-
강화학습 Chapter 05) Model-free ControlAI/Reinforcement Learning 2025. 7. 19. 16:55728x90
강화학습 Chapter 05) Model-free Control
- Model-Free: 환경에 대한 model를 모르기 때문에, agent는 외부적인 상호작용을 통해 그 model에 대해 계산한다
- Control: 그 현재의 Value Function을 토대로 더 나은 policy를 구하고 이와 같은 과정을 반복하여 optimal policy를 구하는 것 ( = improvement)
- Recap - Prediction :현재 optimal하지 않는 어떤 policy에 대해서 sampling을 통해 value function을 구하기 ( = evaluation)

- MDP model을 몰라도 experience는 sampled될 수 있으며, MDP Model을 알아도 sampling이 없으면 방대한 양을 다 계산해야만 하기 때문에
1. Monte Carlos Control
1) Monte Carlos Policy Iteration
⇒ " Monte-Carlo Policy Iteration = Monte-Carlo Policy Evaluation (State Value F. ) + Policy Improvement (Greedy) "
( ↔ DP에서는 Policy Iteration = 그냥 evaluation + Improvement )

2) Monte Carlos Control
⇒ " Monte Carlos Control = Monte Carlos Policy Evaluation = Prediction (Action Value F. ) + e-greedy Policy Improvement "
( ↔ Monte Carlos Control은 Monte Carlos Policy Evaluation + Greedy Policy Evaluation)
하지만 Monte-Carlos Policy Iteration에는 세 가지 문제점이 있다!
- Value Function
- Exploration
- Policy Iteration
(1) Value Function
⇒ state value function → "Action Value Function"

- 문제점: 위의 Monte Carlos Policy Iteration에서 사용한 value function은 policy improvement할 때 문제 생김!
- → state value F. 으로 improve하려면 reward와 state transition prob, 즉 MDP의 model을 알아야 하는데(=model based) 그러면 Model-free가 되지 못하기 때문에 (state value F의 경우, agent가 episode마다 얻은 reward들로 state의 return값을 계산하고 이를 평균을 취해 state마다 value func.들을 계산해 놓는다. )
- 해결책: 그 대신에 Action Value Function 사용할 것!
- → action value F의 경우, return이 아닌 agent가 episode마다 random하게 움직이며 얻은 reward들 그리고 state transition prob.를 통해서 action-value func.을 계산할 수 있다

(2) Exploration
⇒ Greedy Policy Improvement → "epsilon Greedy Policy Improvement"

- 문제점: 기존의 Greedy Policy Improvement는 충분히 exploration을 진행하지 않아(항상 최적의 경우만 선택하기에) local optimum에 빠질 가능성 有
- ⇒ 충분한 Exploration 필요!
- 해결책: 일정 확률(= epsilon)로 현재 상태에서 가장 높은 가치를 가지지 않은 다른 action을 하도록 하여 충분히 exploration 한다!
- ⇒ " E-Greedy Policy Improvement "



(3) Policy Iteration
⇒ policy Iteration에서는 evaluation 과정을 true value function으로 수렴할 때까지 → "한 번만 evaluation하기"

- Chapter 03의 Value Iteration에서도 Policy Evaluation 과정을 한 번만 한 후 improvement 과정을 거쳐도 optimal에 도달할 수 있었다
- Monte-Carlo에서도 마찬가지로 이 evaluation과정을 줄임으로서 Monte-Carlo policy iteration에서 Monte-Carlo Control이 된다.
3) GLIE

- GLIE란 Greedy in the Limit with Infinite Exploration을 뜻하며, 학습을 해나감에 따라 **충분한 탐험(exploration)**을 했다면 greedy policy에 수렴하는 것을 의미
- But, epsilon greedy policy로서는 greedy하게 하나의 action만 선택하지 않는데 이럴 경우는 GLIE하지 않다
- ⇒ exploration문제 때문에 사용하는 epsilon greedy에서 epsilon이 시간에 따라서 0으로 수렴한다면 epsilon greedy 또한 GLIE가 될 수 있다!
4) 최종

2. Temporal Difference Control


SARSA Algorithm
⇒ "TD(0)의 식에서 value function을 action value function으로 바꾸어주면 Sarsa가 된다!" [Update value V(St) toward estimated return R_t+1 + r Q(S_t+1)]
(1) Time Step마다 현재의 value function을 계산하는데 (2) 주변의 state들의 state value function을 사용하여 업데이트"
- (1) 한 episode가 다 끝나지 않아도 time step마다 학습 가능 ⇒ "bootstrapping"
- (2) 주변의 state들의 state value function을 사용하여 업데이트
- TD Target : R_t+1 + r Q(S_t+1)
- TD Error : R_t+1 + r Q(S_t+1) - Q(S_t)"
- ⇒ [Update value Q(St) toward estimated return R_t+1 + r Q(S_t+1)]
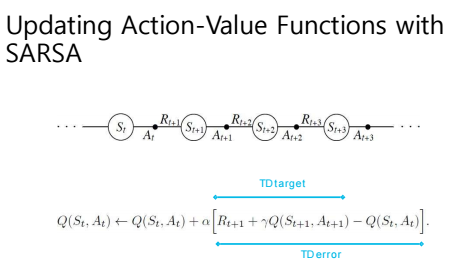


⇒ using policy derived from Q : 이 말이 즉 현재 Policy로 움직이면서 Policy evaluate하겠단 뜻=On Policy
3. Off Policy
※ Off Policy VS On Policy

- On-policy learning : 움직이는 policy와 학습하는 policy가 같은 것 / 현재 Policy 위에서 control (prediction + policy improvement) 모두 하는 것
→ But, 현재 알고 있는 정보에 대해 greedy로 policy를 정해버리면 optimal에 가지 못 할 확률이 커지기 때문에 탐험이 힘들다!
⇒ agent는 탐험이 필요하다!
- Off-policy learning : 움직이는 policy와 학습하는 policy가 분리하여 하는 것
- 다른 agent나 사람을 관찰하고 그로부터 학습할 수 있다
- 이전의 policy들을 재활용하여 학습할 수 있다.
- 탐험을 계속 하면서도 optimal한 policy를 학습할 수 있다.(Q-learning)
- 하나의 policy를 따르면서 여러 개의 policy를 학습할 수 있다.

※ Importance Sampling
⇒ "Important Sampling이란 개념이 있기에 다른 policy로부터 현재 policy를 학습할 수 있다!"
- 어떤 값을 추정할 때, 중요한 부분을 알아서 그 위주로 탐색을 하면 더 빠르고 효율적으로 값을 추정할 수 있다
- p와 q라는 다른 distribution이 있을 때 q라는 distribution에서 실제로 진행을 함에도 불구하고 p로 추정하는 것처럼 할 수 있다!→ value function = expected future reward를 계속 추정해나가는데 P(X)라는 현재 policy로 형성된 distribution으로부터 학습을 하고 있지만, 다른 Q라는 distribution을 따르면서도 똑같이 학습할 수 있다!
- ⇒ 다음과 같은 식 변형을 통해 !!
- → 강화 학습에서도 policy가 다르면 state의 distribution은 달라지게 되어 있다

1) Off Policy MC prediction

- 실제로 행동을 선택하는 behavior policy μ
- policy improvement의 대상이 되는 target policy π
- MC의 update 식에서 Gt는 μ를 따를 때의 reward들을 시간에 따라 discounting하여 더한 것 → update할 때 target policy에 대한 return값으로 변형해줘야 함!
- 에피소드가 끝나고 return을 계산할 때 위와 같이 식을 변형!
- 각 스텝에 reward를 받게 된 것은 $μ$라는 policy를 따라서 얻었던 것이므로 매 step마다 π/$μ$를 해줘야 함
- $μ$가 0이 되면 쓸 수 없다 ⇒ Off Policy MC는 좋지 않다...
2) Off Policy TD prediction
⇒ "Off Policy TD with Value Function"

- MC 때와는 달리 Importance Sampling을 1-step만 진행
- MC때와 비교하면 Variance가 낮아지나 여전히 높다
⇒ "Q-Learning"으로 해결!
⇒ Off-Policy TD와 Off-Policy MC 모두 각각의 모든 state에 대해 importance sampling이 필요하기에, 반드시 모든 step에 대해서 importance weight을 곱해주는 과정이 필요하다
3) Off-Policy TD Control = Q-Learning
⇒ "Off Policy TD with Action Value Function"

- 현재 state S에서 action을 선택하는 것은 behaviour policy를 따라서 선택
- TD에서 udpate할 때는 one-step을 bootstrap하는데 이 때 다음 state의 action을 선택하는 데 alternative policy 사용
⇒ 이렇게 하면 Importance Sampling 필요 없음 ($μ$로 값 안 나눠도 되니까 문제 해결!)
⇒ 이전의 Off-Policy에서는 Value function을 사용했었는데 여기서는 action-value function을 사용함으로서 다음 action까지 선택을 해야 하는데 그 때 다른 policy를 사용한다는 것!

- Behaviour policy : e-greedy w.r.t. Q(s,a)
- Target policy(alternative policy) : greedy w.r.t. Q(s,a)
+) 여기서의 **e-greedy w.r.t. Q(s,a)**는 이전의 e-greedy 방식이 학습이 진행될 수록 수렴 속도가 느려져 학습 속도가 느려지게 되는 단점을 보완하기 위해, epsilon을 시간에 따라 decay시키는 방법을 사용함


- SARSA의 TD target 부분과 Q-Learning의 TD target부분의 차이 주목!
- SARSA(On Policy TD Control)의 경우 TD target R_t+1 + $\gamma$Q(S_t+1,A_t+1)
- Q-Learning(Off Policy TD Control)의 경우 TD target R_t+1 + $\gamma$maxQ(S_t+1, a)

- SARSA는 on-policy(학습하는 policy와 움직이는 Policy 같음)라서 그렇게 Cliff에 빠져버리는 결과로 인해 그 주변의 상태들의 value를 낮다고 판단
- Q-learing의 경우에는 비록 e-greedy로 인해 Cliff에 빠져버릴지라도
자신이 직접 체험한 그 결과가 아니라greedy한 policy로 인한 Q function을 이용해서 업데이트 → Cliff 근처의 길도 Q-learning은 optimal path라고 판단할 수 있다!
4. Eligibility Traces
1) n-step TD ( ... TD prediction )
⇒ one step만 보고서 update를 하는 것이 아니고 "n-step을 움직인 다음에 update를 하자!"

- step 하나마다 update가 아니라 n개 step마다 update!
- ⇒ TD는 time-step마다 학습할 수 있는 장점은 있었지만 또한 bias가 높고 학습 정보가 별로 없기 때문에 TD와 MC의 장점을 둘 다 살리기 위한 방법으로 n-step TD !
- n이 terminal state까지 가면 Monte Carlos 방식이 된다


⇒ 문제점: 어떤 n이 적절한지 판단하기 어려움
⇒ 해결책: 여러 n-step TD를 합하면 각 n의 장점을 다 취할 수 있다!
→ 평균 내어 더하기

2) Forward-View of TD ( ... TD prediction )
⇒ 단순히 평균보다는 "$\lambda$라는 weight를 사용해서 geometrically weighted sum을 이용"!

- $\lambda$라는 weight를 사용해서 geometrically weighted sum을 이용
- $\lambda$=1, MC
- $\lambda$=0, TD
- 모든 n-step을 다 포함하면서 다 더하면 1이 나온다
- TD(λ) 식에서 Weighting의 정도는 1- λ이며, step이 진행될수록 λ만큼 decay 되는 것으로 해석할 수 있다
- $\lambda$-return을 원래 MC의 return에 넣어주면 forward-view TD가 된다
3) n-step SARSA ( ... TD control )
- 위에서는 TD Prediction, n-step SARSA는 TD control!
- Sarsa에도 n-step Sarsa가 있고 forward-view Sarsa($\lambda$)가 있고 backward-view Sarsa($\lambda$)가 있습니다
728x90'AI > Reinforcement Learning' 카테고리의 다른 글
강화학습 Chapter 07) Deep Reinforcement Learning (0) 2025.07.19 강화학습 Chapter 06) Value Function Approximation (0) 2025.07.19 강화학습 Chapter 04) Model-free Prediction (0) 2025.07.19 강화학습 Chapter 03) Model-based Planning (0) 2023.04.12 강화학습 Chapter 02) Markov Decision Process (0) 2023.04.12