-
[Story Generation Study Week 06 : Text Generation with muti-modal data] Hide-and-Tell: Learning to Bridge Photo Streams for Visual Storytelling (AAAI, 2020) 리뷰AI/NLP 2022. 8. 16. 21:07728x90
[Story Generation Study Week 06 : Text Generation with muti-modal data]
Hide-and-Tell: Learning to Bridge Photo Streams for Visual Storytelling (AAAI, 2020) 리뷰벌써 6주차라니 ,,
곧 개강이라니 ,,

울고 싶네여 오늘의 발표 세 줄 요약 : 숨기고, 상상하고, 말하라
1. Visual Storytelling은 입력된 사진의 연속열을 보고 단순한 설명 이상의, 사진 간의 상황과 의미를 공유하여 묘사하는 것
2. 본 논문에서는 입력 사진들 중 무작위로 마스킹하고, 이렇게 누락된 사진의 의미를 유추해 나가는 방식으로 학습하고자 함 → Hiding step + Imagining Step + Telling step + Decoder = Hide and tell Model !
3. Baseline 성능 능가했고, SOTA도 달성했다 늘 그렇듯이

애기들의 숨바꼭질
Abstract & Introduction
Visual Storytelling이란 ?
- 사진 스트림( == 연속된 사진 여러 장 )을 기반으로 단편소설을 만드는 작업
- (기존의 시각적 캡션과 달리) 스토리텔링은 사실적인 설명뿐만 아니라 인간과 같은 내레이션과 의미론도 포함하는 것
- 기존의 시각적 캡션은 시각적으로 근거가 있다
- Visual Storytelling은 사진 스트림에 걸친 상황 흐름과 전반적인 상황을 묘사하려고 시도 -> 현재 이미지에 나타나지 않는 객체에 대한 단어를 포함할 수 있음 => 이것이 인간의 시각과 언어적 능력에 더 가까워지는 길이다 !


시각적 캡션의 경우, 두번째 사진만을 보고 '노란 수트를 입고 있는 중년의 남성'이라고 하겠지만, 우리는 앞뒤 상황들을 알고 있기에 김두한이 미군과 협상 중인 것을 알 수 있다 Visual Storytelling의 주요 Challenges
- 사진 사이의 시각적 격차를 서술적 스토리와 상상적 스토리로 메우는 것

사진이 숨겨졌음에도 불구하고, 우리의 예측 문장 (d)는 "게임은 매우 강렬했다"는 의미론적으로 자연스럽고 전체 스토리 맥락에서 그럴듯하다. 본 논문의 Contributions
- 시각적 격차를 해소하는 줄거리를 상상력을 학습하는 데 효과적인 방법 제시!
- 훈련 중 입력 스택에서 하나 이상의 사진이 무작위로 누락되고, 누락된 사진이 있더라도 완전한 그럴듯한 이야기를 생성하도록 네트워크를 훈련하도록 함
- 사진 스트림 전반에 걸쳐 nonlocal relations를 학습하고 기존의 RNN 기반 모델을 개선하는 hide-and-tell model 제안 !
- 기존의 RNN 기반 baseline의 성능을 능가 + SOTA 달성
- 네트워크가 손상된 입력 사진 스트림으로도 스토리라인을 충실하게 완성하고 사진 간 이야기를 예측할 수 있음
Proposed Approach
본 논문의 Approach 요약
- 훈련 과정에서 입력된 사진 연속열 중 하나 이상, 무작위로 마스킹
- 훈련 초반에는 다 넣고, 훈련 중에 이미지 드롭 수를 점점 늘려가는 curriculum learning 적용 !
- 사진 스트림 전반에 걸쳐 nonlocal relations를 학습하고 기존의 RNN 기반 모델을 개선하는 hide-and-tell model
- 사진이 누락된 모든 사진 슬롯 간의 상황 관계 학습에 중점
- RNN 블록 뒤에 비 로컬(NL) 레이어를 추가하여 사진 스트림 간의 long-range 상관 관계를 개선할 것을 제안
- 첫 번째 CNN 블록과 두 개의 RNN-NL 블록의 스택으로 설계되었으며, GRU을 통해 최종 스토리라인을 출력
Input과 Output
- 입력 이미지 I = {I1, I2, I3, I4, I5}
- 해당 문장 S = {s1, s2, s3, s5}
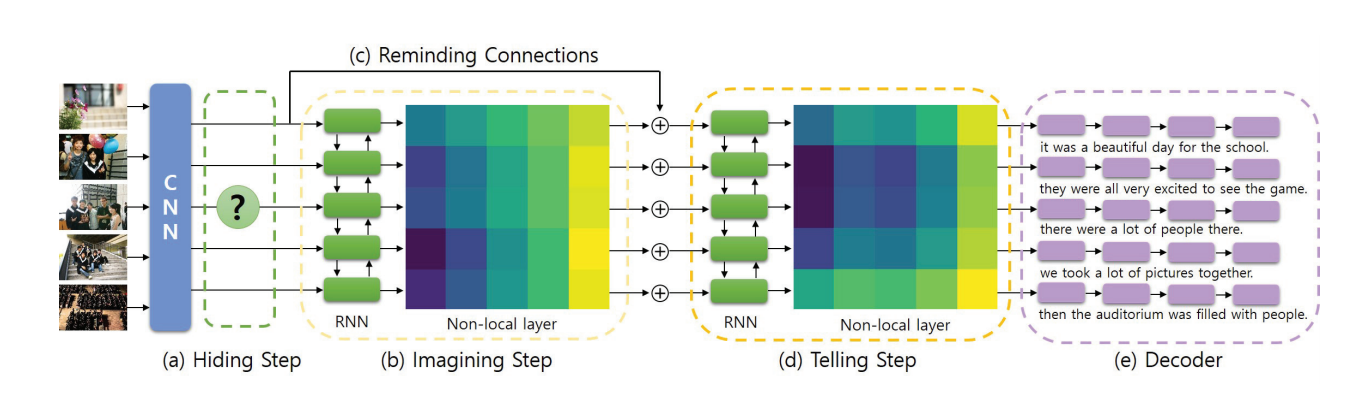
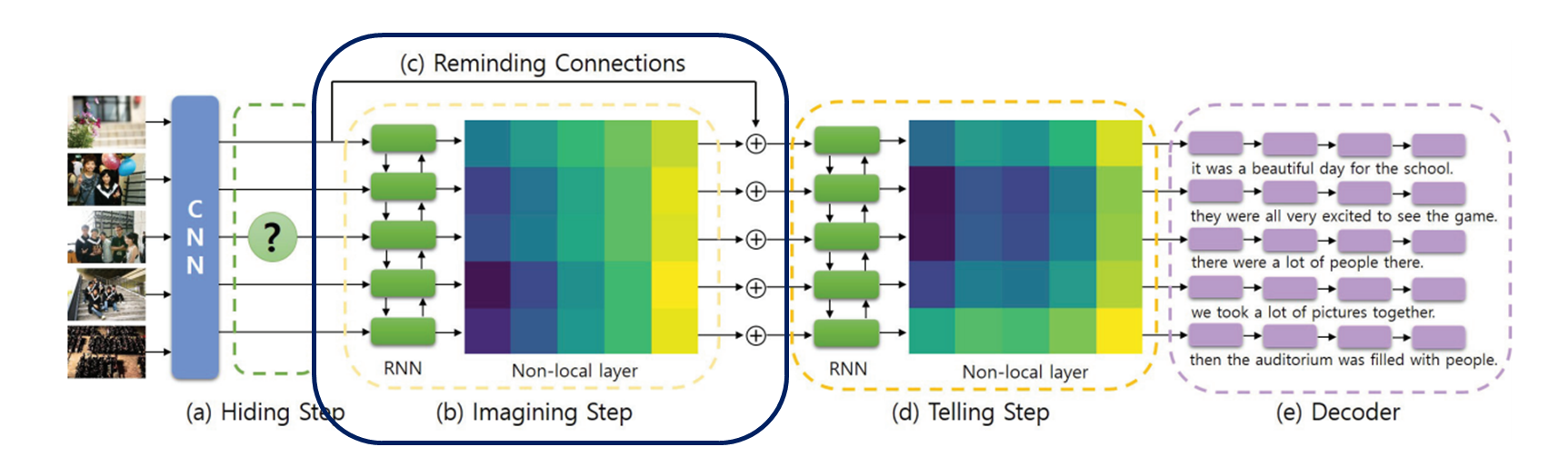
구조
(A) Hiding Step : 입력된 사진 연속열에서 이미지를 생략 (숨기는 이미지 0개에서 점차 증가시킴 / 2개까지만 )
(B) Imagining Step : 사진 간 관계를 연관시켜 숨겨진 이미지의 특징을 대략적으로 예측 (사라진 이미지 특징 파악)
(C) Telling Step : 이전 이미지 단계에서 특징 스택을 가져와서 사진 스트림 전체에서 보다 구체적인 의미 포착하기 위함
(D) Decoder : 문장 생성
(A) Hiding Step

- input : I = {I1, I2, I3, I4, I5}
- output :

- 입력된 사진의 연속열 {I1, I2, I3, I4, I5}를 Pretrained된 CNN layer 통과시킴
- 이 과정 중에서 각 사진들의 feature인 F = {f1, f2, f3, f4, f5}이 나오는데 Hidden layer에서 1~2개를 무작위로 드롭시킴
- 이렇게 드롭하는 방식으로 정규화 효과도 있을 뿐더러, 상황적 관계를 잘 학습하도록 한다
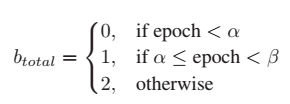
Curriculum Learning (B) Imagining Step
- input :
- Bi-GRU + 1D 컨볼루션 기반 nonlocal layer
1. GRU : 순방향 ( −→h1, ···, −→h5) / 역방향 ( ←− h1, ···, ←− h5)

X = GRU의 hidden state / W는 1D Conv 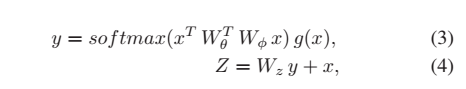
2. 이미지 간의 non local relation을 모델링하기 위해서 Gaussian version of a non-local neural network 사용 !
- 각 입력 이미지 feature을 하나의 요소로 간주하고 사진 스트림 간의 관계에 초점을 맞춘다
3. Reminding Connection을 통해, F_blind를 추가하여 손실된 정보 보완하고자 함
(C) Telling Step
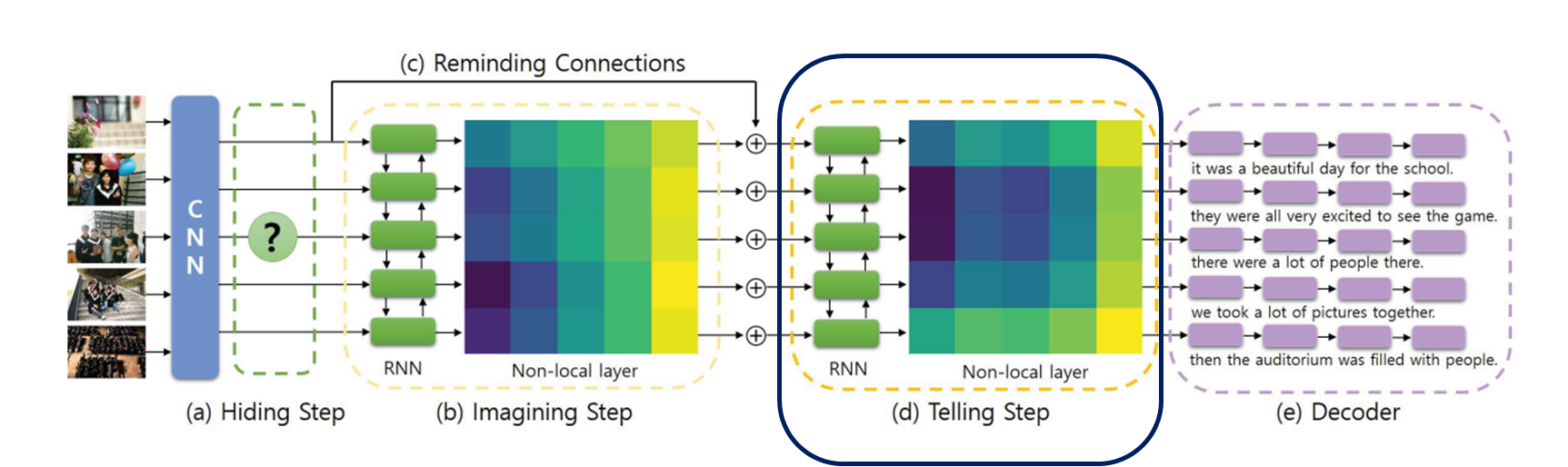
- 첫번째 블록 (Imagining step)과 똑같은 RNN-NL 블록을 가지지만, 가중치 파라미터는 공유하지 않음
- 첫번째 블록 (Imagining step)에서 가려진 이미지에 대한 특징을 대략적으로 예측했다면, 여기서는 구체적이고 개연성 있는 묘사가 되도록 feature를 개선한다
(D) Decoder

- 입력 사진마다 S = {s1, s2, s3, s4, s5} 문장을 생성
- 각 문장 S마다 단어 W = {w1, w2, · · ·, wT} 집합을 예측하는데, 다음과 같이 원핫 벡터 vt을 통해 예측한다

Experiments
Data
- VIST Dataset 사용
- 앨범에서 선택한 5개의 입력 이미지가 주어지고, 사용자가 주석을 단 해당 5개의 문장이 ground truth
- train : 4,098 / validation : 4,988 / test : 5,050.

https://visionandlanguage.net/VIST/
VIST: Visual Storytelling Dataset
What is VIST? (SIND v.2) We introduce the first dataset for sequential vision-to-language, and explore how this data may be used for the task of visual storytelling. The dataset includes 81,743 unique photos in 20,211 sequences, aligned to descriptive and
visionandlanguage.net
Metrics
: story generation task에서 으레 사용하는 그것들 사용
- BLEU
- ROUGE-L
- CIDEr
- METEOR
+) human-subjective studies
Quantitative Results
1. Ablation Study
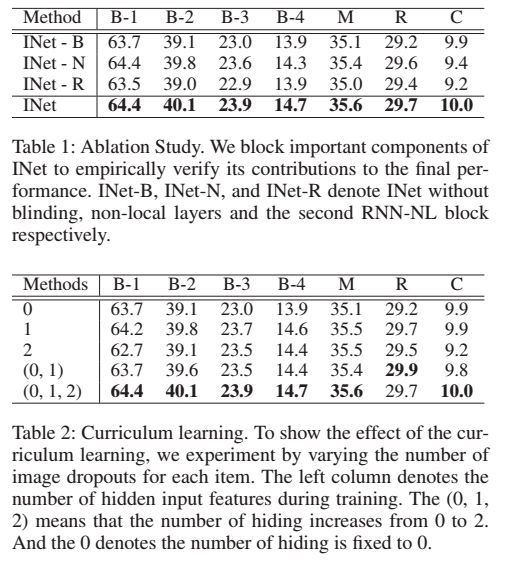
- INet-B : hiding step 삭제 / 즉 input 사진 그대로 들어감 / 정규화 효과 잃음 -> 과적합되기 때문
- INet-N : nonlocal layer 삭제 / 프레임 간 관계를 포착하기 위해 반복 신경망(RNN)에만 의존해야 함 / non-local 관계의 보완 효과 잃음
- INet-R : telling step 삭제 / 더 구체적인 설명하기에는 불충분해짐 / imagination step 이후에 한번 더 정제가 필요함을 뜻함
=> 모든 ablation setup들에서 성능 저하가 관찰됨 !
2. Comparsion to Existing Methods
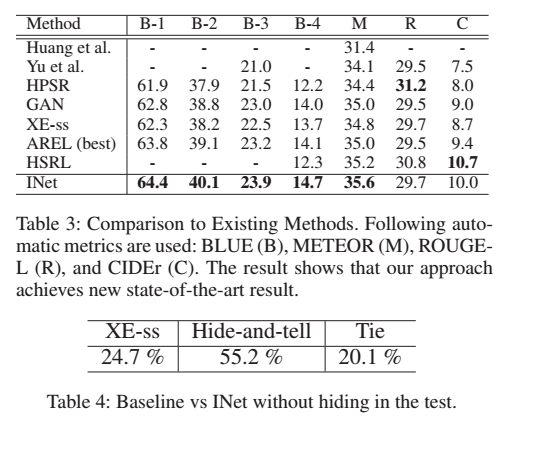
- 우리의 접근 방식은 BLEU 및 METEOR 메트릭에서 SOTA를 달성
- 이전의 접근 방식에 비해, 우리의 접근 방식은 복잡한 문장을 더 잘 처리할 수 있음
- 하지만 이 metrics들은 narrative story generation에 더욱 적합하기 때문에, 우리 task에서 완벽히 맞다고 볼 순 없다
=> 그래서 user study 진행
- 우리의 접근 방식이 baseline를 크게 능가한다
- 우리의 방법이 훨씬 더 인간과 유사한 내레이션을 생성한다는 것을 의미
Qualitative Results
1. Non-hiding Test
- 사진 아예 안 가리고 !

- Baseline : 반복되는 문장 (예: "꽃이 너무 아름다웠다")
- Ours : 매우 다양한 문장 (예: "꽃 중 일부는 매우 화려했다", "꽃이 피었다")
- Baseline : "사람이 많았다"
- Ours : "거기에는 다양한 종류의 상점들이 있었다"
- Baseline : "음식이 많았다" 와 같은 반복적인 표현
- Ours : "음식", "재료", "고기"와 같은 다양한 설명을 생성
2. Hiding Test
- 중간에 사진 하나 가리고 !

- Baseline : "졸업장과 가족들이 그곳에 있었다." / "하루 종일 졸업장" -> 말도 안되는 문장
- Ours : "졸업식은 매우 재미있었다" / "식 후 학생들은 사진을 위해 포즈를 취했다."
=> 전체적인 일관성을 잘 유지할 뿐만 아니라 이웃 문장들과 더 지역적으로 일치한다
3. Story Interpolation
- 주어진 사진 스트림 사이의 문장을 예측하여 스토리를 보간하는 것을 목표로 한다!
- 사진 스트림은 일시적으로 이미지가 희박하기 때문에 현재 시각적 스토리텔링 작업은 표현력이 제한적
- 제안된 스토리 보간 작업은 전체 스토리를 더 구체적으로 만들 수 있다!

- 생성된 문장 4번째 : "할로윈 파티는 끝났다."
=> 전체적인 상황(즉, 할로윈 파티)과 '[남성]이 즐거운 시간을 보냈다(즉, 파티가 끝났다)'는 지역적 맥락 모두 잘 포함
- 결과 : 전체 상황에 대한 전체적인 맥락과 인접 문장과의 지역적인 맥락 모두 잘 유지되더라 ~
Conclusions
hide-and-tell model = hiding block + imagining block + decoder
- input hiding block에서 입력된 사진 연속열에서 이미지를 생략한다
- 그런 다음 imagining block 에서 RNN + 1D 컨볼루션 기반 nonlocal layer를 통해, 사진 간 관계를 연관시켜 숨겨진 이미지의 특징을 예측한다
- decoder에서 문장을 생성한다

1. 방법이 굉장히 간단한데? 정량적인 평가 지표가 맞지 않는다고 했는데도 꽤 준수한 성능인 듯
2. 읽었던 story generation 논문 중에서 가장 쉽고 흥미로웠다
3. KAIST, 삼성,,,, 반갑구려
728x90'AI > NLP' 카테고리의 다른 글