-
2024 데이터베이스개론 정리 - 5. SQL (문법/Stored Procedure/Transaction & Deadlock/Index & B+Tree)Database 2024. 4. 2. 18:31728x90
2024 데이터베이스개론 정리 - 5. SQL

- 1. 데이터베이스 시스템 개요
- 2. ER 모델 & EER 모델
- ER 모델
- EER 모델
- 3. 관계 데이터베이스 모델 (ER모델 to 관계 모델)
- 4. 관계 데이터 연산 - 관계 대수와 관계 해석
- 관계 대수
- 관계 해석
- 5. SQL
- 테이블 정의, 조작, 뷰
- 검색
- Stored Function, Stored Procedure
- Tigger
- Transaction & Deadlock
- DB 인덱스와 B Tree
- 6. 함수적 종속성과 정규화
- 함수적 종속성
- 정규화
- 추가
- RDB VS NoSQL


SQL (Structerd Query Language)
따라서 SQL 구문도 위의 목적에 맞게 크게 세 가지로 구분할 수 있습니다.
1. DDL(Data Definition Language)
2. DML(Data Manipulation Language)
3. DCL(Data Control Language)DDL 데이터베이스나 테이블 등을 생성, 삭제하거나 그 구조를 변경하기 위한 명령어 CREATE, ALTER, DROP DML 데이터베이스에 저장된 데이터를 처리하거나 조회, 검색하기 위한 명령어 INSERT, UPDATE, DELETE, SELECT 등 DCL 데이터베이스에 저장된 데이터를 관리하기 위하여 데이터의 보안성 및 무결성 등을 제어하기 위한 명령어 GRANT, REVOKE 등 

DDL:
데이터베이스나 테이블 등을 생성, 삭제하거나 그 구조를 변경하기 위한 명령어- 생성 : MySQL에서는 다음과 같은 CREATE 문을 사용하여 데이터베이스와 테이블을 만들 수 있습니다.
- 1. CREATE DATABASE
- 2. CREATE TABLE
CREATE DATABASE Hotel;- 수정 : MySQL에서는 다음과 같은 ALTER 문을 사용하여 데이터베이스와 테이블의 내용을 수정할 수 있습니다.ALTER DATABASE 문은 데이터베이스의 전체적인 특성을 수정할 수 있게 해줍니다.
- 1. ALTER DATABASE
- 2. ALTER TABLE
ALTER DATABASE Hotel CHARACTER SET=euckr_bin COLLATE=euckr_korean_ci;- 삭제 : MySQL에서는 다음과 같은 DROP 문을 사용하여 데이터베이스와 테이블을 삭제할 수 있습니다.
- 1. DROP DATABASE
- 2. DROP TABLE
DROP DATABASE Hotel;DROP TABLE Name;만약 테이블 자체가 아닌 테이블의 데이터만을 지우고 싶을 때는 TRUNCATE TABLE 문을 사용할 수 있습니다.
TRUNCATE TABLE Reservation;- 서버에 존재하는 데이터베이스 조회
SHOW DATABASES;- 사용 중인 데이터베이스의 테이블 구조 조회
DESCRIBE TableName;- 새로운 뷰를 생성하는 명령문 : VIEW
- 하나 이상의 기본 테이블(base table)로부터 유도되어 만들어지는 테이블
- 가상의 테이블로서 뷰의 레코드가 물리적으로 저장되지 않음
CREATE VIEW 뷰명 AS 검색질의(SELECT-FROM-WHERE);- 뷰의 삭제 : DROP VIEW
- 뷰의 수정 : ALTER VIEW
DML:
데이터베이스에 저장된 데이터를 처리하거나 조회, 검색하기 위한 명령어추가, 수정, 삭제
- 데이터 추가 : MySQL에서는 INSERT INTO 문을 사용하여 테이블에 새로운 레코드를 추가할 수 있습니다.
INSERT INTO Reservation(ID, Name, ReserveDate, RoomNum) VALUES(5, '이순신', '2016-02-16', 1108); INSERT INTO Reservation(ID, Name) VALUES (6, '김유신'); //추가하는 레코드가 반드시 모든 필드의 값을 가져야 할 필요는 없습니다.- 데이터 수정: MySQL에서는 UPDATE 문을 사용하여 레코드의 내용을 수정할 수 있습니다.
UPDATE Reservation SET RoomNum = 2002 WHERE Name = '홍길동';- 데이터 삭제 : MySQL에서는 DELETE 문을 사용하여 테이블의 레코드를 삭제할 수 있습니다.
DELETE FROM Reservation WHERE Name = '홍길동';검색
- 데이터 선택 : MySQL에서는 SELECT 문을 사용하여 테이블의 레코드를 선택할 수 있습니다.
SELECT * FROM Reservation; SELECT * FROM Reservation WHERE Name = '홍길동';

- 레코드(행) 정렬 : ORDER BY
- 내림차순 DESC, 오름차순 ASC
SELECT age, ssn FROM employees WHERE age > 20 ORDER BY age DESC;SELECT age, ssn FROM employees WHERE age > 20 ORDER BY 2 ASC;SELECT age, ssn FROM employees WHERE age > 20 ORDER BY age DESC, ssn; // age 컬럼을 기준으로 정렬 후, 같은 age 값을 가지는 레코드는 ssn 컬럼을 기준으로 정렬- 결과 표시 레코드(행) 수 제한 : LIMIT
SELECT age, ssn FROM employees WHERE age > 20 ORDER BY age LIMIT 3;- 중복 레코드(행) 제거 : DISTINCT
SELECT DISTINCT age FROM employees WHERE age > 20- 집계함수
- COUNT, SUM, AVG, MAX, MIN
- 그룹화 : GROUP BY절
- 집계함수 사용 시, GROUP BY 절을 이용하여 특정 컬럼을 기준으로 그룹화하여 결과 레코드를 그룹별로 구분
- 관례 상 SELECT 절에 기준 컬럼명을 명시하여 기준 컬럼 값과 그 값에 해당하는 레코드 그룹에 집계 함수를 적용
한 결과를 동시에 반환함
SELECT dno, COUNT(*), AVG(age) FROM employees WHERE age > 25 GROUP BY dno;- 그룹에 검색 조건 지정 : HAVING
- HAVING 절을 이용하여 GROUP BY 절에 의해 생성된 결과 값 중 조건에 부합하는 값만 표시할 수 있음
SELECT dno, COUNT(*), AVG(age) FROM employees WHERE age > 25 GROUP BY dno HAVING COUNT(*) > 1다중 테이블
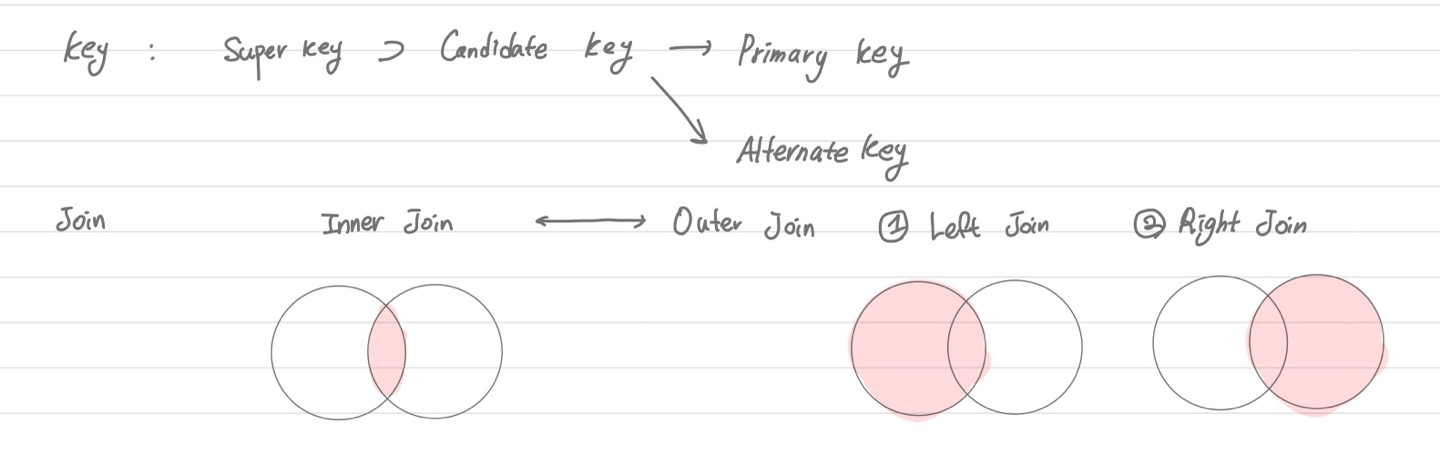
- 조인
- Inner Join, Left (Outer) Join, Right (Outer) Join, ...
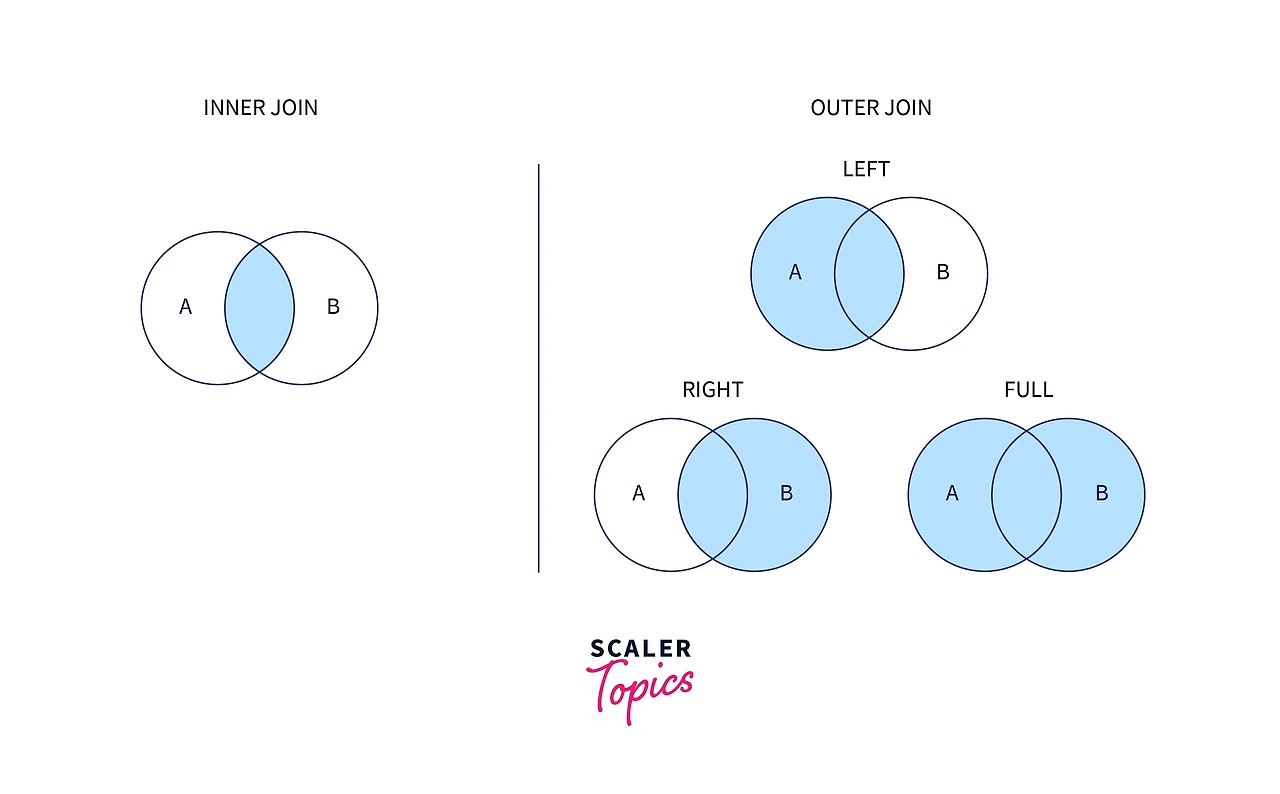
- Inner Join
- 조건에 해당하는 경우에만 왼쪽과 오른쪽 테이블의 값 가져옴 (조인 조건을 만족하는 레코드만 결과 테이블에 나타남)

- Left Join
- 조건에 해당하는 경우에 왼쪽과 오른쪽 테이블의 값 가져옴
- 조건에 해당하지 않는 경우에는 왼쪽 테이블 값은 그대로, 오른쪽 값은 NULL로 채워서 가져옴
- 두 테이블 연결 시 조인 조건과 상관 없이 왼쪽 테이블의 모든 레코드가 반환
- 오른쪽 테이블에 조인 조건을 만족하는 레코드가 없으면 결과 테이블에 NULL 값이 채워짐

- Right Join
- 조건에 해당하는 경우에 왼쪽과 오른쪽 테이블의 값 가져옴
- 조건에 해당하지 않는 경우에는 오른쪽 테이블 값은 그대로, 왼쪽 값은 NULL로 채워서 가져옴
- 두 테이블 연결 시 조인 조건과 상관 없이 오른쪽 테이블의 모든 레코드가 반환
- 왼쪽 테이블에 조인 조건을 만족하는 레코드가 없으면 결과 테이블에 NULL 값이 채워짐

- 중첩 질의 (Nested Query)
- SELECT문(주 질의)의 WHERE 절 내에 새로운 SELECT문(하위 질의 혹은 부 질의)을 포함하는 질의
- 하위 질의는 주 질의의 WHERE 절에서 레코드 검색 조건과 함께 사용 됨
- SELECT문(주 질의)의 WHERE 절 내에 새로운 SELECT문(하위 질의 혹은 부 질의)을 포함하는 질의

- 집합 연산
- 관계대수의 DIVISION 연산
- 릴레이션 R2의 모든 튜플과 관련이 있는 릴레이션 R1의 튜플들로 결과 릴레이션 구성


NOT EXISTS는 SQL에서 서브쿼리를 사용하여 특정 조건을 만족하는 행이 없는지를 테스트하는 데 사용되는 조건입니다. NOT EXISTS 다음에 오는 서브쿼리는 논리적인 "테스트"를 수행하며, 만약 서브쿼리가 어떤 행도 반환하지 않는다면 NOT EXISTS 조건은 참(true)이 됩니다.
이를 사용하는 일반적인 방식은 어떤 집합에서 다른 집합에 해당하는 요소가 없는 항목들을 찾는 것입니다. 예를 들어, EMPLOYEE 테이블에서 특정 조건을 만족하는 PROJECT가 하나도 없는 EMPLOYEE 행을 찾고 싶을 때 사용할 수 있습니다.
구체적으로 이 쿼리에서 NOT EXISTS는 다음과 같은 의미를 갖습니다:
1. EMPLOYEE 테이블에서 Lname을 선택하기 전에,
2. 5번 부서에 속한 모든 PROJECT를 확인하고,
3. WORKS_ON 테이블을 확인하여 직원(EMPLOYEE)이 해당 프로젝트에 참여하고 있는지 확인합니다.
4. 만약 어떤 프로젝트에서도 해당 직원의 Ssn이 WORKS_ON 테이블에 없다면 (즉, 직원이 그 프로젝트에서 일하지 않는다면),
5. 그 직원의 성(Lname)은 최종 결과에 포함됩니다.
NOT EXISTS가 참인 경우에만 바깥쪽 쿼리의 SELECT문이 그 행을 결과로 반환합니다.
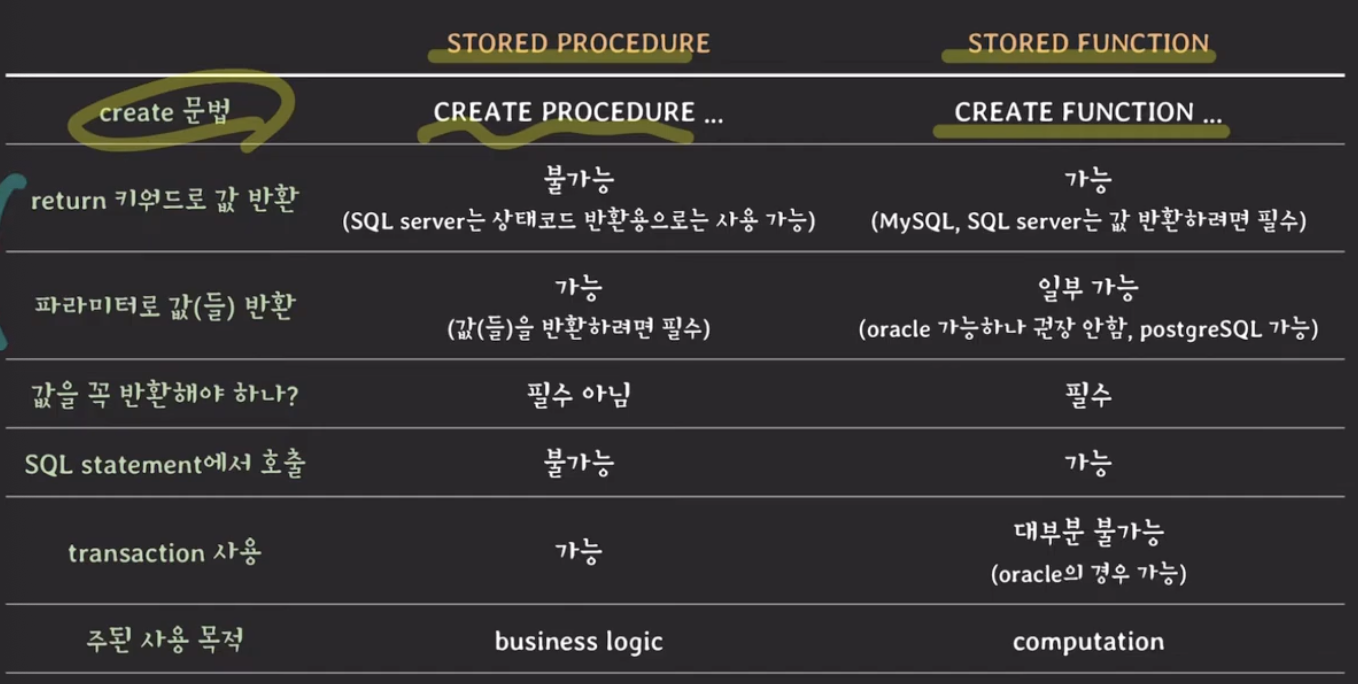
Stored Function, Stored Procedure
- Stored Function : 사용자가 정의한 함수
- Stored Procedure : 사용자가 정의한 프로시저 / 구체적인 하나의 태스크를 수행한다
Stored Procedure의 장점
- 최적화 & 캐시
- 만약 해당 프로세스가 여러번 사용될 때, 다시 컴파일 작업을 거치지 않고 캐시에서 가져오게 된다.
- 프로시저의 최초 실행 시 최적화 상태로 컴파일이 되며, 그 이후 프로시저 캐시에 저장된다.
- 유지 보수
- 작업이 변경될 때, 다른 작업은 건드리지 않고 프로시저 내부에서 수정만 하면 된다. (But, 장점이 단점이 될 수도 있는 부분이기도.. )
- 트래픽 감소
- 클라이언트가 직접 SQL문을 작성하지 않고, 프로시저명에 매개변수만 담아 전달하면 된다. 즉, SQL문이 서버에 이미 저장되어 있기 때문에 클라이언트와 서버 간 네트워크 상 트래픽이 감소된다.
- 보안
- 프로시저 내에서 참조 중인 테이블의 접근을 막을 수 있다.
Stored Procedure의 단점
- 호환성
- 구문 규칙이 SQL / PSM 표준과의 호환성이 낮기 때문에 코드 자산으로의 재사용성이 나쁘다.
- 성능
- 문자 또는 숫자 연산에서 프로그래밍 언어인 C나 Java보다 성능이 느리다.
- 디버깅
- 에러가 발생했을 때, 어디서 잘못됐는지 디버깅하는 것이 힘들 수 있다.
Tigger
- trigger: 데이터베이스에서 어떤 이벤트가 발생했을 때 자동적으로 실행되는 프로시저
- 데이터에 변경이 생겼을 때 즉, DB에서 insert, update, delete가 발생했을 때 이게 계기가 되어 자동적으로 실행되는 프로시저를 의미
- 예시 :
- 테이블에 상품이 입고가 되면 [상품]테이블에 상품의 [재고수량]이 수정
- 테이블에 [수량]을 수정하면 [상품]테이블의 [재고수량]도 수정되는
- trigger 사용 시 주의사항
- 디버깅 어려움
- 과도한 트리거 사용은 DB에 부담을 주고 응답을 느리게 만든다
Transaction & Deadlock
- 상황 : 계좌이체
- A는 매달 부모님에게 생활비를 송금받는다. 어느 날, 부모님이 A에게 생활비를 송금해 주기 위해 ATM을 이용했고 여느날 처럼 A의 계좌로 생활비를 송금했다.
- 그러나 모종의 이유로 인하여 부모님의 계좌에선 생활비가 차감되었는데, A의 계좌에는 생활비가 입금되지 않았다. => 치명적
- 위 두 과정은 동시에 성공하거나 동시에 실패해야 한다. (하나로 묶음으로써 Atomic함을 의미한다)
- Transaction :
- 더이상 분할이 불가능한 업무처리의 단위
- 단일한 논리적인 작업 단위
- 논리적인 이유로 여러 SQL문들을 단일 작업으로 묶어서 나눠질 수 없도록 만든 것
- transaction의 SQL문들 중에 일부만 성공해서 DB에 반영되는 일은 일어나지 않는다
- Transaction의 핵심 : ACID
- Atomicity (원자성)
- 원자성은 트랜잭션이 데이터베이스에 모두 반영되거나, 아니면 전혀 반영되지 않아야 한다는 것이다.
- Consistency (일관성)
- 일관성은 트랜잭션의 작업 처리 결과가 항상 일관성이 있어야 한다는 것이다.
- transaction은 DB 상태를 consistent 상태에서 또 다른 Consistent 상태로 바꿔줘야 한다
- constraint, trigger 등을 통해 DB에 정의된 rule들을 transaction이 위반했다면 rollback한다
- Isolation (독립성)
- 독립성은 둘 이상의 트랜잭션이 동시에 실행되고 있을 경우 어떤 하나의 트랜잭션이라도, 다른 트랜잭션의 연산에 끼어들 수 없다는 점을 가리킨다.
- 여러 transaction들이 동시에 실행될 때도 혼자 실행되는 것처럼 만든다
- concurrency control의 주된 목표가 isolation이다
- Durability (영구성)
- 지속성은 트랜잭션이 성공적으로 완료됬을 경우, 결과는 영구적으로 반영되어야 한다는 점이다.
- commit된 transaction은 DB에 영구적으로 저장한다 (여기서 영구적으로 저장한다는 '비휘발성 메모리'에 저장하단 의미)
- Atomicity (원자성)
- Deadlock
- 두 transaction이 각각 lock을 설정하고, unlock을 하지 않은 상태에서 서로의 lock이 걸린 데이터에 접근하려고 할 때, 서로 대기를 계속하여 영원히 처리되지 않는 상황
- 해결방안
- 예방 : 각 transaction이 실행되기 전에 한 Transaction에 필요한 데이터를 모두 Locking 해주는 것
- 회피 : 자원을 할당할 때 timestamp를 사용하여 deadlock가 일어나지 않도록 회피하는 방법
- 탐지 & 회복 : Transaction이 실행되기 전에는 아무런 검사를 하지 않고, deadlock이 발생하면 이를 감지하고 회복시키는 방법
DB 인덱스와 B Tree
Index
- 데이터베이스에서 table의 검색 성능을 높여주는 대표적인 방법 중 하나 (특히 범위 검색)
- 조건을 만족하는 튜플들을 빠르게 조회/정렬/그룹핑하기 위해 사용
- 원리
- index를 생성하게 되면 특정 column(속성, attribute)의 값을 기준으로 정렬하여 데이터의 물리적 위치와 함께 별도 파일에 저장
- index는 순서대로 정렬된 search-key값과 pointer값만 저장하기 때문에 table보다 적은 공간을 차지함
- Index에 저장되는 속성 값을 search-key값, 실제 데이터의 물리적 위치를 저장한 값을 pointer
- 구현 방법 : Btree, B+tree, Hash, Bitmap로 구현될 수 있음
- 그 중 B tree 구조를 많이 사용함
- 종류
- clustering index
- 특정 column을 기본키(primary key)로 지정하면 자동으로 클러스터형 인덱스가 생성되고, 해당 column 기준으로 정렬됨 (Table 자체가 정렬된 하나의 index인 것)
- secondary index
- 일반 책의 찾아보기와 같이 별도의 공간에 인덱스가 생성
- create index와 같이 index를 생성하기를 하거나 고유키(unique key)로 지정하면 보조 인덱스가 생성됨
- clustering index
Index의 장점/단점
- 장점
- SELECT ~WHERE query를 통해 특정 조건을 만족하는 데이터를 찾을 때, full table scan할 필요 없이 정렬되어 있는 index에서 훨씬 빠른 속도로 검색을 할 수 있게 됨
- 단점
- 인덱스를 관리하기 위해 DB의 추가 저장공간이 필요하다.
- 인덱스를 관리하기 위해 추가 작업이 필요하다.
- 인덱스를 잘못 사용하는 경우 오히려 성능이 저하되는 역효과가 발생할 수 있다.
B+Tree

- 하나의 값만 가져올 때는 hash table이 더 나을 수 있지만, 일정 범위의 값들을 찾을 때는 B+tree가 적합
- Hash table을 사용하면 하나의 데이터를 탐색하는 시간은 O(1)로 b+tree보 다 빠르지만,
- 값이 정렬되어 있지 않기 때문에 부등호를 사용하는 query에 대해서는 매우 비효율적
- 장점
- 항상 정렬된 상태를 유지하여 부등호 연산에 유리
- 데이터 탐색뿐 아니라, 저장, 수정, 삭제에도 항상 O(logN)의 시간 복잡도 (균형 잡힌 트리이기 때문)
- 왜 B-Tree가 아니라 B+Tree?
- B-Tree는 탐색을 위해서 노드를 찾아서 이동해야 한다는 단점 -> 즉, 모든 데이터를 순회하는 경우, 모든 노드를 방문해야해서 비효율적
+) Binary Search Tree, B-Tree (Balanced Tree), B+Tree란?
- B+Tree는 B-Tree의 변형이고, B-Tree 또한 Binary Search Tree에서 진화된 것이다
- Binary Tree와 Binary Search Tree 차이
- Binary Tree : 각 노드가 최대 두 개의 자식을 갖는 트리
- Binary Search Tree : 모든 왼쪽 자식들 <= N <= 모든 오른쪽 자식들이라는 특성을 가진 모든 노드 n의 트리

- B-tree
- 특징
- B-Tree는 이진 트리와 달리 자식노드의 개수가 2개이상인 트리이다.
- 이진 탐색 트리와 다르게 balance가 맞춰져 있는 자료구조이다.
- 즉, 루트로부터 리프까지의 거리가 일정한 트리 구조
- 장점
- 균형을 유지할 경우 어떤 데이터를 검색할 때 빠른 속도로 데이터를 찾을 수 있음 (최악의 경우 O(log n)의 시간복잡도)
- 단점
- 트리균형을 위해서 복잡한 연산이 필요하다.(재분배, 합병)
- 순차탐색 시 비효율적이다. 중위순회를 하기때문.
- 특징


- B+Tree
- 특징
- B-tree의 순차탐색을 효율적으로 하기위해 B+tree가 등장
- B-tree와 달리 데이터는 leaf노드에만 존재한다.
- leaf노드들은 연결리스트 형태로 서로 연결되어 있고 오름차순으로 정렬되어있다.(순차탐색에 효율적인 이유)
- B-tree와 달리 leaf노드가 아닌 노드는 데이터의 빠른 접근을 위한 인덱스 역할만 수행한다.(key와 pointer로만 구성)
- 특징

- B-Tree VS B+Tree
-
- 검색 방법
- 데이터를 검색할 때 항상 리프 노드까지 이동하므로 검색 경로가 단순해진다.
- 포인터의 사용
- 데이터를 찾기 위해 internal 노드를 항상 통과해야 조회한다. ⇒ 추가적인 단계 필요 (단점)
- internal 노드를 통하지 않고도 형제 노드로 이동 가능하고, 범위 검색이나 범위 쿼리가 쉽다.
- 범위 쿼리와 범위 검색
- B-Tree: 범위 쿼리를 수행하려면 트리의 루트에서부터 리프 노드까지 이동하면서, 루트 노드, internal 노드에 있는 데이터까지 함께 조회해야 한다.
- B+Tree: 데이터는 리프 노드에만 존재하므로, 범위 쿼리는 리프 노드를 시작으로 연결된 리스트를 따라가면 모든 데이터를 조회할 수 있다.
- 순차 탐색 및 정렬
- B-Tree: 순차적인 탐색이나 정렬을 위한 추가적인 알고리즘이 필요해서 (예. inorder traversal) B+Tree보다 더 복잡하다.
- B+Tree: 연결된 리스트를 따라가면서 순차 탐색이 용이하며, 키들은 항상 정렬된 상태를 유지하면서 저장된다.
- 메모리 사용
- B-Tree: 리프 노드와 내부 노드가 각각 데이터와 포인터까지 가지고 있기 때문에 B+Tree보다 더 많은 메모리 공간을 차지한다.
- B+Tree: 데이터는 리프 노드에만 저장되고, internal 노드는 키만 갖고 있으면 되므로, 메모리 효율이 좋다.
- 검색 방법
-
Ref.
https://www.tcpschool.com/mysql/mysql_basic_create
코딩교육 티씨피스쿨
4차산업혁명, 코딩교육, 소프트웨어교육, 코딩기초, SW코딩, 기초코딩부터 자바 파이썬 등
tcpschool.com
https://www.youtube.com/watch?v=c8WNbcxkRhY&list=PLcXyemr8ZeoREWGhhZi5FZs6cvymjIBVe&index=3
https://engineerinsight.tistory.com/336
[자료구조] B+Tree: 개념, 특징, B-Tree와의 차이점 정리
Computer Science 모아보기 👉🏻 https://github.com/seoul-developer/CS GitHub - seoul-developer/CS: 주니어 개발자를 위한 전공 지식 모음.zip 주니어 개발자를 위한 전공 지식 모음.zip. Contribute to seoul-developer/CS develo
engineerinsight.tistory.com
https://velog.io/@kyeun95/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-B-Tree%EB%9E%80
[자료구조] B+ Tree란?
루트 노드(root node) : 부모가 없는 노드. 트리는 하나의 루트 노드만을 가진다.단말 노드(leaf node) : 자식이 없는 노드이다.형제(sibling) : 같은 부모를 가지는 노드.바이너리 트리와 개념적으로 비슷
velog.io
https://youtu.be/iNvYsGKelYs?si=11Gu00eEgT0TjEUX
Binary Search Tree에서 B+Tree까지(Database Index 추가)
이진탐색트리로부터 Btree, B+tree 그리고 Database index의 탄생과 특징을 총 망라한 자료입니다.
velog.io
728x90'Database' 카테고리의 다른 글
2024 데이터베이스개론 정리 - 4. 관계 데이터 연산 - 관계 대수와 관계 해석 (0) 2024.04.02 2024 데이터베이스개론 정리 - 3. 관계 모델 (ER모델 to 관계 모델) (0) 2024.04.02 2024 데이터베이스개론 정리 - 2. ER 모델 & EER 모델 (0) 2024.04.02 2024 데이터베이스개론 정리 - 1. 데이터베이스 시스템 개요 (0) 2024.04.02