있습니다. 이미지 하나에 Window를 Sliding하면서 가운데 pixel을 분류하는 방식으로, Window가 겹치는 부분에 대해 feature들을 서로 공유하지 않아 중복 연산이 매우 많게 됩니다. Patchwise learning 방식은 아래와 같습니다.
- 특정 크기의 patch를 설정해주고 CNN에 입력해 줍니다.
- 입력으로 들어간 patch는 CNN에 의해 classification이 됩니다.
- 이때 특정 class로 분류가 되었다면, 해당 patch 중앙에 위치한 pixel을 해당 class로 분류해줍니다.
- 이러한 과정을 슬라이딩 윈도우 (sliding window) 방식으로 반복하게 됩니다.
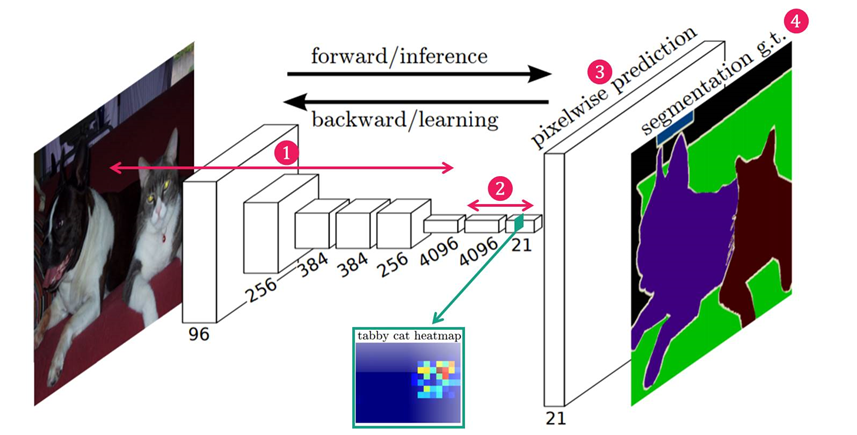
이와 다른 방식으로 Fully Convolutional Network를 사용하여 Segmentation을 진행할 수도 있습니다. 하나의 이미지에 대해 하나의 네트워크로 한번에 연산하므로 데이터를 공유할 수 있다는 장점이 있습니다. 이를 위 방식과 반대로 pixelwise 방식이라고도 합니다.
0. Abstract
1) 현대의 classification 네트워크들(AlexNet/VGG/GoogLeNet)을 Fully convolutional network로 적용하고, fine-tuning을 통해 segmentation task 수행
[adapt contemporary classification networks (AlexNet [20], the VGG net [31], and GoogLeNet [32]) into fully convolutional networks and transfer their learned representations by fine-tuning [3] to the segmentation task]
2) deep, coarse한 layer에서의 semantic 정보들과 shallow, fine한 layer에서의 appearance 정보를 skip architecture를 이용해 결합하여 정확하고 구체적인 segmantation 수행한다
[define a skip architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations.]
1. Introduction
1) Fully Convolutional Networks
이 논문에서는 sematic segmentation 분야에서의 end-to-end, pixels-to-pixels 방식의 FCN 모델을 소개할 것이다.
(1) pairwise prediction과 (2) supervised pre-training 방법, (3) In-network upsampling layers을 사용하는 FCN은 우리가 최초다!
(1) pairwise prediction :
(2) supervised pre-training :
(3) In-network upsampling layers : pixelwise prediction이 가능하게 하고, subsampled pooling을 이용해 학습한다
↔ 기존의 Segmentation 방식
: patchwise 방법을 사용하였지만 computation 많기 때문에 FCN에서는 이 방법 사용하지 않는다
Patch란?
: 하나의 이미지에서 object는 그대로 두고 background를 제거한 것을 patch라 한다.
patchwise 방법이란?
: Patchwise training을 사용하는 이유는 이미지에 필요없는 정보들이 존재할 수 있고, 하나의 이미지에서 서로 다른 object가 존재하는 경우 redundancy(중복성)가 발생한다. 즉, Object와 관련된 feature을 추출해야 하는데 필요없는 배경까지 본다면 불필요한 computation(계산)이 발생한다.2) Semantic Segmentation
"Skip" architecture라는 것을 이용해서 "deep, coarse한 레이어의 semantic 정보(what / semantics)"+ "shallow, fine한 레이어의 appearance 정보 (where / location)" 결합할 것다!
2. Related Work
1) Fully Convolutional networks
2) Dense prediction with convnets
Semantic Image Segmentation의 목적은 사진에 있는 모든 픽셀을 해당하는 (미리 지정된 개수의) class로 분류하는 것입니다. 이미지에 있는 모든 픽셀에 대한 예측을 하는 것이기 때문에 dense prediction 이라고도 불립니다.
이전까지의 dense prediction 모델들은 다음의 방식들을 요소로 사용했지만, 우리 모델은 이런 거 안 쓴다!

<->
우리 모델에서는
1) deep classification net 모델들을 semantic segmentation에 적용하고,
2) image classification을 supervised pre-training으로 사용해서, 모든 image input과 모든 gt값에 대해 fully convolutional network로 fine-tune할 것
3. Fully Convolutional Networks
먼저 신경망에 대한 전반적인 설명 !
각 layer의 feature map은 3차원 배열(h×w×d)로 구성됩니다. 여기서 h와 w는 spatial dimension으로 쉽게 말해서 feature map의 세로와 가로를 의미합니다. d는 color channel을 의미합니다
feature map에서 kernel을 통해서 한개의 노드가 생기는 것을 볼 수가 있습니다. 이 한 개의 노드를 만드는데 관여되는 kernel을 receptive fields라고 합니다. 따라서 기본적으로 receptive fields의 크기는 kernel과 동일한 것도 당연히 받아드릴 수 있습니다.
CNN의 중요한 특성 중 하나는 입력 이미지에서 layer(convolution, pooling, activation function)를 통과시키더라도 위치 정보가 불변한다는 점입니다. 이를 translation invariant라고 말합니다. 단지 receptive fields에 해당하는 feature map들의 영역만 영향을 받습니다.
->
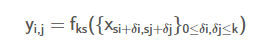
여기서 k는 kernel의 크기, s는 stride 또는 subsampling factor이라고 합니다. 그리고 는 layer의 종류를 의미합니다. 예를들어 convolution layer, average pooling 등이 있습니다.
함수 합성을 적용하는 거는 전체 신경망의 앞에서 뒤로 나아가는 것을 의미합니다. 즉, data가 각종 layer를 통과하는 것을 의미하죠. 그런데 위의 , g는 항상 nonlinear layer입니다. 따라서 data는 항상 nonlinear filter를 계산하게 되는 것이죠. 이런 구조를 갖는 신경망을 fully convolutional network라고 정의합니다.
3.1 Adapting classifiers for dense prediction
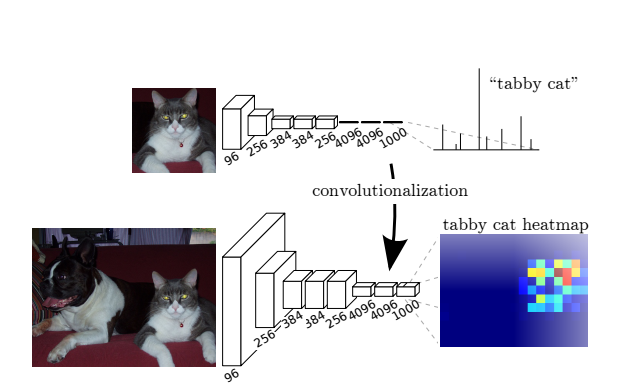
LeNet, AlexNet, VGG 등기존의 신경망들은 모두 반드시 고정된 입력 이미지의 크기를 입력받고, nonspatial 출력을 얻습니다. 여기서 nonspatial 출력은 단순한 classification 결과를 의미합니다. 예를 들어 강아지, 고양이 등을 분류하기위해서 출력이 0, 1이 나오는 것입니다. 신경망의 마지막 단의 fully connected layer가 공간적인 정보를 버리고 단순 scalar로 나오기 때문에 nonspatial입니다.
그래서 FCN에서는 이 fully connected layer를 convolutional layer로 바꾸게 되고 이를 Convolutionalization이라고 합니다.
3.2 Shift-and-stitch is filter rarefaction
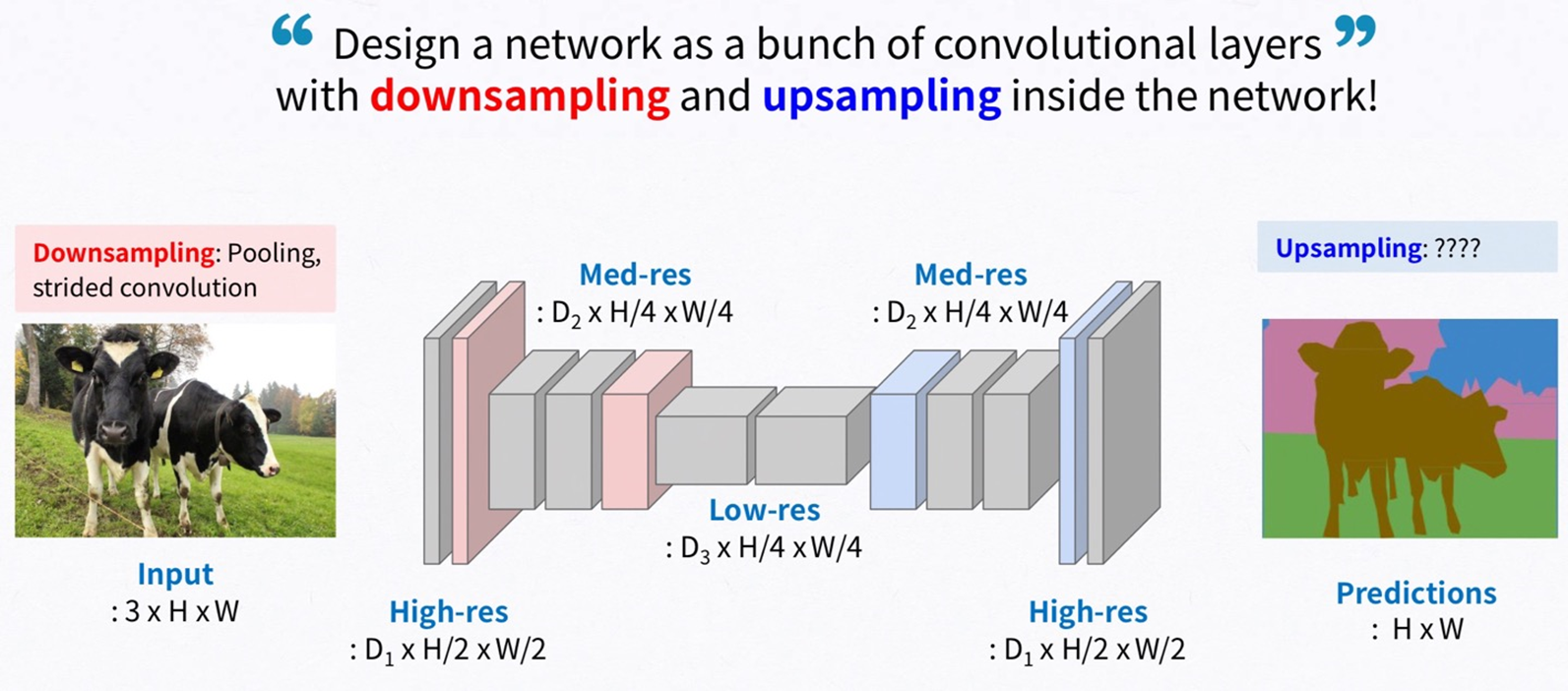
FCN 방법을 이용하며 모든 픽셀에 대해서 한번에 연산이 가능하지만 고해상도의 원본 이미지에 대해서는 연산량이 많아지게 됩니다. 이 문제를 해결하기 위해 FCN과 함께 downsampling과 upsampling을 사용하게 됩니다. 먼저 Downsampling은 흔히 pooling이나 Strided convolution을 사용합니다.
하지만 downsampling으로 감소한 크기를 복원하기 위한 방법 또한 고려해야합니다. 본 논문에서는 기존의 Shift-and-stitch 방법보다 skip connection을 사용한 upsampling이 더 효과적이기 때문에 upsampling을 사용합니다.
입력값이 conv + pooling을 통과하면 크기가 감소합니다. 이를 복원하는 방법으로 shift-and-stich 방법을 사용했습니다. coarse output에서 dense prediction feature를 생성하기 위하여 shift-and-stitch 방법이 고려되었습니다.
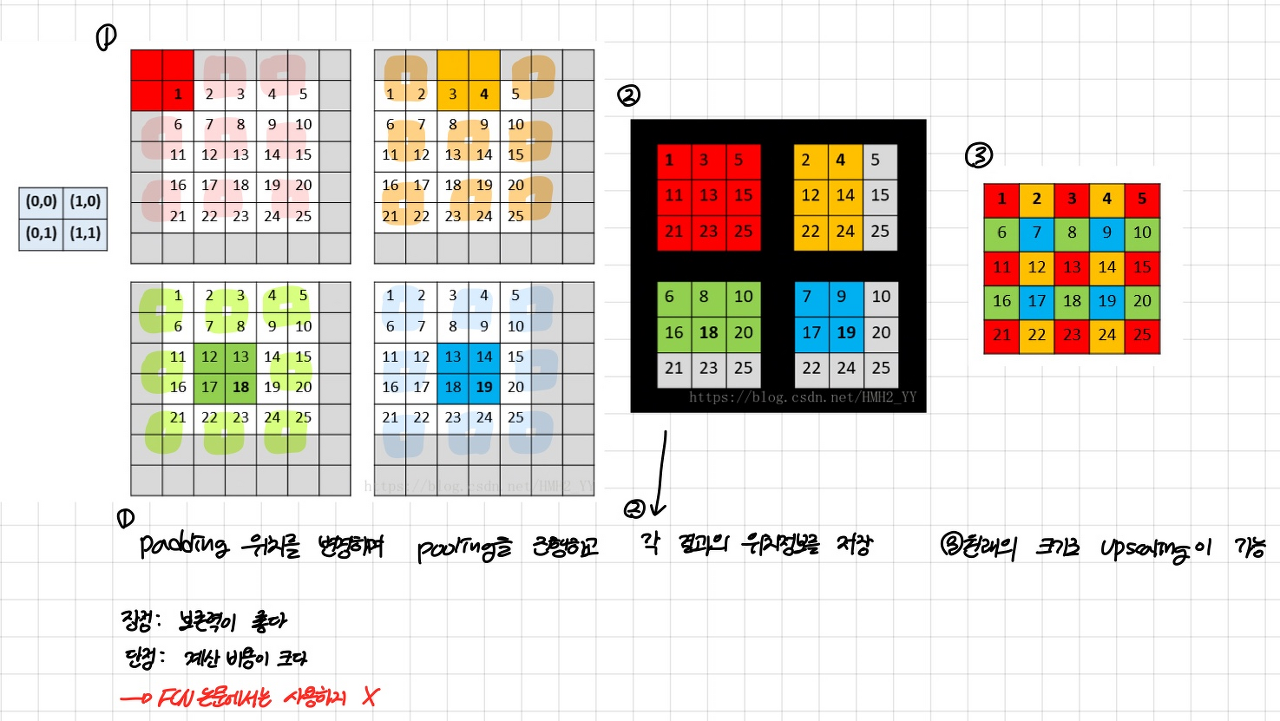
shift-and-stitch 방법은 위와 같이 max pooling을 하고 위치 정보를 저장하여 원래의 이미지 크기로 upscaling할 수 있습니다. 하지만 계산 비용이 크다는 단점이 있습니다.
이 논문에서는 filter와 stride를 조절하여 shift-and-stitch과 유사한 효과를 내는 trick을 언급하였습니다.
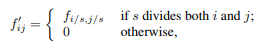
본 논문에서는 skip connection을 사용한 Upsampling 기법이 더 효과적이기 때문에 이 trick을 사용하지 않았습니다.
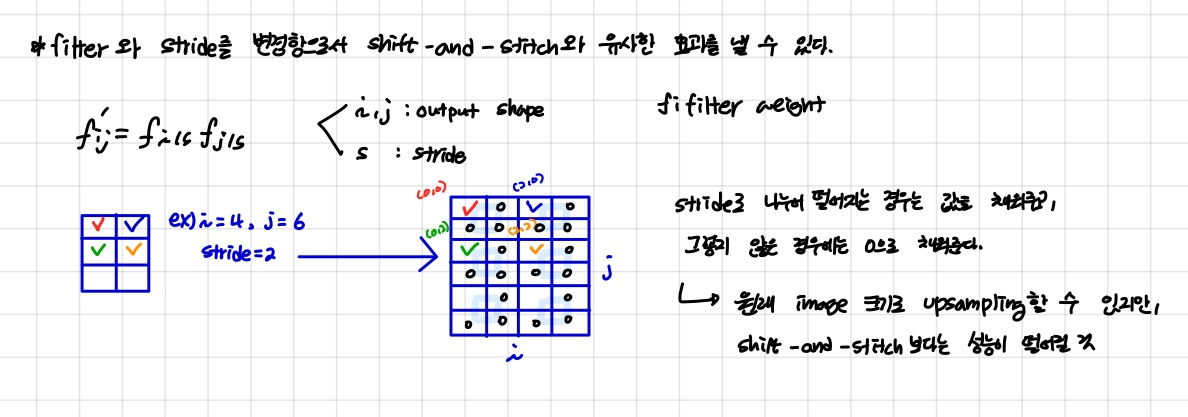
3.3 Upsampling is backwards strided convolution
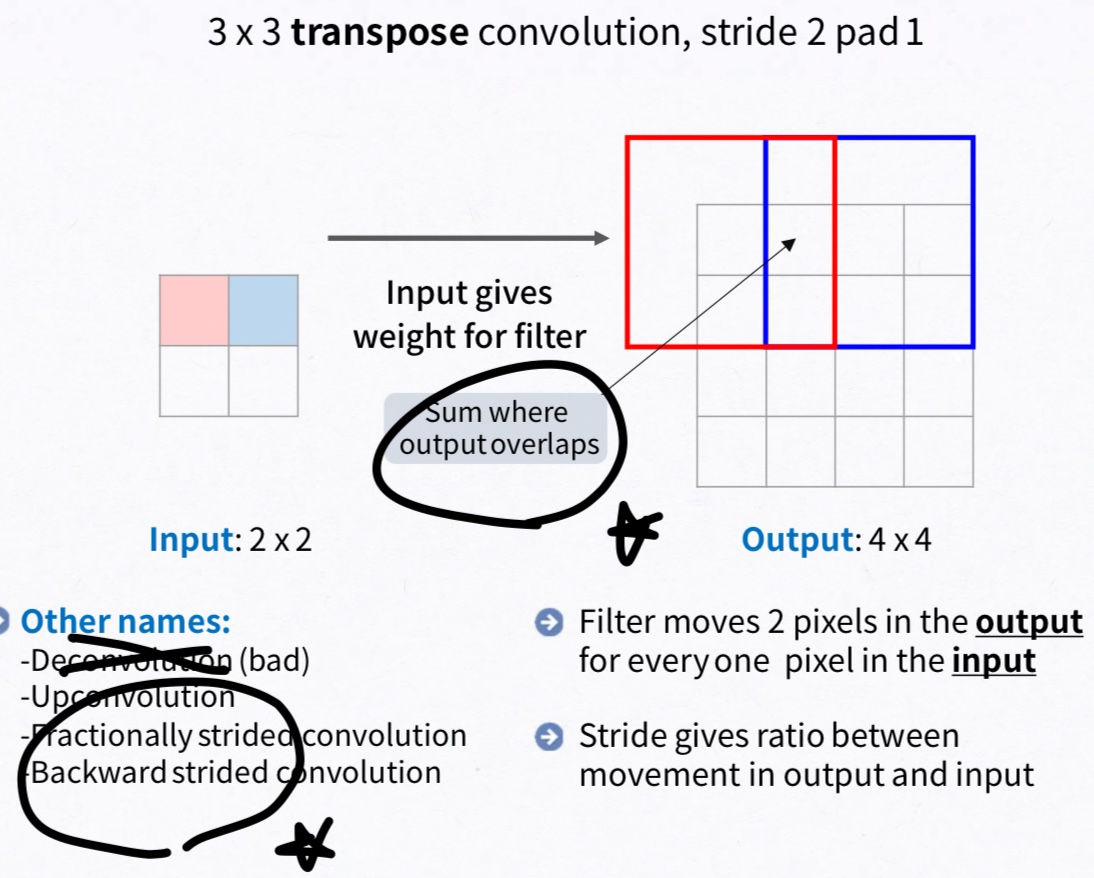
upsampling을 layer를 중심으로 다시 설명하면 coarse한 결과 이미지를 dense하게 픽셀을 채우는 것입니다. 이를 위한 대표적인 방법으로는 보간법(interpolation)입니다. 예를 들어 bilinear interpolation 같은 경우에는 ij에서 4개의 맞닿는 픽셀을 사용해서 보간을 할 수 있습니다.
본 논문에서는 backward convolution(deconvolution, transposed convolution)이라고 불리는 학습 기반 upsampling을 적용하였습니다. 이렇게 backward convolution과 activation function을 연결하여 nonlinear upsampling을 학습하게 됩니다.
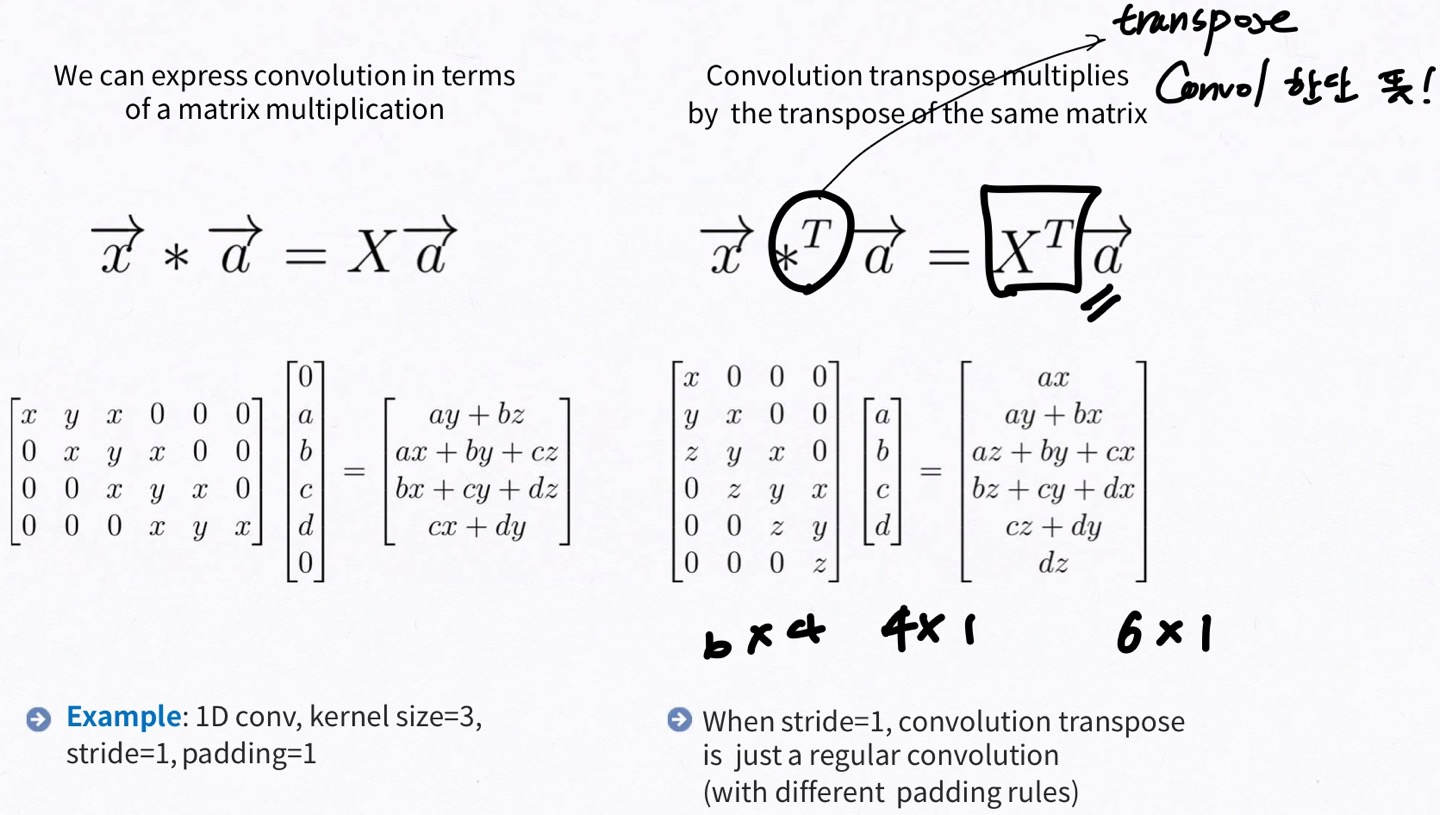
왼쪽 행렬 x, y, z이므로 혼동이 없으시길 바랍니다! 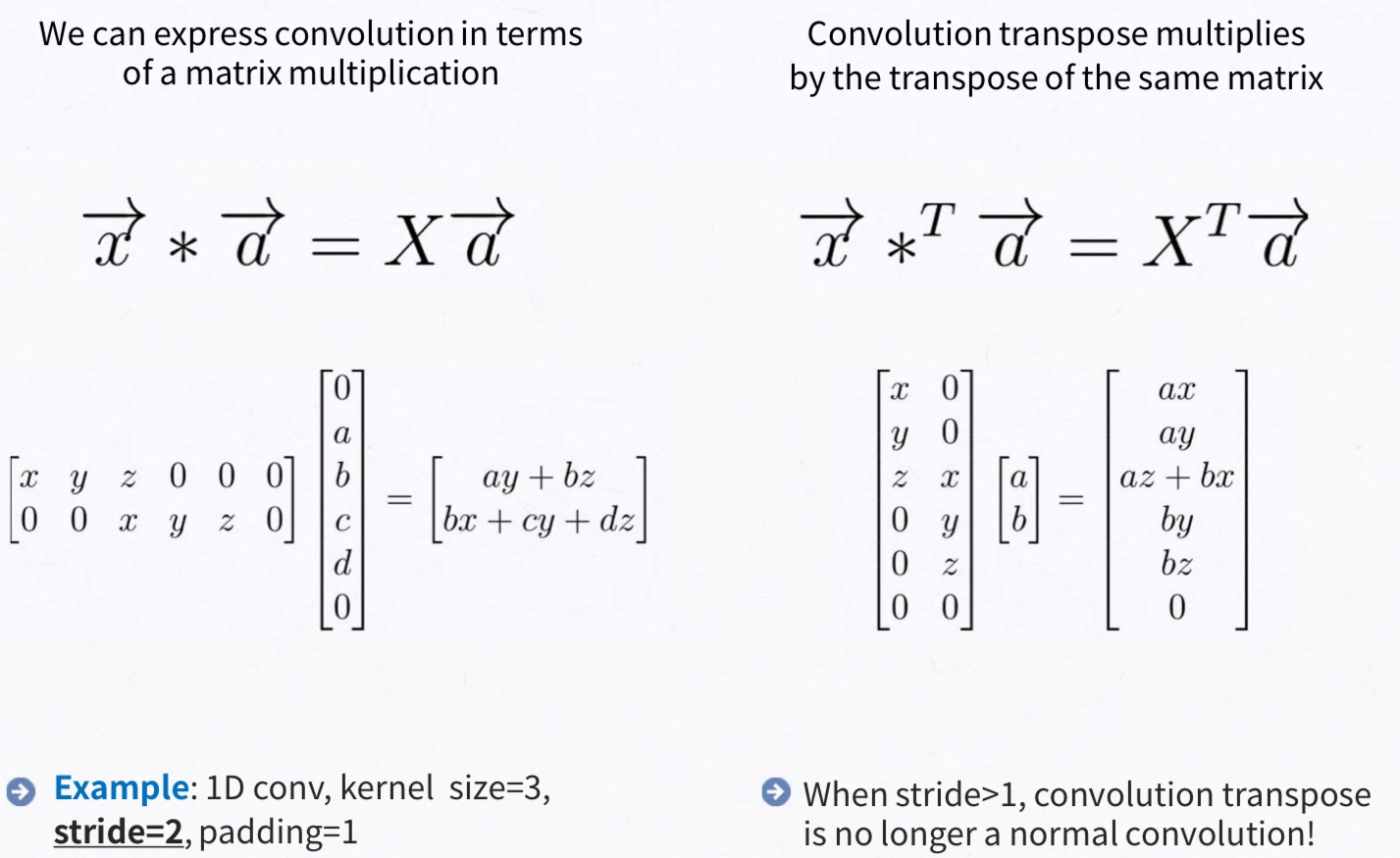
=> 이해가 안되어서 블로그 참고
https://realblack0.github.io/2020/05/11/transpose-convolution.html
CS231n의 Transposed Convolution은 Deconvolution에 가까운 Transposed Convolution이다
일러두기 본 게시글은 Transposed Convolution에 대하여 개인적으로 공부한 내용을 정리한 것입니다. Transposed Convolution의 다른 이름들이 붙은 이유는 제가 고민해서 도출한 추론이므로 사실과 다를 수
realblack0.github.io
3.4 Patchwise training is loss sampling
그 다음으로 본 논문에서는 patchwise training이라는 개념을 언급합니다. patchwise training이란 모델을 training 할 때 전체 이미지를 넣는 것이 아니라 객체의 주변을 분리한 서브 이미지 즉 patch image를 사용하는 방법을 의미합니다.
patchwise training을 통해 하나의 이미지를 100개의 patch로 분할해 각 patch마다의 loss 값을 구하게 됩니다. 이 때, 모든 loss를 사용하는 것이 아니라 중요한 patch들의 loss만 사용하거나 가중치를 주어 loss 값을 샘플링해 사용할 수 있다고 합니다. 이는 class imbalance 문제를 완화할 수 있지만 공간적 상관 관계가 부족해진다는 단점이 있습니다.
여기서 이미지의 부분을 학습하는 patch training과 전체 이미지를 학습하는 fully convolution training은 서로 동일하다고 설명하고 있습니다. 또한 본 논문에서는 fully convolution training이 더 계산적으로 유리하다고 언급하였습니다.
4. Segmentation Architecture
define “ a skip architecture ” that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations
4.1. From classifier to dense FCN
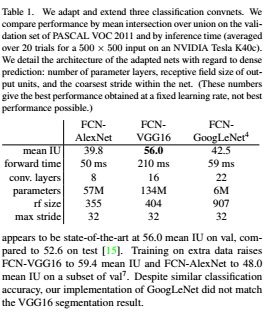
본 논문에서 말하는 FCN을 만들기 위해서 사용한 네트워크는 AlexNet, VGG16, GoogLeNet를 사용하였습니다. 이 네트워크들을 1절에서 언급한 convolutionalization 과정을 통해서 전부 FCN으로 만들게 됩니다. 이 과정에서 이전에 언급했다 시피 1×11×1 convolutional layer를 사용하였습니다. 그리고 PASCAL 데이터셋의 클래스가 21개(배경을 포함)이기 때문에 원래 Fully connected layer였던 부분은 21개의 채널을 가지는 layer로 바뀌게 됩니다.
성능을 측정한 결과 VGG16에 FCN을 적용했을 때 metric으로 사용한 mean IU가 가장 좋게 나온 것을 알 수 있습니다. 다만 전체적으로 봤을 때 성능이 좋지 않기 때문에 skip architecture를 도입하게 됩니다.
4.2. Combining what and where
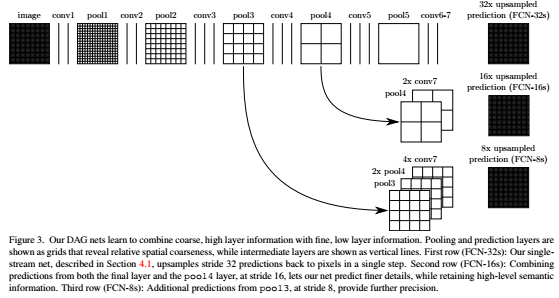
먼저, FCN-16은 pool4 layer에서 1×11×1 합성곱 layer를 적용하고, 마지막 layer에서 x2 upsampling을 한 뒤에 합칩니다. 마지막 layer에서 x32배 upsampling을 하지 않고 x16배 upsampling하면 입력 이미지의 크기와 동일한 출력 이미지를 얻을 수 있습니다. 그리고 FCN-8은 FCN-16에서 x16배 upsampling하기 전 결과에서 x2 upsampling을 한 뒤에 pool3 layer에 1×11×1 합성곱 layer를 적용하여 하나로 합칩니다. 그리고 x8배 upsampling을 하게 되는 것입니다. 위의 과정에서 단순히 마지막 layer에서 x32배 upsampling을 한 것은 FCN-32라고 하겠습니다. 각각의 skip architecture의 결과를 시각화하여 확인해보겠습니다.

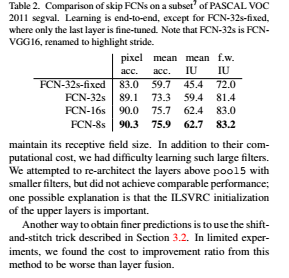
위 그림을 보면 상위 layer에서 skip connection을 할 수록 결과 mask의 detail이 점점 좋아지는 것을 볼 수 있습니다. 그런데 이는 어떻게 보면 당연한 결과인데 FCN-32의 경우를 생각해보면 한번에 x32배의 upsampling을 하게 되면 엄청나게 많은 정보량이 손실될 것입니다. 따라서 이 정보량 손실을 막기 위해서 fine layer에서 coarse layer로의 skip connection을 적용하게 되면 더 좋은 성능을 얻을 수 있는 것입니다.
4.3. Experimental framework
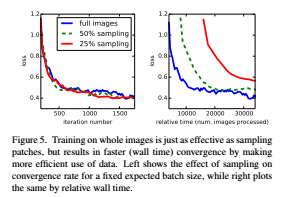
5. Results
: 우리의 FCN skip architecture를 semantic segmentation과 scene parsing에 대해서 평가
Semantic Segmentation은 각각의 픽셀에 대하여 알려진 객체에 한하여 카테고리화 하는 것을 말합니다.
반면 Scene Parsing의 경우 이미지 내의 모든 픽셀에 대하여 카테고리화 하는 것을 뜻합니다. 즉, Scence Parsing 작업을 하였을 때, 이미지의 모든 픽셀을 대상으로 정보값이 있어야 합니다.※ Metrics
: region intersection over union = IU
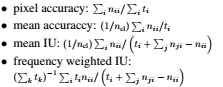
n_cl : the number of classes
t_i : the total number of pixels in class i
n_ij : the number of pixels of class i predicted to belong to class j. So for class i:
n_ii : the number of correctly classified pixels (true positives)
n_ij : the number of pixels wrongly classified (false positives)
n_ji : the number of pixels wrongly not classifed (false negatives)
Pixel Accuracy : 클래스 i 전체 픽셀 중 prediction 성공한 픽셀 수
Mean Accuracy : 전체 클래스에 대한 Pixel Accuracy 평균
Mean IU : (전체 픽셀과 예측 실패 픽셀-예측성공 픽셀의 합에서 예측 성공 픽셀 합 = IOU) 의 평균
Mean IU = true positive / (true positive + false positive + false negative)
Frequency Weighted IU : unbalanced, similar to pixel accuracy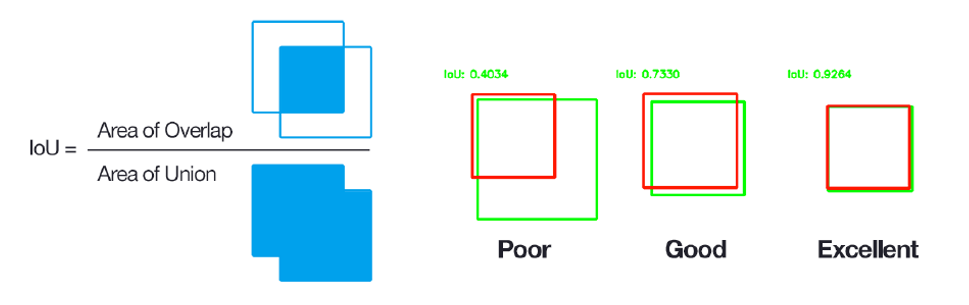
※ IoU (Intersection over Union)
Jaccard index 라고도하는 IoU (Intersection over Union) metric은 기본적으로 target 과 prediction 간의 percent overlap 을 정량화하는 방법입니다.
IoU 메트릭은 target 과 prediction 사이의 공통 픽셀 수를 총 픽셀 수로 나눈 값을 측정합니다.IU는 Intersection over Union의 약자로 특정 색상에서의 실제 블록과 예측 블록 간의 합집합 영역 대비 교집합 영역의 비율입니다. MeanIU는 색상별로 구한 IU의 평균값을 취한 것입니다.
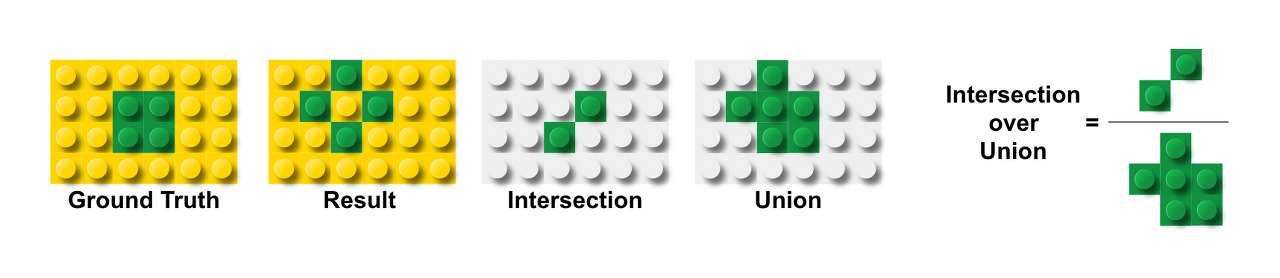
Mean IU = (녹색 블록 IU + 노란색 블록 IU) / 2
※ Datasets
: dataset으로는 PASCAL VOC, NYUDv2, SIFT Flow을 사용했다!
1) PASCAL VOC
:We achieve the best results on mean IU by a relative margin of 20%

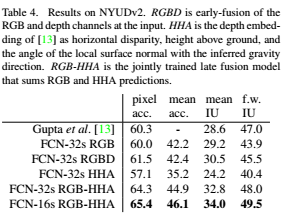
2) NYUDv2
: NYUDv2은 RGB-D dataset으로, RGBD란 early-fusion of theRGB and depth channels at the input!
: HHA = the depth embedding of as horizontal disparity, height above ground, and the angle of the local surface normal with the inferred gravity direction
: RGB-HHA = the jointly trained late fusion model that sums RGB and HHA predictions
3) SIFT Flow
: a dataset of 2,688 images with pixel labels for 33 semantic categories (“bridge”, “mountain”, “sun”), as well as three geometric categories (“horizontal”, “vertical”, and “sky”)
Tighe = a non-parametric transfer method
: Tighe 1 is an exemplar SVM
: Tighe 2 is SVM + MRF
Pinheiro = a multi-scale, recurrent convnet, denoted RCNN

6. Conclusions
1. Fully Convolutional Networks 모델은 단지 modern classification convnets 중 특별한 케이스로, 많은 class를 가지고 있는 classification 모델과 다름 없다.
[Fully convolutional networks are a rich class of models, of which modern classification convnets are a special case]
2. 이렇게 classification 문제를 segmentation 문제로 확장하고, multi-resolution layer combinations의 구조로 변화하여( 앞서 deep, coarse + shallow, fine 합친 구조 의미), SOTA를 달성함과 동시에 문제를 단순화하고 속도를 올렸다!
[Recognizing this, extending these classification nets to segmentation, and improving the architecture with multi-resolution layer combinations dramatically improves the state-of-the-art, while simultaneously simplifying and speeding up learning and inference. ]
Reference
(FCN) Fully Convolutional Networks for Semantic Segmentation 리뷰
이제서야 Segmentation에 대한 논문 리뷰를 쓰는 것 같다. 특히, Segmentation에 대해 자세히 알기 위해선 아주 기본이 되는 Paper중에 하나이지 않을까? 인용이 20000회나 되는 대단한 Paper이다. Class를 분
velog.io
https://deep-learning-study.tistory.com/562
[논문 읽기] FCN(2015) 리뷰, Fully Convolutional Networks for Semantic Segmentation
공부 목적으로 FCN 논문을 읽어보았습니다. Abstract FCN은 end-to-end, pixels-to-pixels 학습이 되는 convolutional network입니다. 핵심 아이디어는 임의의 크기로 입력 값을 받고, 그에 해당하는 출력값을..
deep-learning-study.tistory.com
https://everyday-image-processing.tistory.com/32
논문 함께 읽기[3].Fully Convolutional Networks for Semantic Segmentation
안녕하세요. 오늘은 2015년에 나온 FCN이라는 약어로 유명한 Fully Convolutional Networks for Semantic Segmentation을 보도록 하겠습니다. 논문 출처 : https://people.eecs.berkeley.edu/~jonlong/long_shelha..
everyday-image-processing.tistory.com
https://89douner.tistory.com/296
2. FCN
안녕하세요. 이번 글에서는 처음으로 딥러닝을 적용한 segmentation 모델인 FCN에 대해서 소개해드리려고 합니다. Conference: CVPR 2015 (논문은 2014년에 나옴) Paper title: Fully Convolutional Networks for..
89douner.tistory.com
https://jlog1016.tistory.com/84
[Paper Review]FCN 논문 리뷰 - Fully Convolutional Networks for Semantic Segmentation
PAPER 요약 CNN은 image recognition에 큰 발전을 가지고 왔다. semantic segmentation에도 CNN Deep learning model을 사용하기 위한 방법으로 FCN의 방법을 제시했다. Network for Classification 일반적으로 Co..
jlog1016.tistory.com
https://realblack0.github.io/2020/05/11/transpose-convolution.html
CS231n의 Transposed Convolution은 Deconvolution에 가까운 Transposed Convolution이다
일러두기 본 게시글은 Transposed Convolution에 대하여 개인적으로 공부한 내용을 정리한 것입니다. Transposed Convolution의 다른 이름들이 붙은 이유는 제가 고민해서 도출한 추론이므로 사실과 다를 수
realblack0.github.io
728x90'AI > Computer Vision' 카테고리의 다른 글