-
LLM의 Context Length 늘리기 (1) - Positional Embedding부터 RoPE, Position Interpolation, NTK, YaRNAI/NLP 2025. 7. 13. 15:30728x90
LLM의 Context Length 늘리기 (1)
- Positional Embedding부터 RoPE, Position Interpolation, NTK, YaRN최근 업무로 Agent를 하다 보니
Tool Description 등으로 인해 Context Length가 불가피하게 길어지더라32K로 열어두고 사용하고 있었는데 Tool Description만 22K라 Context length 늘리는 방법을 요즘 공부 중이다
크게 1) 모델이 원래 볼 수 있는 최대의 Context Length보다 더 늘릴 수 있는 방안(즉, 모델이 긴 입력을 이해하도록 하는)이 있고,
두번째로 2) 긴 Context일 때도 추론이 느려지지 않도록 하는 방안 (긴 시퀀스에서 메모리 문제로 게산이 느려지기에)이 있음위치 임베딩 계열 RoPE, YaRN, Position Interpolation 토큰 위치 정보 처리 (입력 레벨) 모델이 긴 위치값(position) 도 이해하도록 KV 캐시 최적화 계열 Paged Attention (vLLM), LMCache, FlashAttention-2 캐시 저장·읽기·계산 최적화 (추론 레벨) 컨텍스트가 길어질수록 비용이 폭증하는 추론 성능 문제 해결 1번 방법 중 그중 가장 쉽게 적용할 수 있는 방법이 YaRN이었고,
요거 개념만 알고 있었지 이렇게 적용하려니까 구체적인 이론적 배경이 궁금해져서 정리해둔다
요렇게 vLLM에서도 --rope-scaling 이라는 인자로 yarn을 설정할 수 있는데 ... ! 몰랐다
vllm 로 추론 시 최적화할 수 있는 방법도 조금 더 찾아봐야 할 듯
들어가기 전 … Encoding과 Embedding의 차이
- Encoding은 모델 학습중에 변하지 않는 값이며, Embedding은 모델이 학습을 통해 변하는 파라미터
- 왜 Positional Embedding ?
- RNN, Seq2Seq과 같은 모델들은 순차적으로 Token이 입력되었으나, Transformer와 같은 경우, 한꺼번에 들어가기 때문에 token들의 위치 정보를 함께 입력해줘야 함
들어가기 전 … Positional Encoding/Embedding의 종류

1) Absolute Positional “Encoding”
- 말 그대로 절대적 위치를 사용하여 Position Embedding을 정의
- 절대적 위치를 이용해서 어떻게 정의를 하느냐는 모델마다 다르다
- 정의된 position embedding vector와 input embedding vector를 합치는 방법
- Absolution Position Embedding에서는 단순히 vector sum으로 정의
- 왜 Concatenation이 아니라 Summation이냐 ?
- Concatenate를 사용하면 단어 의미 정보를 포함하고 있는 단어 벡터 뒤에 위치 정보를 포함하는 positional embedding이 연결된다. 이 경우 단어의 의미 정보는 자체 차원 공간을 갖게 되고, 위치 정보 역시 자체 차원 공간을 갖으며, 직교성질(orthogonal)에 의해 둘은 서로 전혀 관계없는 공간에 있게 된다. 이러한 Concatenate가 주는 이점은 정보가 뒤섞이는 혼란을 피할 수 있게 해주지만, 메모리, 파라미터, 런타임 등과 관련된 비용 문제가 발생한다. Summation을 사용한다면, 단어 의미 정보와 위치 정보 간의 균형을 잘 맞출 수 있다. 즉 모델이 위치 정보를 적절하게 가지게 되고 동시에 단어 의미 정보 역시 충분히 강력하게 유지되어 벡터 공간에서 단어 의미 정보와 위치 정보 간의 거리가 적절해진다. 하지만 Summation의 경우, 정보가 뒤섞이는 문제가 발생할 수 있다. 따라서 모델이 매우 크고 GPU 등의 성능이 좋고 비용 문제가 발생하지 않다면 Concatenate을 사용해도 무관하다.
- 왜 Concatenation이 아니라 Summation이냐 ?
- Absolution Position Embedding에서는 단순히 vector sum으로 정의
- sinusoidal 함수값 (아래 fiugre 참조) 을 더하거나 position embedding을 학습해 더해줌. position embedding을 학습해 더해줄 경우, 학습 중에 참조하지 않은 더 긴 input에 대응하기 힘들다는 한계가 있음
- 단점
- 토큰간의 거리에 대한 정보를 포함하고 있지 않기에 기준이 되는 토큰에서 가까운 토큰과 먼 토큰에 대해서 동일하게 본다

2) Relative Positional "Embedding"
- 상대적인 위치로 position embedding vector를 정의
- learnable parameter를 attention에 추가해서 key와 query의 거리에 따라서 position이 학습됨 (T5, Gopher에서 도입)
- 가까운 거리의 token과는 거리를 민감하게 학습하고, 먼 거리의 token과는 거리를 덜 민감하게 학습
- 어떻게 상대적인 위치를 고려할 것이냐?
- transformer구조에서 input embedding vector와 position 정보가 합쳐져서 self attention의 input으로 들어감
- self attention score에서의 attention weight에 상대적인 위치라는 개념이 나올 수 있음
- m번째 self attention score는 n개의 value function의 weighted sum으로 정의되는데, 여기서 weight인 attention weight은 m번째 token과 서로 다른 위치의 token이 얼마나 영향을 미치는가로 해석 가능
- m번째 token과 가까운 token들이 영향을 강하게 미치고 멀리 떨어져 있을수록 약하게 영향을 미친다는 것을 일반적인 문장에서 알 수 있음
- attention weight에서 중요한 연산은 m번째 query function과 n번째 key function의 inner product연산
- 대표적으로 T5모델의 경우는 위치와 관련된 부분을 하나의 bias term으로써 상대적인 position 정보를 넣게 됨
- value function에는 attention weight쪽에 상대적인 위치정보가 들어갔기 때문에 별도로 위치정보를 추가로 더 넣지 않음
- 단점
- 모델의 학습시 계산량이 늘어나며 비효율적 (Computationally Inefficient)
- 모델을 사용하여 추론을 할 때에 Positional Embedding이 계속 바뀌어서 추론시에 적합하지 않다는 의견
3) Rotary Positional "Embedding"
2021년: 기초 확립 - RoPE
4월: Jianlin Su 등이 RoFormer 논문에서 RoPE 도입https://arxiv.org/pdf/2104.09864
- 위의 두가지 방법의 단점을 보완한 방법으로 RoFormer라는 모델에서 처음 소개되어 현재는 Llama2, PaLM등에서 많이 사용
- Rotary Positional Embedding은 삼각함수에서의 Rotation Matix를 이용
- input embedding에 rotation matrix를 적용하는데, sequence 내 토큰의 위치 & embedding dimension에 따라 결정됨
- 단순히 숫자로 된 위치 정보를 임베딩(vector)에 추가하거나 더하는 대신, 벡터에 "회전 변환(Rotation)"을 적용하는 방식을 사용
- 입력 단어의 위치에 따라 벡터의 방향이 달라짐
- 단어 간의 상대적 위치 관계를 자연스럽게 반영할 수 있음
- RoPE는 입력 벡터를 위치에 따라 회전시키는 방식인데, 이 회전 변환의 성질이 토큰 간 상대적 위치를 이해하는 데 핵심 역할을 함
- 벡터의 회전
- RoPE(x)=[x1cos(θ)−x2sin(θ),x1sin(θ)+x2cos(θ)]
- θ = 각 위치에 해당하는 회전 각도
- 위치가 달라질수록 벡터가 다른 각도로 회전함
- 두 벡터의 내적 관계
- RoPE를 통해 벡터를 회전시키면, 두 벡터의 내적(dot product) 값이 위치 차이에 따라 변함
- Transformer 모델의 핵심은 어텐션 메커니즘이 벡터 간 내적을 활용한다는 점인데, RoPE는 여기서 위치 차이를 반영할 수 있음
- 벡터의 회전
- 상대적 위치 관계를 수학적으로 보존
- RoPE는 두 토큰 벡터 x₁, x₂가 각각의 위치 θ₁, θ₂에서 회전한 후에도 상대적 위치 정보를 계산할 수 있음
- 내적 계산
- 회전된 벡터: x₁ᵣᵒᵗ = RoPE(x₁,θ₁), x₂ᵣᵒᵗ = RoPE(x₂,θ₂)
- 벡터 내적(dot product): x₁ᵣᵒᵗ·x₂ᵣᵒᵗ ∝ cos(θ₁−θ₂)
- 결론: RoPE는 벡터 간 내적이 위치 차이 θ₁−θ₂에 따라 변하도록 함. 이를 통해 두 토큰 간의 상대적 위치 정보가 내적 값에 자연스럽게 반영됨
RoPE를 이용한 Context Length의 확장 - 1. Position Interpolation
2023년: 첫 번째 확장 - Position Interpolation
6월: Meta AI가 위치 보간법 발표
Extending Context Window of Large Language Models via Positional Interpolation
We present Position Interpolation (PI) that extends the context window sizes of RoPE-based pretrained LLMs such as LLaMA models to up to 32768 with minimal fine-tuning (within 1000 steps), while demonstrating strong empirical results on various tasks that
arxiv.org
RoPE layer쪽을 살짝 바꿔줌으로써 원래 수용가능한 context size보다 훨씬 더 많은 양이 수용가능한 방식!
1. 2D RoPE 기본 개념
- Position Interpolation을 설명하기 전에 2차원에서의 RoPE를 먼저 살펴봄
- RoPE 적용 시 query function과 key function이 아래 방식으로 정의됨
- position 정보(m)는 rotary matrix(cosine, sine 부분의 matrix)에만 영향을 미침
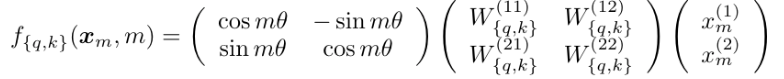
2. 제한된 Context Length 문제
- 제한된 context length를 가진 pretrained LLM에서 rotary matrix 값들은 position에 따라 아래 그림처럼 미리 학습된 영역의 y값을 가짐

3. 문제 발생 원인
- context length가 2048로 제한된 경우, 그 이상의 token이 나오면 rotary matrix가 unseen Range의 y값을 가지게 됨
- 제한된 context length를 넘어서도 rotary matrix는 -1~1 사이의 값을 가지므로 이론적으로는 문제없어 보임

- 하지만 실제 attention score를 확인하면 제한된 context length 내에서는 -3~3 사이 값을 형성하는 반면, 그 이상에서는 attention score가 폭발하는 현상 발생
- 이로 인해 제한된 context length 이상에서 generate할 때 이상한 token들이 생성됨

4. Position Interpolation 해결법
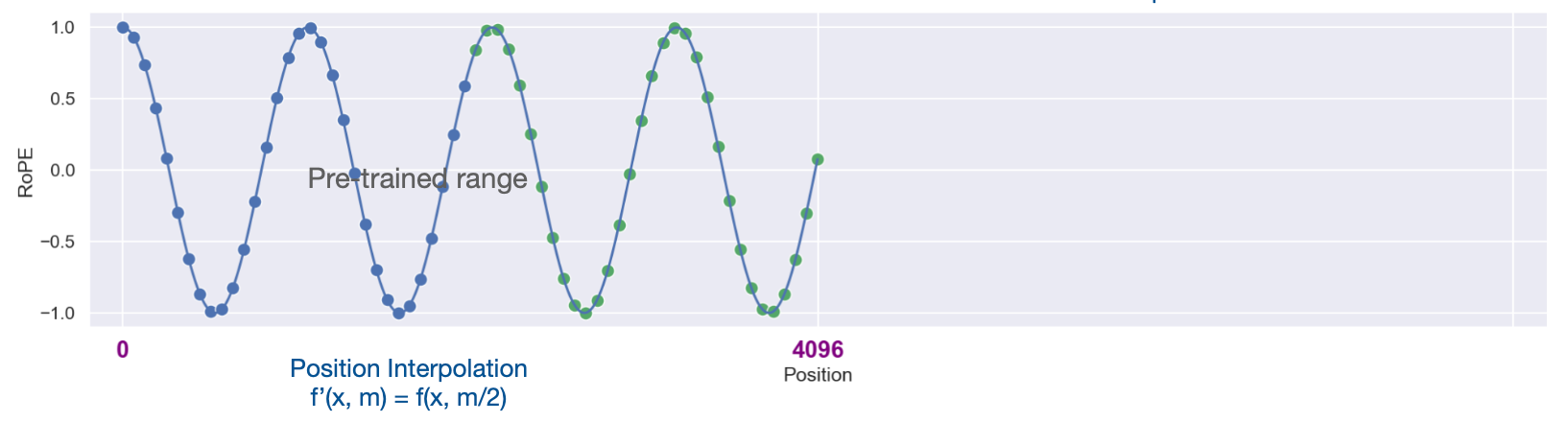
- attention score 폭발을 방지하기 위해 늘리고자 하는 context length까지 이미 알고 있는 영역으로 interpolation 수행
- 늘리고자 하는 context length까지 linear scale로 interpolation하면 attention score가 bound됨을 저자가 증명
5. 실험 결과

- 늘리고자 하는 context length에 대해 fully finetuning하는 것보다 Position Interpolation 후 1/10 수준만 finetuning해도 perplexity 관점에서 더 나은 성능을 보임
6. 한계
- PI는 모든 dimension을 동일하게 scaling하기 때문에 고주파, 즉 high frequency 정보 손실이 있음
NTK-Aware Method
왜 고주파에서 정보 손실이 있냐면 !
- https://arxiv.org/abs/1806.07572 요 논문으로부터 Neural Tangent Kernel (NTK) 이론 등장
- 이를 더 연구한 Tancik 등(2020)의 연구에 따르면(https://arxiv.org/abs/2006.10739),
신경망은 입력 차원이 낮고 해당 임베딩에 고주파 성분이 부족할 때 고주파 함수 학습에 어려움을 겪음 . - 이는 RoPE의 상황과 정확히 일치
- 입력: 1차원 토큰 위치
- 출력: n차원 복소 벡터 임베딩
- 스펙트럼 편향 문제
- 표준 MLP는 "스펙트럼 편향"을 보인다 - 낮은 주파수 성분을 선호적으로 학습
- 훈련 역학은 다음과 같음
- |Q^T(ŷ^(t) - y)|_i ≈ e^(-ηλ_i t)|Q^T y|_i
여기서 λ_i는 NTK 행렬의 고유값이고, 더 큰 고유값을 가진 성분이 더 빠르게 수렴.
고주파 성분은 더 작은 고유값을 가져 느린/불완전한 수렴을 보임.주파수에 따른 역할 구분
고주파 성분의 역할
- 인접한 토큰들 사이의 미세한 위치 차이 구분
- 지역적 패턴 인식 (문법 관계, 의존성)
- 세부 정보 보존 및 정확한 순서 인식
- 전역적 위치 정보 제공 (문서 전체에서의 거시적 위치)
- 장거리 의존성 포착 (멀리 떨어진 토큰 간 관계)
- 구조적 패턴 인식 (문단, 섹션 등 큰 단위)
- 컨텍스트 확장 시 안정성 제공
NTK-aware Interpolation
개념
- 고주파수는 적게, 저주파수는 더 많이 스케일링
- 보간 압력을 여러 차원에 분산하여 고주파수 정보 보존
PI은 모든 주파수를 균등하게 스케일링
g(m) = m/s, h(θ_d) = θ_dNTK-aware Interpolation은 기저 변경을 통해 고주파는 덜, 저주파는 더 많이 스케일링
g(m) = m h(θ_d) = b'^(-2d/|D|)여기서:
b' = b · s^(|D|/(|D|-2))장단점
- 장점:
- 파인튜닝 없는 모델에서 PI보다 우수한 성능
- 단점:
- 파인튜닝 후에는 PI보다 성능 열등
- 일부 차원이 범위 벗어남 (외삽의 문제 발생)
정상적인 보간 vs 외삽
보간(Interpolation)
- 훈련 시 본 값들 사이의 중간값 사용
- 예: 훈련 시 위치 1-2048을 봤다면, 1.5, 1000.7 같은 중간값 사용
- 안전하고 예측 가능한 범위
- 훈련 시 본 범위를 벗어난 값 사용
- 예: 훈련 시 1-2048만 봤는데 3000, 5000 같은 값 사용
- 미지의 영역으로 모델이 어떻게 반응할지 불확실
- 어떤 길이에서는 잘 작동하다가 특정 길이에서 갑자기 성능 급락
- 외삽 영역에 들어가는 순간 예측 불가능한 동작
- 실용성 측면에서 큰 문제
"NTK-by-parts" Interpolation
부분별 접근법의 필요성
NTK by parts 보간법은 RoPE 차원들이 컨텍스트 길이에 대한 파장에 따라 서로 다른 역할을 한다는 인식에서 출발
이는 NTK-aware 보간의 외삽 문제를 해결하면서도 고주파 정보를 보존하는 방법
NTK-by-parts의 전략
- 1. 외삽 방지
- "λ가 L과 같거나 크면 보간만 함 (외삽 방지)"
- 고주파수 차원: 전혀 보간하지 않음
- 저주파수 차원: 항상 보간함
- 중간 차원: 램프 함수로 점진적 처리
- 안전한 범위에서만 스케일링 적용
- 위험한 고주파수 영역은 아예 건드리지 않음
- "λ가 L과 같거나 크면 보간만 함 (외삽 방지)"
- 2. 점진적 처리
- 램프 함수로 안전한 영역과 위험한 영역 사이를 부드럽게 연결
- 급작스러운 변화 방지
- 예측 가능하고 안정적인 동작 보장
YaRN (Yet another RoPE extensioN method)

개요
YaRN(Yet another RoPE extensioN method)은 대형 언어모델의 컨텍스트 윈도우를 효율적으로 확장하는 방법임. 기존 방법 대비 10배 적은 토큰과 2.5배 적은 훈련 단계로 성능 향상을 달성함.
핵심 문제 인식
주파수 성분의 역할 구분
고주파 성분의 역할
- 인접한 토큰들 사이의 미세한 위치 차이 구분
- 지역적 패턴 인식 (문법 관계, 의존성)
- 세부 정보 보존 및 정확한 순서 인식
저주파 성분의 역할
- 전역적 위치 정보 제공 (문서 전체에서의 거시적 위치)
- 장거리 의존성 포착 (멀리 떨어진 토큰 간 관계)
- 구조적 패턴 인식 (문단, 섹션 등 큰 단위)
- 컨텍스트 확장 시 안정성 제공
기존 방법의 문제점
Position Interpolation (PI)
- 모든 주파수를 균일하게 스케일링
- 고주파수 정보 손실로 세밀한 위치 구분 능력 저하
NTK 이론의 통찰
- 입력 차원이 낮고 고주파수 성분이 부족하면 깊은 신경망이 고주파수 정보 학습에 어려움
- 결과적으로 모델의 표현력과 일반화 능력 감소
YaRN의 핵심 기법들
1. NTK-aware 보간
개념
- 고주파수는 적게, 저주파수는 더 많이 스케일링
- 보간 압력을 여러 차원에 분산하여 고주파수 정보 보존
장단점
- 장점: 파인튜닝 없는 모델에서 PI보다 우수한 성능
- 단점: 파인튜닝 후에는 PI보다 성능 열등, 일부 차원이 범위 벗어남
2. NTK-by-parts 보간
핵심 전략
- 고주파수 차원: 전혀 보간하지 않음
- 저주파수 차원: 항상 보간함
- 중간 차원: 램프 함수로 점진적 처리
파장 기반 판단
- λ ≪ L: 보간 안 함 (고주파수)
- λ ≥ L: 보간만 함 (저주파수, 외삽 방지)
- 비율 r = λ/L로 보간 여부 결정
파라미터
- α: 램프 함수 시작점 (Llama: α = 1)
- β: 램프 함수 끝점 (Llama: β = 32)
3. Dynamic Scaling
문제 해결
- 고정 스케일 인수 사용 시 발생하는 성능 급락 방지
- 시퀀스 길이에 따른 동적 스케일 조정
공식
s_dynamic = max(1, l_current/L_original)적용
- 모든 보간 방법에 적용 가능
- 파인튜닝 없이도 효과적 (특히 dynamic NTK)
4. 온도 스케일링
메커니즘
- 어텐션 소프트맥스 전 로짓에 온도 t 적용
- 벡터 스케일링으로 구현: √(1/t)
최적 온도
t = s^(ln(s)/ln(1024)) # Llama 계열효과
- 확장된 컨텍스트 윈도우에서 일관된 복잡도 개선
- 모델 크기와 데이터에 무관하게 안정적 성능

Ref.
https://devocean.sk.com/blog/techBoardDetail.do?ID=166264&boardType=techBlog
Long context LLM : 1부 Position Embedding
devocean.sk.com
Long context LLM : 2부 RoPE Extension Method
devocean.sk.com
http://googleanalytics360.com/m/board/view.php?bo_table=DataEngineering&wr_id=4&page=
[ML/DL] Transformer - Rotary Encoding - 구글애널리틱스 전문 커뮤니티 Google Aanlytics 360.com
[ML/DL] Transformer - Rotary Encoding - 구글애널리틱스 전문 커뮤니티 Google Analytics360.com | GA4, GA360, 구글마케팅플랫폼기반 데이터마케팅 성공사례 공유 커뮤니티
googleanalytics360.com
https://www.blossominkyung.com/deeplearning/transfomer-positional-encoding
트랜스포머(Transformer) 파헤치기—1. Positional Encoding
트랜스포머 Transformer Attention is All You Need Postional Encoding
www.blossominkyung.com
https://julie-tech.tistory.com/147
Secret of Long Context Length
* 이 글은 아래 아티클을 한글로 의역한 내용을 담고 있습니다. https://blog.gopenai.com/how-to-speed-up-llms-and-use-100k-context-window-all-tricks-in-one-place-ffd40577b4c The Secret Sauce behind 100K context window in LLMs: all trick
julie-tech.tistory.com
https://medium.com/@rcrajatchawla/understanding-yarn-extending-context-window-of-llms-3f21e3522465
Understanding YaRN: Extending Context Window of LLMs
YaRN: Yet another RoPE extensioN method
medium.com
https://discuss.pytorch.kr/t/yarn-rope-llm-10-2-5-context-window-128k/2799
YaRN: RoPE + LLM으로 10배 적은 토큰과 2.5배 적은 학습 단계로 Context Window를 128k까지 확장하기
이 글은 GPT 모델로 자동 요약한 설명으로, 잘못된 내용이 있을 수 있으니 원문을 참고해주세요! 😄 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다! 🙇
discuss.pytorch.kr
https://blog.eleuther.ai/yarn/
Extending the RoPE
What we've been up to for the past year EleutherAI.
blog.eleuther.ai
728x90'AI > NLP' 카테고리의 다른 글
ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models (25.07) 논문 리뷰 (0) 2025.07.18 LLM의 Context Length 늘리기 (2) - KV Cache 최적화 기법들 (1) 2025.07.13 [GPU/메모리] 내 GPU엔 몇 B 모델까지 올라갈 수 있을까? (+ 필요 메모리 계산하는 코드) (0) 2025.07.06 [unsloth] LoRA Hyperparameters Guide 번역 (1) 2025.07.06 S1: Simple Test-time scaling (25.01) 논문 리뷰 (0) 2025.07.06