-
[ASR Study] wav2vec: Unsupervised pre-training for speech recognition (Interspeech, 2019)AI/Speech 2024. 1. 13. 16:08728x90
[ASR Study] wav2vec: Unsupervised pre-training for speech recognition (Interspeech, 2019)

word2vec과 비슷한 본 모델의 이름에서 느낌이 오듯이, 임베딩을 잘 뽑기 위한 모델이라 생각하면 되겠다
Introduction
- 기존 연구들과 그 한계
- 현재 ASR SOTA 모델들은 대량의 transcribed audio data가 필요하다
- 하지만, labeled data는 부족
- 현재 ASR SOTA 모델들은 대량의 transcribed audio data가 필요하다
- Key Idea
- 데이터 양이 충분할 때, general representation을 학습하는 것 (=pretraining)
- 데이터 양이 부족할 때, downstream task에 대한 성능을 높이는 것 (=fine-tuning)
- Unsupervised Learning in the Other Domains
- CV
- COCO, ImageNet 데이터로 학습된 representation, 다른 task 수행하는 모델을 initialize할 때 효과적
- NLP
- BERT, GPT 등의 LM도 unsupervised pretraining을 통해 여러 task에서 좋은 성능 보임
- Speech Processing
- Speech Data에 대한 unsupervised learning은 수행되었지만, 그 결과로 얻어진 표현들이 지도 학습을 통한 음성 인식 개선에는 적용되지 않았음
- CV
- In this Paper,
- 목표
- Unsupervised Learning(=wav2vec)을 통해 Supervised Speech Recognition의 성능을 향상시키는 것 !
- Model Architecture
- Raw Audio를 입력으로 하고 이를 통해 General Representation을 생성해내는 CNN 기반의 모델
- Objective
- Contrastive Loss을 통해 Negative sample 사이에서 positive sample을 뽑는 방식으로, 앞으로 올 오디오 데이터를 예측하는 방식 사용
- 목표
Pretraining Approch
- Contrastive Predictive Coding이 처음 등장한 논문은 따로 있음 (논문)
- 음성으로부터 좋은 Representation Vector를 추출하는 모델 개발
- 일반적으로 음성데이터에서 주요한 정보는 High-Level 정보를 의미 (High-Level 정보는 음성 전반적으로 공유되는 정보)
- 공유벡터를 활용하여 일정 거리에 위치한 특징벡터를 예측하게 모델링함
- 모델이 공유벡터에 공유정보를 추출하게 하고, 거리와 관련된 패턴을 학습
- 거리벡터는 거리에 따른 정보의 변화를 학습 & 과거의 특징벡터에 공통적으로 들어있는 정보로 미래 특징벡터 예측
- 장점
- 음성 데이터만으로 음성 안에 공유정보를 추출할 수 있는 방법 제시
- 음성뿐만 아니라 다양한 Task에 해당 방법론을 적용
- 단점
- (속도) Aggregator가 RNN 계열이기 때문에 병렬처리가 안됨
- (성능) 음성 Task에서 다소 아쉬운 성능을 보였음
- (실험) 음성만 다룬 논문이 아니므로 음성관련 실험 내용이 부족함
- 음성으로부터 좋은 Representation Vector를 추출하는 모델 개발

- Wav2vec : 음성에 CPC를 적용하는 방법을 전문적으로 다룬 논문
- (속도) 병렬처리가 가능하도록 CNN 계열 아키텍처로 변경
- (성능) Acoustic Model과 Language Model를 함께 적용하여 성능을 향상시킴
- (실험) 음성에 Self-supervised 적용한 다양한 실험을 표기.

1. Model Architecture
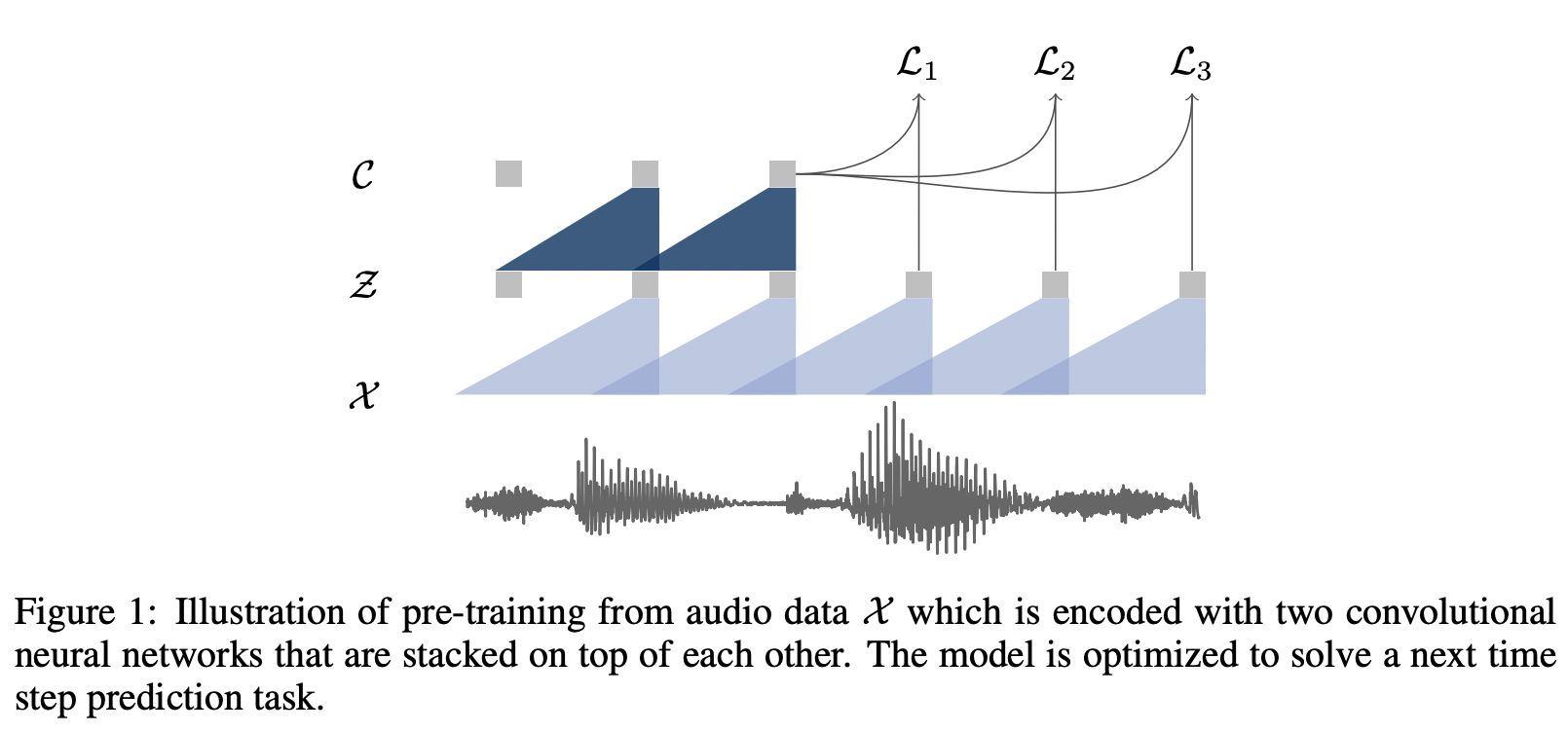
음성 인식에서는 보통 밀리세컨드(ms) 단위의 굉장히 짧은 시간으로 프레임 나눔
- Encoder Network
- 음성 입력을 hidden representaion로 인코딩하는 역할을 수행
- 5 CNN layer / kernel size (10,8,4,4,4) / stride (5,4,2,2,2)
- input :
- 16kHz 샘플링 레이트 기준으로 30ms정도의 오디오가 들어가면
- output :
- 10ms 마다 stride 옮겨가며 representation z_i 생성
- Context Network g : Z↦C
- Hidden Representation를 context representation로 변환
- 학습을 마치면 이 Context Representation을 해당 음성의 피처로 사용
- 9 CNN layer / kernel size 3 / stride 1
- output :
- 210 ms의 receptive field를 가짐
- 각각
- causal convolution
- 512 channel
- group normalization + ReLU


causal convolution과 본 논문에서의 예상? 구조 2. Objective : Contrastive Predictive Coding
- 해당 입력이 포지티브 쌍인지 네거티브 쌍인지 이진 분류(binary classification)하는 과정
- 포지티브 쌍
- 입력 음성의 i번째 context representation Z_i 와 i+1번째 hidden representaion Z_i+1
- 네거티브 쌍
- 입력 음성의 i번째 context representation Z_i와 현재 배치의 다른 음성의 hidden representation들 가운데 랜덤으로 추출해서 생성
- 포지티브 쌍
- 학습 진행 시 (loss가 작아질 수록)
- 포지티브 쌍 관계의 represenation은 벡터 공간에서 가까워지고, 네거티브 쌍은 멀어짐


- proposal 분포 에서 추출한 샘플 으로부터 향후 단계의 샘플 를 구별하도록 모델을 훈련
- postive 항:
- 이 항은 z_i+k (특징 벡터)와 h_k (c_i) (컨텍스트 벡터) 사이의 유사성을 측정
- 시그모이드 함수 σ는 이 두 벡터의 내적을 확률적으로 해석하는 데 사용
- 내적이 큰 값이면, 즉 두 벡터가 서로 유사하다고 모델이 판단하면, 시그모이드 함수의 결과는 1에 가까워지고 로그 확률은 0에 가까워져 손실이 감소
- 이는 모델이 정확하게 예측을 하였을 때 낮은 손실 값을 받도록 하여, 모델이 이러한 패턴을 학습하도록 유도
- negative 항:
- 이 항은 모델이 h_k (c_i )와 negative sample인 z ~ 사이의 유사성을 낮게 평가하도록 유도
- negative sample는 같은 음성 샘플에서 샘플링되지만, 현재 컨텍스트와는 관련이 없는 벡터
- 이 항에서 시그모이드 함수에 내적이 음수로 들어가므로,
- 두 벡터 사이의 유사성이 낮을수록 시그모이드 함수의 결과가 0에 가까워지고,
- 로그 확률은 더 낮아져 손실을 감소시킴
- 식 설명
- k
- 얼마나 뒤의 오디오 시그널을 예측할지를 나타내는 변수
- 실제 학습시에는 여러 k를 두고 각 k에 해당하는 손실 함수의 합을 최소화 하는 방향으로 모델을 학습한다.
- Z~
- negative sample
- 이 가운데서 라는 k-step후의 positive sample을 가려내는 것
- 첫번째 항은 z_(i+k)가 positive sample일 확률
- 두번째 항은 z~들이 negative sample일 확률의 기댓값
- 기댓값을 알 수 없기 때문에 negative sample을 10개 추출하여 평균을 구함
- p_n
- Negative sample은 현재 보고 있는 오디오 파일 내에서 추출
- 다른 파일에서 추출하는 경우 결과가 안좋았다고 함
- 추출하는 분포는 uniform random(1/T) 분포이다. (T는 sequence 길이)
- Negative sample은 현재 보고 있는 오디오 파일 내에서 추출
- h
- context time step i 에서의 affine transformation
- Step k마다 한개의 h가 있으며, k 스텝 뒤의 z를 예측하는 데 쓰인다. FC layer 한개라고 생각하면 된다
- λ
- Negative Sample의 개수
- k
이를 통해서 unsupervised learning을 수행했다고 보면 된다
Experiments
- 실험 세팅
- Phoneme Recognition 진행
- Benchmark Dataset : TIMIT / WSJ (16kHz의 샘플링 레이트를 가지고 있는 영어 오디오 데이터)
- 최종 metric은 WER(Word Error Rate)와 LER(Letter Error Rate)을 사용
- Baseline으로는 오디오의 임베딩만 다르게 설정해서 실험 (80 log-mel filterbank coefficient 사용)
- Phoneme Recognition 진행
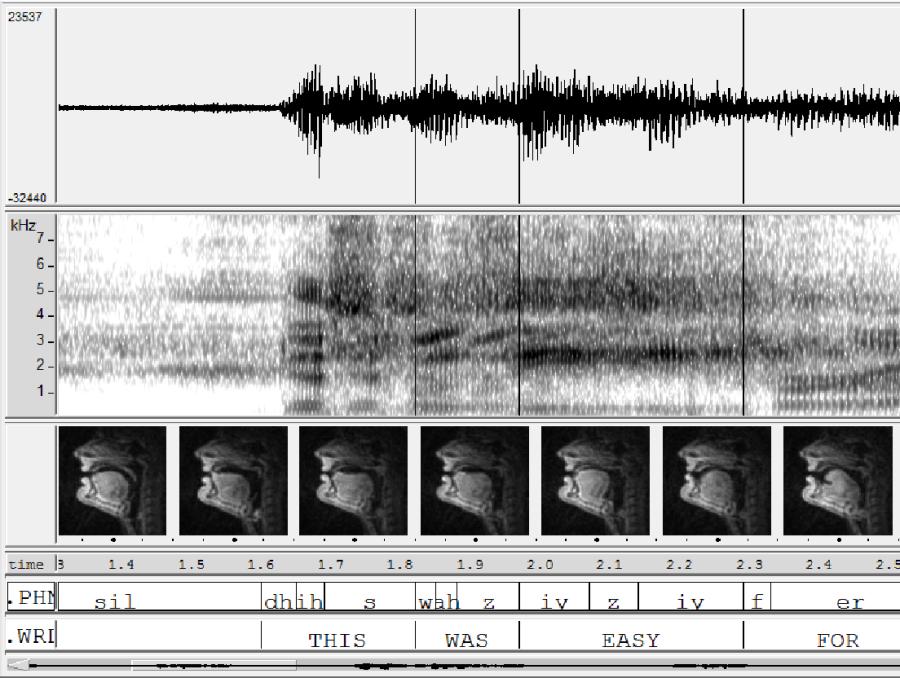
- TIMIT Dataset
- ASR 성능 평가를 위한 데이터셋
- 630 speakers of 8 dialects of American English each reading 10 phonetically-rich sentences
- WSJ0 Dataset
- automatic speech recognition (ASR)을 위한 corpus (1992)
- Wall Street Journal을 소리 내어 읽은 것으로 구성되어져 있고, 16KHz로 녹음됨

- 음성인식의 목적은 입력 waveform sequences를 해당 단어 또는 character sequences에 매핑
- acoustic model과 language model을 뭘 쓸 것이냐?가 asr task에서 달라지는 부분이다
- 아래에서는 wav2vec 성능 비교를 위해 여러 AM과 LM을 사용해서 실험한다
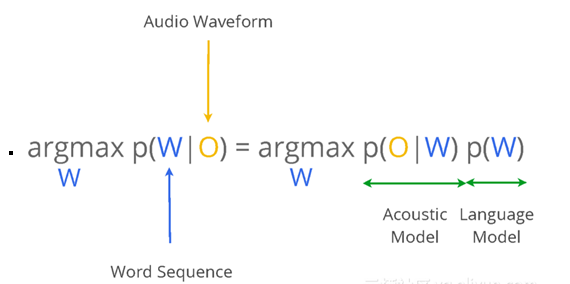
- Acoustic Model (= Downstream Model)
- wav2vec과 Baseline과의 성능 비교를 위해 downstream model로는 wav2letter를 사용
- 아래의 그림과 같이 여러 개의 Conv를 쌓아 만든 구조를 가지고 있다고 하며, 각 benchmark에 따라 다른 설정을 둬서 실험
- TIMIT의 경우에는 CNN 7층, 1000채널, 커널 사이즈 5, PReLU와 droupout 0.7을 사용하여 최종 층에서 39차원짜리 phoneme probability를 반환하는 형태
- WSJ의 경우는 17층의 gated CNN을 사용하였고, 마지막 층에서 31차원의 확률 벡터를 반환
- wav2vec과 Baseline과의 성능 비교를 위해 downstream model로는 wav2letter를 사용

wav2letter model - Language Model (=Decoding model)
- acoustic model에서 나온 결과물을 decoding하기 위해서, WSJ LM 전용 데이터에 대해서만 학습된 별도의 LM + lexicon 사용
- 3가지 모델 사용해서 비교 실험
- a 4-gram KenLM language model
- a word-based convolutional language model
- a character based convolutional language model
- 아래의 식을 최대화하기 위해 Beam search 를 사용하여 context 네트워크 𝑐 또는 log-mel filterbank의 출력에서 단어 시퀀스 𝑦를 디코딩
- π_L은 y의 문자
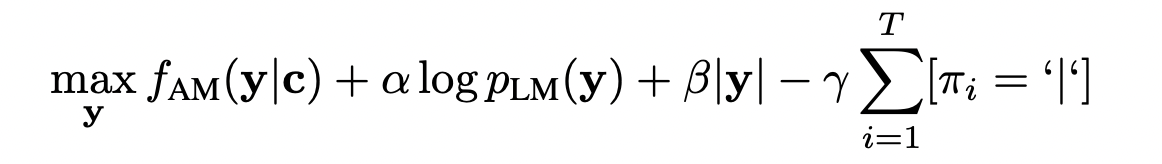
Results
- 위에서 언급했듯, 2가지 Benchmark에 대해서 성능 비교
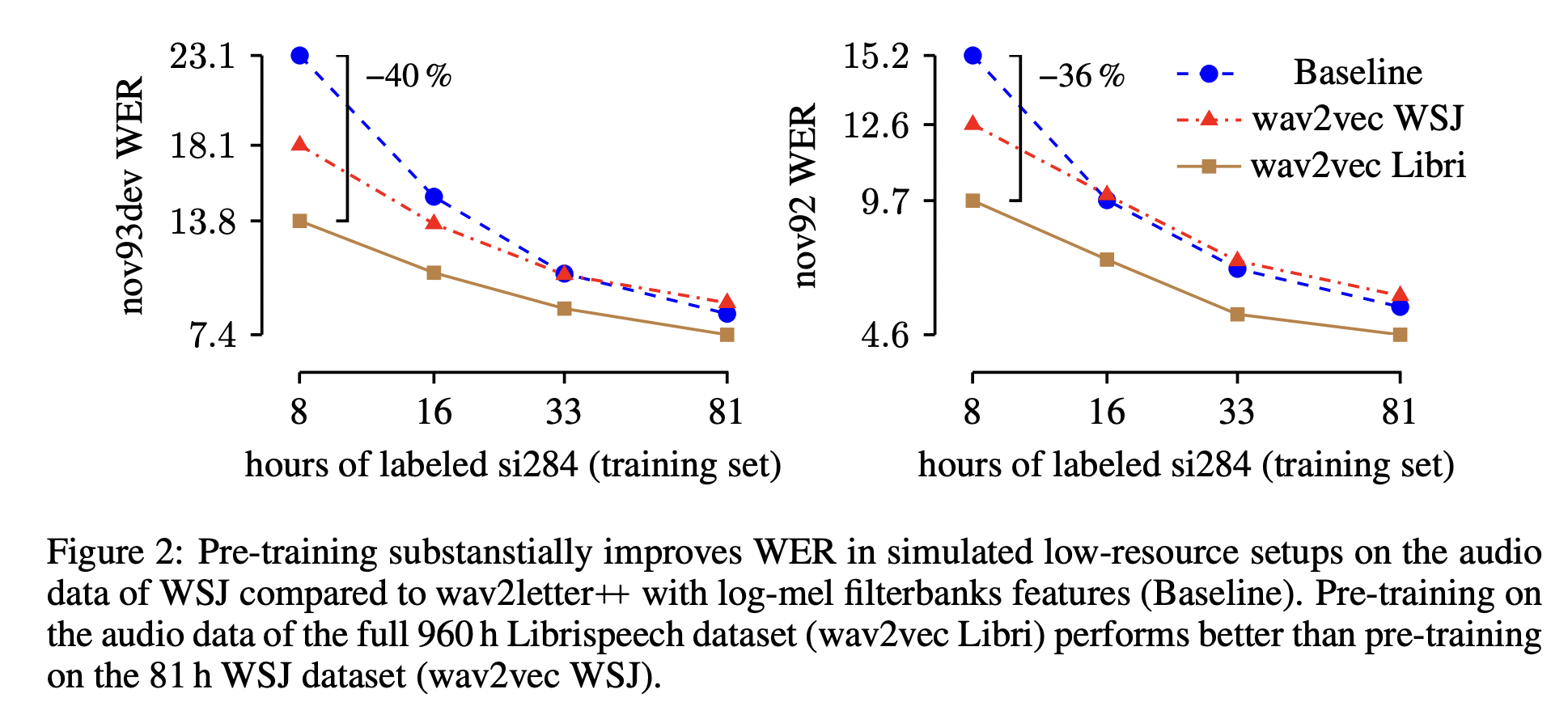
- Pre-training for the WSJ Benchmark
- Pre-training for TIMIT
- Pre-training for the WSJ Benchmark
- Setting
- WSJ의 오디오 데이터 (레이블 X), clean LibriSpeech (80h), 960 LibriSpeech으로 pretraining
- 결과
- 당시 SOTA였던 character-based의 Deep Speech2을 능가하는 성능
- pretrained model에 쓰이는 데이터가 많을수록 성능이 더 잘 나온다
- Setting

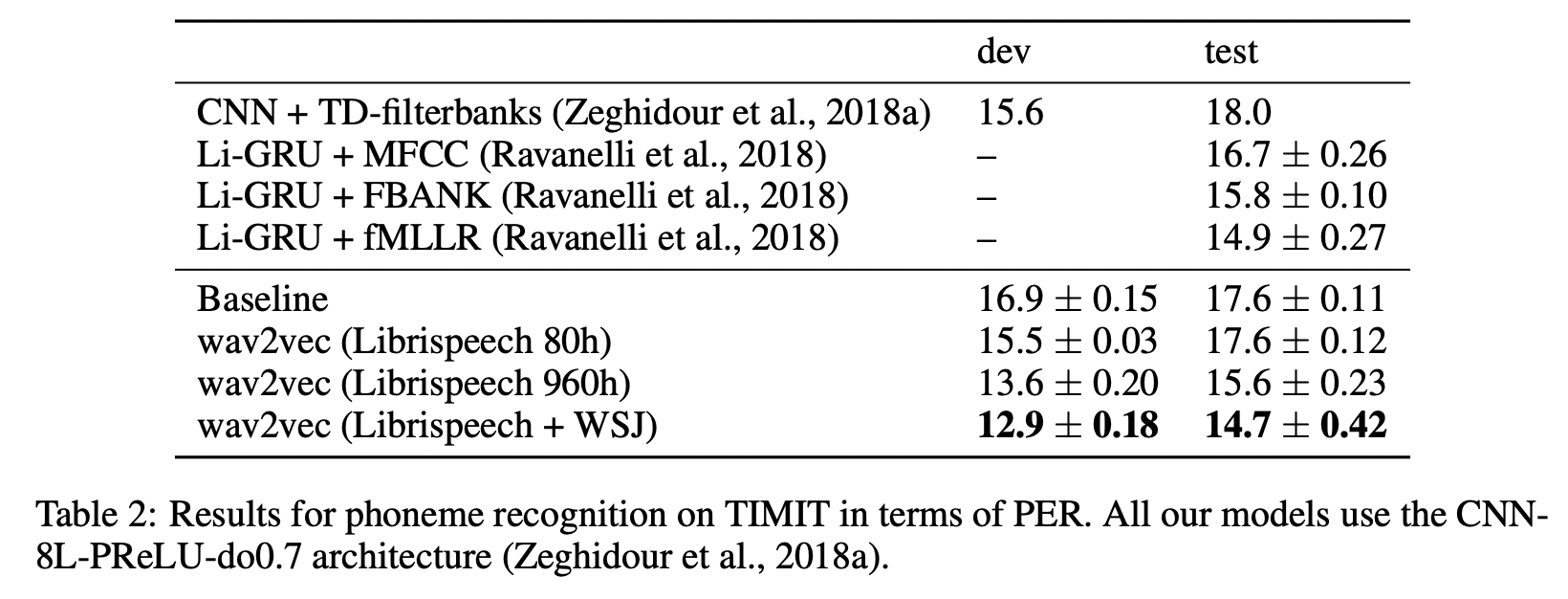
- Pre-training for TIMIT
- setting
- AM: a 7-layer wav2letter++ model with high dropout
- learning rate 0.12, momentum 0.9 and we train for 1,000 epochs on 8 GPUs with a batch size of 16 audio
sequences
- 결과
- Librispeech와 WSJ 조합으로 representation 학습하여 fine-tuning한 모델이 PER에서 가장 좋은 성능을 얻음
- setting
Ablation Study
- 3가지의 ablation study 진행
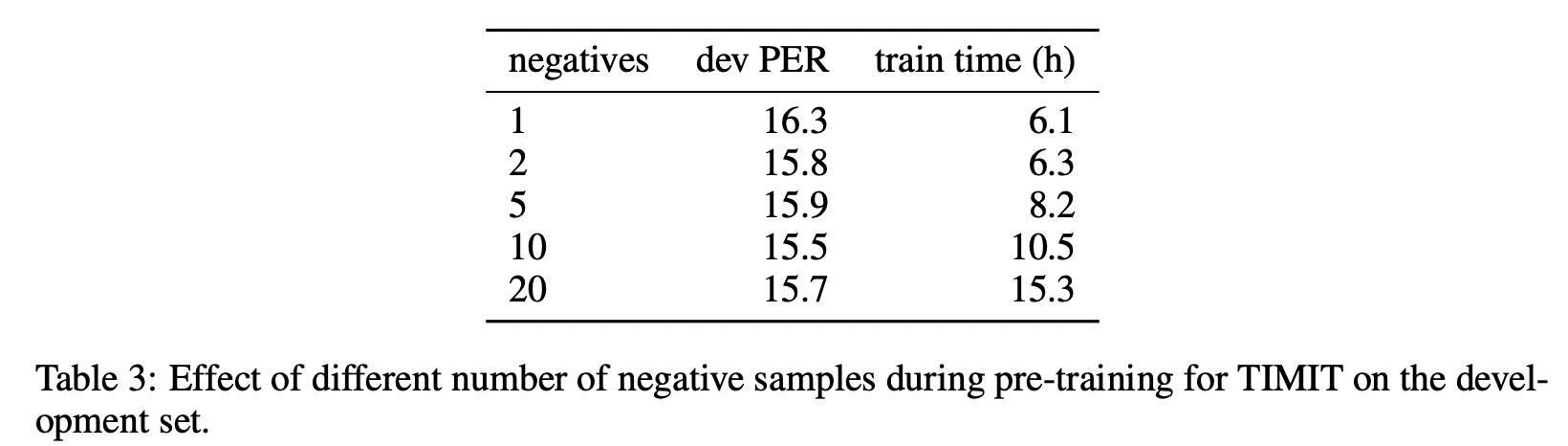
- Negative Sample의 수에 따른 성능 변화
- 오디오 시퀀스 cutting 사이즈 변화에 따른 성능 변화
- 미래 예측 step K에 따른 성능 변화
- LibriSpeech의 80시간 pre-training 버전으로 실험
- Negative Sample의 수에 따른 성능 변화
- Negative 샘플의 수가 늘어날 수록 도움이 되지만, 최대 10개가 한계
- 훈련 시간이 증가될수록 성능이 정체됨
- Negative 샘플의 수가 증가함에 따라 Positive 샘플의 훈련 신호가 감소하기 때문
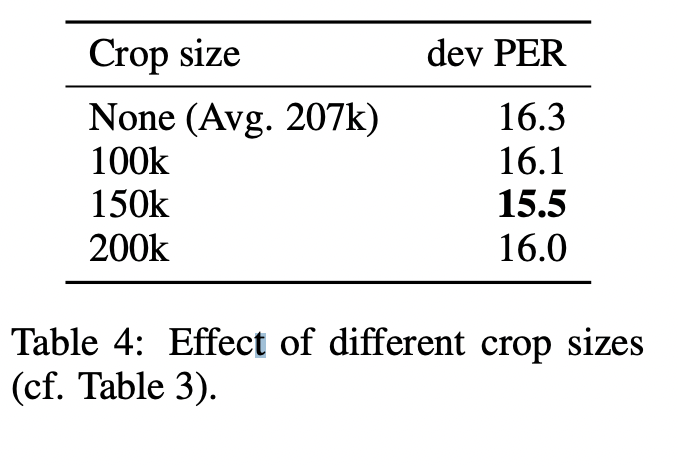
- 오디오 시퀀스 cutting 사이즈 변화에 따른 성능 변화 (Data Augmentation 효과 분석)
- 배치를 생성할 때 사전 정의된 최대 길이로 시퀀스 cutting
- 150k frame의 자르기 크기가 최상의 성능임을 확인
- 최대 길이를 제한하지 않으면 평균 시퀀스 길이가 약 207k이 되어 정확도가 가장 낮음
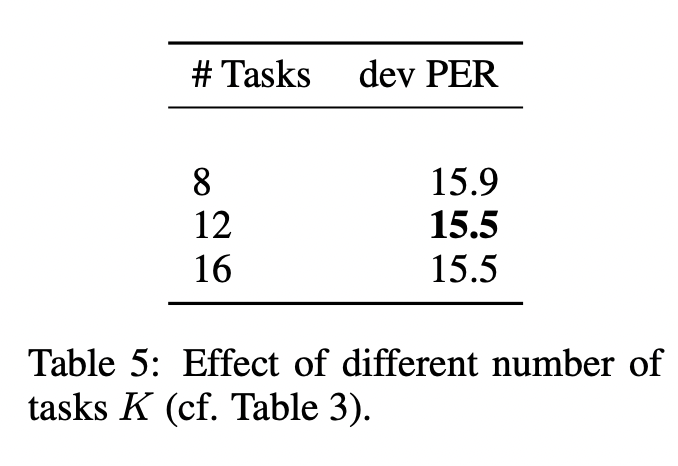
- 미래 예측 step K에 따른 성능 변화
- K=12이상일 경우 성능 향상 X
- 훈련 시간만 늘어나고, 성능 개선 없음
Future Works
- Wav2Vec 2.0의 등장
- wav2vec 2.0 은 기존 wav2vec 에 비해 트랜스포머를 사용하여 성능을 더 높였다
- wav2vec이 unsupervised learning이었으면, wav2vec 2.0은 self-supervised learning!
- MLM과 CPC를 함께 적용하여 작업을 통해 오디오의 마스킹된 부분을 예측하는 LM의 방식 활용

Code
- FAIR github에서 wav2vec 1.0 코드를 찾아봤는데 아예 없다 ... README.md에 써져 있는 거 보니 2020년 이후 모델들만 남겨두었나보다 ... !
https://github.com/facebookresearch/fairseq/tree/main/examples/wav2vec
- AM이었던 Wav2Letter 코드는 아래에 ... 그냥 진짜 Conv layer 많이 쌓은 거밖에 없다
https://pytorch.org/audio/main/_modules/torchaudio/models/wav2letter.html
torchaudio.models.wav2letter — Torchaudio 2.2.0.dev20240130 documentation
Shortcuts
pytorch.org
After Review
- 음성 쪽 초보로써 이번 논문 리뷰를 통해 전체적으로 ASR에선 어떤 식으로 실험을 하는지, 또 기반 지식들을 파악할 수 있는 좋은 기회였음
- 아쉬웠던 건
- 처음에 figure를 통해 과정을 이해하기 조금 힘들었단 것
- ablation study를 가장 성능이 좋은 세팅의 모델로 했을 거라 생각했는데 그게 아니어서 좀 의아
- 초기의 논문이니, 더욱 발전된 음성 모델들에 대한 내용들이 궁금해짐!
Reference
https://www.isca-speech.org/archive/pdfs/interspeech_2019/schneider19_interspeech.pdf
https://arxiv.org/abs/2006.11477
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in
arxiv.org
https://arxiv.org/abs/1609.03193
Wav2Letter: an End-to-End ConvNet-based Speech Recognition System
This paper presents a simple end-to-end model for speech recognition, combining a convolutional network based acoustic model and a graph decoding. It is trained to output letters, with transcribed speech, without the need for force alignment of phonemes. W
arxiv.org
https://github.com/flashlight/wav2letter
GitHub - flashlight/wav2letter: Facebook AI Research's Automatic Speech Recognition Toolkit
Facebook AI Research's Automatic Speech Recognition Toolkit - GitHub - flashlight/wav2letter: Facebook AI Research's Automatic Speech Recognition Toolkit
github.com
http://dsba.korea.ac.kr/seminar/?mod=document&uid=1779
[Paper Review]Semi-Supervised Learning in Auto Speech Recognition
1. Topic 음성인식(ASR)에 Semi-Supervised Learning을 적용한 5가지 논문을 리뷰합니다. 2. Overview Semi-Supervised Learning을 적용한 주요논문 5가지 [1] CPC1 : Representation Learning with Contrastive Predictive Coding - Contrastiv
dsba.korea.ac.kr
728x90'AI > Speech' 카테고리의 다른 글
- 기존 연구들과 그 한계