-
[2023 Spring NLP Seminar] On Transferability of Prompt Tuning for Natural Language Processing (NAACL 2022)AI/NLP 2023. 5. 10. 11:07728x90
[2023 Spring NLP Seminar ]
On Transferability of Prompt Tuning for Natural Language Processing
(NAACL 2022)Abstract + Introduction

기존 연구 동향:
- 기존의 pre-trained language models (PLMs)은 파라미터 수가 매우 많아서 fine-tuning에는 많은 계산 자원과 시간이 필요했다.
- 이러한 문제를 해결하기 위해 Prompt Tuning (PT)이라는 새로운 방법이 제안되었다.
- PT는 매우 큰 PLMs를 활용하여 매우 적은 수의 소프트 프롬프트(prompt)만을 조정하여 전체 파라미터 fine-tuning 수행 결과와 비교 가능한 성능을 달성하는 방법이다.
기존 연구들의 한계:
- 다만 PT는 fine-tuning에 비해 훨씬 더 많은 학습 시간이 필요하다.
- 이러한 문제를 해결하기 위해 지식 전이(knowledge transfer)가 효과적인 방법일 수 있다.
- 이에 따라, 본 연구는 prompt transfer가 PT의 효율성 향상에 기여할 수 있는지 조사한다.
제안방법:
- 본 연구에서는 서로 다른 downstream tasks 및 PLMs 간의 prompt 전이의 전이성(transferability)을 실험적으로 조사했다.
- 실험 결과,
- (1) zero-shot 세팅에서, 학습된 소프트 프롬프트는 동일한 PLM에서 유사한 작업에 효과적으로 전이될 뿐 아니라, 유사한 작업에 대한 교차 모델(projector)로 학습된 전이된 prompt를 사용하여 다른 PLMs로도 효과적으로 전이됨을 발견했다.
- (2) 초기화로 사용될 때, 유사한 작업의 학습된 소프트 프롬프트 및 다른 PLMs의 전이된 프롬프트는 학습을 크게 가속화하고 PT의 성능을 향상시킬 수 있음을 보였다.
Contribution :
- 본 연구에서는 prompt 전이가 PT의 효율성 향상에 기여할 수 있는 가능성을 보여준다.
- 또한, prompt 전이성을 결정하는 여러 가지 지표를 조사하여 활성화된 뉴런의 중첩 비율이 전이성을 강력하게 반영한다는 것을 발견하여 프롬프트가 PLMs를 자극하는 방식이 중요하다는 것을 시사한다.
- 이러한 발견은 prompt 전이가 PT에서의 성능을 향상시키는 데 유용하며, 더 많은 연구는 prompt가 PLMs를 자극하는 방식에 초점을 둘 필요가 있다는 것을 보여준다.
Prompt Tuning이란 ?
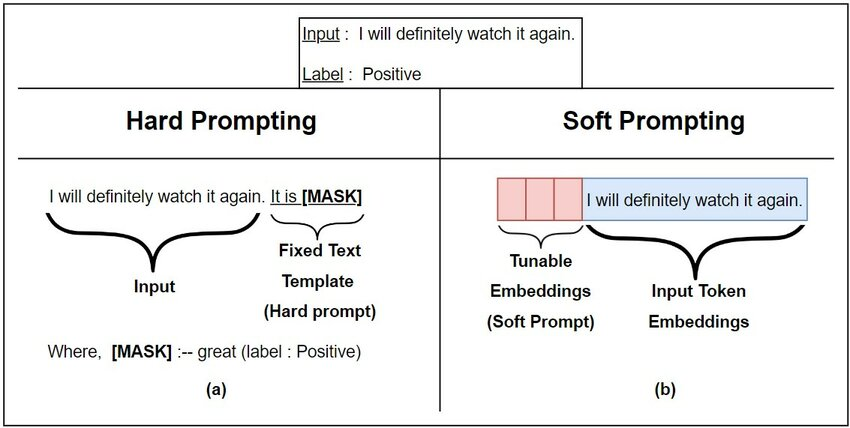
- Hard Prompt
- 입력 시퀀스에 대한 출력을 결정하는 특정한 토큰 시퀀스
- 하드 프롬프트를 사용하면 PLM은 입력 시퀀스에서 특정한 토큰을 생성하여 원하는 출력을 얻을 수 있음
- 이러한 방법은 fine-tuning에 매우 적합하지만, 작은 데이터셋에서는 오버피팅이 발생할 가능성이 높다
- verbalizer가 필수적으로 따라붙어야 하는데, verbalizer setting에 따라 성능이 크게 바뀜
- Soft Prompt
- 입력 시퀀스에 대한 출력 확률 분포를 조정하는 작은 벡터
- LM의 출력 분포를 조정하여 특정 작업에 대한 최적의 출력 분포를 유도
- 이러한 벡터는 학습 가능한 파라미터로 초기화되며, 작은 데이터셋에서 더 나은 성능을 발휘
- GPT3의 prompting에서 영감을 받아 prefix-tuning 제시
- GPT3의 prompting e.g. 다음을 번역하라 대신 vector 형태의 prefix 제시
- 소프트 프롬프트는 작은 데이터셋에서 더 나은 일반화 성능을 발휘
둘 다 프롬프트(prompt)를 사용하여 pre-trained language models (PLMs)를 조정하는 방법
요 두 개를 결합하여 성능을 내는 경우도 있다 (PPT: Pre-trained Prompt Tuning for Few-shot Learning)
소프트 프롬프트(soft prompt)를 사용하는 방법에는 몇 가지가 있습니다. 그 중 일부는 다음과 같습니다:
1. Prompt Tuning: Prompt Tuning은 작은 데이터셋에서도 pre-trained model을 효과적으로 fine-tuning하는 데 사용되는 방법입니다. Prompt Tuning은 미리 학습된 모델의 출력을 조정하기 위해 소프트 프롬프트를 사용합니다.
2.Prefix Tuning: Prefix Tuning은 Prompt Tuning과 유사하지만, 입력 시퀀스의 접두사(prefix)를 조정하는 데 사용합니다. 이를 통해, 작은 데이터셋에서 PLM의 일반화 성능을 향상시킬 수 있습니다.
3. Adapter: Adapter는 소프트 프롬프트를 사용하여 기존 모델의 일부를 재사용하는 방법입니다. Adapter는 모델의 일부 매개 변수를 추가하여 학습하고, 해당 매개 변수만을 fine-tuning하여 전체 모델을 업데이트합니다. 이를 통해, 기존 모델에서 일부만 변경하여 새로운 작업에 적용할 수 있습니다.
4. Few-Shot Learning with Language Models: Few-Shot Learning with Language Models는 작은 데이터셋에서도 pre-trained model을 fine-tuning하는 데 사용되는 방법입니다. 이 방법은 소프트 프롬프트를 사용하여 적은 수의 샘플을 이용하여 모델을 fine-tuning합니다.
이러한 방법은 모두 소프트 프롬프트를 사용하여 pre-trained model을 효과적으로 활용하는 방법 중 하나입니다.- 이 중에서 Prompt tuning에 집중하자면,
- 소프트 프롬프트(soft prompt)를 이용하여 작은 데이터셋에서도 PLM을 fine-tuning 없이 높은 성능을 발휘할 수 있도록 함
- soft prompt라고 하는 learnable virtual token을 input sequence 앞에 붙이는 것
- 일반적으로 기존의 pre-trained model에서 소프트 프롬프트를 초기화하여 사용
- 이 방법은 사전 학습된 모델의 일부를 재사용하여 매개 변수를 절약
- Prompt tuning은 zero-shot, few-shot 및 full-shot 방식으로 작동
- 하지만, fine-tuning보다 convergence가 느리다
- 이를 해결하기 위해 knowledge transfer => Prompt Transfer

- prompt tuning을 formal하게 써보면 다음과 같음:
input sequence
soft prompts
,- soft prompts 를 input sequence 앞에다 갖다 붙이는 것, 단 embedding dimension 가 갖게끔
- training objective: 아래 likelihood 을 maximize하는 것
L=p(y∣P,x1,...,xn)
- 원래 나와야 할 output 가 나올 확률을 높이는 방향으로 학습이 되어야 함: RoBERTa 같은 경우는 MLM이므로 soft prompts 앞에 [MASK] 붙여서 soft prompts + PLM이 [MASK] == 를 채우도록 soft prompts를 학습시킴
Methods
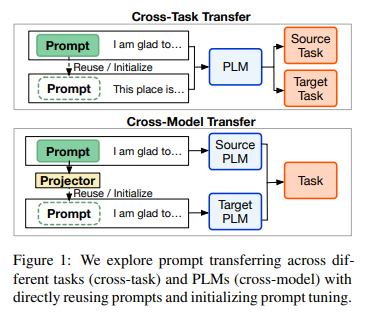
- task 간 transfer
- NLP task 6가지
- 모델 간 transfer
- RoBerta <-> T5
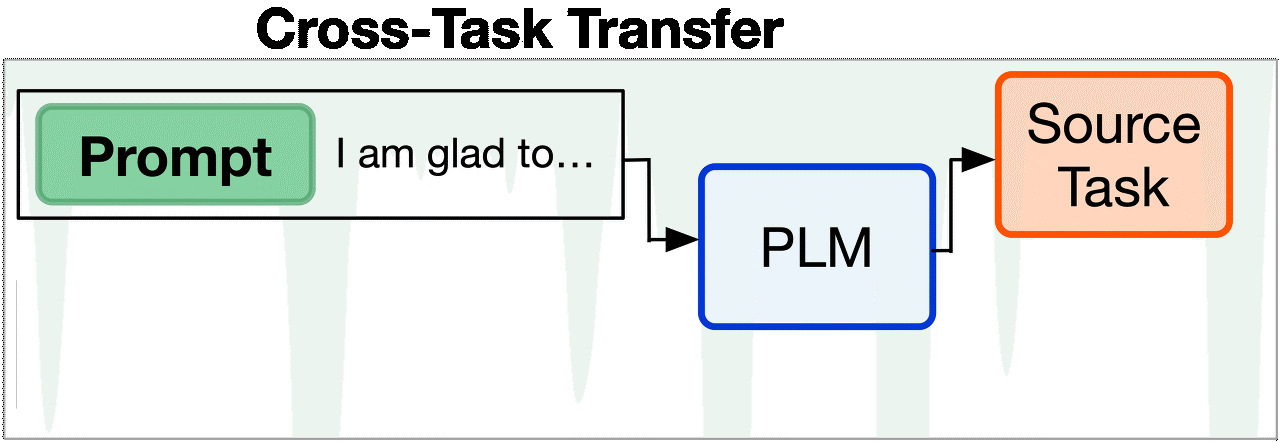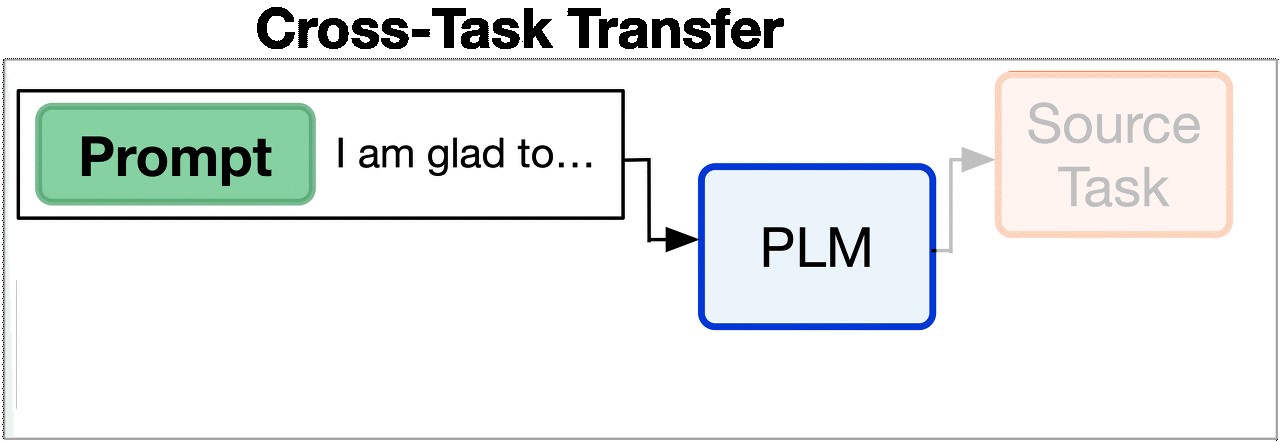
1. Cross Task Transfer
- cross-task 에서 (4.1) zero shot setting에서 prompt transferability를 확인해보고, (4.2) prompt tuning with transfer의 effectiveness와 efficiency를 확인
- 결과 random initialization부터 시작한 soft prompts와 성능이 비슷하거나 더 좋았고, training time도 더 적었다 / soft prompts는 추가학습 없이도 비슷한 task면 그대로 갖다 쓸 수 있다.

2. Cross Model Transfer
- cross-model transfer의 궁극적 목표는 small PLM에서 large PLM으로 soft prompts를 옮길 수 있을지에 대한 해답을 구하는 것: 그래서 source model은 small PLM인 RoBERTa고, target model은 large PLM인 T5임
- 4 cross-task transfer처럼 soft prompt를 그대로 쓸 수 없음: PLM이 학습된 방식이 다르기 때문에 embedding space, weight 모두 다를 것임
- 그래서 prompt projection을 이용
- 두 가지 learning objectives를 사용: distance minimizing, task tuning
- source PLM의 soft prompts (은 soft prompts의 length)
target PLM의 soft prompts (은 soft prompts의 length)
training objective: 와 의 difference를 minimize
- source PLM의 soft prompts (은 soft prompts의 length)
- 두 가지 learning objectives를 사용: distance minimizing, task tuning
- 그래서 prompt projection을 이용
- 결과 task tuning은 비슷한 type tasks에서 unseen task라 하더라도 generalize됨: cross model prompt transfer 가능할 듯 / 모델이 달라도 prompt projector가 있으면 이미 학습된 soft prompts를 사용할 수 있다.
On Transferability of Prompt Tuning for Natural Language Processing (NAACL 2022)
Prompt Tuning의 장점?: PLM의 parameter를 다 학습할 필요 없이 소수의 parameter만 학습시켜도 괜찮은 성능을 내기 때문에!Prompt Tuning의 단점?: 학습되는 parameter가 너무 적죠? 그래서 convergence 오래 걸리죠?
velog.io
https://github.com/thunlp/Prompt-Transferability
GitHub - thunlp/Prompt-Transferability: On Transferability of Prompt Tuning for Natural Language Processing
On Transferability of Prompt Tuning for Natural Language Processing - GitHub - thunlp/Prompt-Transferability: On Transferability of Prompt Tuning for Natural Language Processing
github.com
728x90'AI > NLP' 카테고리의 다른 글