-
GPT-1 / BERT / GPT-2 간단 정리AI/NLP 2022. 2. 7. 12:59728x90
GPT-1 / BERT / GPT-2 간단 정리
[논문 목록]
GPT-1 : Improving Language Understanding by Generative Pre-Training (2018)
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding (2018)
GPT-2 : Language Models are Unsupervised Multitask Learners (2018)
[목차]
1. GPT-1
2. BERT
3. GPT-2
4. GPT와 BERT의 특징 차이
GPT-1
0. Abstract
1. Introduction
2. Related work
3. Framework
3.1. Unsupervised pre-training
3.2. Supervised fine-tuning
3.3. Task-specific input transformations
4. Experiments
4.1. Setup
4.2. Supervised fine-tuning
5. Analysis
6. ConclusionGPT-1 (Generative Pretraining)
⇒ unsupervised pre-training과 supervised fine-tuning을 결합한 semi supervise approach! / generative model 사용 / transformer의 decoder 사용 !
→ 미분류 데이터로부터 언어적 정보를 얻어낼 수 있는 모델이 필요!
* 기존 방안의 한계
- 원본 그대로의 텍스트에서 효과적으로 학습하는 능력 (기존 language model)
⇒ But, 자연어처리는 넓은 분야의 task를 수행하는데 이를 위한 학습 데이터가 부족하다 / 따라서 기존의 LM은 변화를 최소화한다
- 미분류 텍스트에서 단어 수준 정보 이상을 얻기 어렵다
- 어떤 최적화 목적함수가 transfer에 유용한 텍스트 표현(representation)을 배우는 데 효과적인지 불분명
- 학습된 표현을 다른 과제로 전이하는 최적의 방법 존재하지 않음
⇒ 약간의 조정만으로도 넓은 범위의 과제에 전이 및 적용할 수 있는 범용 표현을 학습하는 것!
⇒ Transformer의 Decoder를 사용한다!1) Unsupervised Pretraining
→ 큰 corpus에서 대용량의 LM을 학습
- 이전 K개의 토큰을 통해서 현재의 토큰이 무엇인지를 예측하는 과정을 반복 (Masked Decoder Attention의 역할)
→ Transformer의 Decoder사용 (Encoder-Decoder attention은 제거)


GPT-1의 Decoder GPT의 Decoder 블록을 자세히 보면 Encoder 쪽에서 보내오는 정보를 받는 모듈(Multi-Head Attention) 역시 제거돼 있음을 확인할 수 있다~

Transformer의 Decoder / Masked Decoder Attention (Decoder에서 사용) : 각각의 출력 단어가 앞쪽에 등장한 출력 단어 참고 / Encoder Decoder Attention (Decoder에서 사용) : Query가 Decoder 에 있고 각각의 Key와 Value는 Encoder 에 있는 상황 - n-gram 목적 함수 사용
: 첫번째 학습단계 unsupervised pre-training은 unlabeled token 를 통해 일반적인 언어모델의 목적함수 Likelihood 를 최대화 하는 과정!

1. 우선 input token Matrix U에 embedding Matrix We를 곱한 후, Positional embedding Wp를 더해 Masked self-Attention을 위한 input h0을 만든다

2. GPT는 n개의 decoder가 stack 되어 있는 형태. 본 논문에서는 12개의 decoder block을 사용.
l번째 decoder block의 hidden state 은 이전 decoder block의 hidden state 를 입력으로 받아 계산한다.

3. 마지막 n번째 decoder block의 hidden state output 에 다시 transposed embedding Matrix 를 곱하여 softmax 함수를 적용하면 output probability P(u)를 계산.

4. 위의 과정으로 모델링한 조건부 확률 P(u)를 통해 앞서 말씀드린 를 최대화하며 사전학습이 진행.

최종적으로 다음과 같은 구조를 가지게 된다

2) Supervised Fine-Tuning
→ 분류 데이터를 사용하여 특정 과제에 맞춰("traversal style approach") 모델을 Fine tuning함

- 두 가지 목적 함수 1) Classification 목적함수와 2) Language Modeling 목적함수를 사용한다
1. Classification 목적 함수

2. Language Modeling 목적 함수
- pretraining시에 썼던 n-gram기반 목적함수! - 학습 속도를 빠르게 하기 위해서

=> 두개의 목적함수를 병합하여 사용함, 병합하는 비율은 hyperparameter로 둔다
1. input token sequence 과 label 로 구성된 target task의 labeled dataset 를 통해 학습 진행. 우선 의 input token에 대한 GPT의 마지막 decoder block hidden state 을 얻기위해 앞선 단계에서 얻은 pretrained model에 input token들을 통과.
2. 그리고 파라미터 를 갖는 하나의 linear layer에 을 통과시켜 softmax probability 를 계산.

3. 이 결과로 token probability distribution을 얻을 수 있고, 따라서 label 에 대해서 지도학습을 진행.
지도학습의 목적함수 Likelihood 또한 일련의 구조로 모델링된 조건부확률 를 통해 계산.

4. 저자들은 또한 unsupervised pre-training의 목적함수 1을 supervised fine-tuning을 위한 auxiliary objective로서 추가. 이 때 기존의 L1은 unlabeled dataset 에 대한 )로 계산되었지만, auxiliary objective로서 1은 Labeled dataset C에 대해 로 계산. 는 1(C)의 반영 정도를 정하기 위한 weight hyper parameter다.
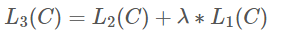
Reference
https://dongchans.github.io/2019/117/
내맘대로 논문 요약하기 - OpenAI GPT
OpenAI GPT는 최근 1년간 핫한 Bert를 소개하는 논문에서 비교군으로 등장한 모델 중에 하나입니다.
dongchans.github.io
https://lsjsj92.tistory.com/617?category=792966
GPT-1 논문 리뷰 - Improving Language Understanding by Generative Pre-Training paper review
포스팅 개요 본 포스팅은 OpenAI에서 발표한 자연어 처리(NLP) GPT 논문 시리즈 중 첫 번째 Improving Language Understanding by Generative Pre-Training (GPT-1) 논문을 리뷰하는 포스팅입니다. 논문이 나온지..
lsjsj92.tistory.com
https://supkoon.tistory.com/23
[자연어처리][paper review] GPT-1 : Improving Language Understanding by Generative Pre-Training
많은 딥러닝 모델들은 지도학습 형태로 이루어져 있으며, 일반화를 위한 상당한 양의 labeled data를 필요로 합니다. 따라서 labeled data의 부족은 지도학습 기반 딥러닝 모델의 적용을 어렵게 하는
supkoon.tistory.com
22. GPT(Generative Pre-trained Transformer) (new!)
2022년 1월 작성을 시작했습니다. :)
wikidocs.net
Python, Machine & Deep Learning
Python, Machine Learning & Deep Learning
greeksharifa.github.io
BERT
- pretrain된 모델을 가지고 fine tuning(다른 작업에 대해서 파라미터 재조정을 위한 추가 훈련 과정)한 모델
- ELMo나 GPT-1과 마찬가지로 문맥을 반영한 임베딩(Contextual Embedding)을 사용
- Transformer의 Encoder만 사용

ELMo는 정방향 LSTM과 역방향 LSTM을 각각 훈련시키는 방식으로 양방향 언어 모델 / GPT-1은 트랜스포머의 디코더를 이전 단어들로부터 다음 단어를 예측하는 방식으로 단방향 언어 모델 / BERT는 화살표가 양방향으로 뻗어나가는 모습 → 이는 마스크드 언어 모델(Masked Language Model)을 통해 양방향성을 얻음 ⇒ 1) Transformer의 encoder를 쌓아올린 구조 + 2) Positional Embedding + 3) Segment Embedding !

BERT-Base는 GPT-1과 하이퍼파라미터 동일하게 하여 성능을 비교하기 위해 / BERT-Large는 BERT의 최대 성능을 보여주기 위하여 
BERT의 12개의 층을 거친 후 출력된 각 단어의 임베딩은 입력된 문장의 모든 단어들을 참고하였음(= 문맥 정보를 가지게 된다! ) 1) BERT의 각 층은 Transformer의 Encoder!
- Encoder Self Attention (Encoder에서 사용) : 각각의 출력 단어가 모든 출력 단어 전부를 참고

*) Embedding & Token
- BERT에서 사용하는 Token
1. [CLS] token
: at the beginning of the input sequence / 문장 시작 부호 / 두 문장이 실제 이어지는 문장인지 아닌지 [CLS] 토큰의 위치의 출력층에서 이진 분류 문제로 해결
Hidden state corresponding to [CLS] will be used as the sentence representation (ℝ768×1 )
2. [SEP] token
: used to mark the end of a sentence / 문장을 구분하기 위한 토큰
3. 기타 token (얘는 seq2seq 모델에서 사용됨)
[EOS] token : End of sentence
[UNK] token : 사전을 구축하고 출현 빈도가 낮은 단어들을 모두 대체
[GO] token : 문장의 시작에
[PAD] token : 문장의 길이를 맞춰주기 위해 뒤에 추가!
[MASK] token : 가리기
- Embedding
- WordPiece Embedding : 실질적인 입력이 되는 워드 임베딩. 임베딩 벡터의 종류는 단어 집합의 크기로 30,522개.
- Position Embedding : 위치 정보를 학습하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 길이인 512개.
- Segment Embedding : 두 개의 문장을 구분하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 개수인 2개.2) Position Embedding
↔ Transformer의 Positional Encoding
⇒ Positional Embedding은 위치정보를 sin과 cos 함수가 아닌 " 학습을 통해 얻는다!"

1. 위치 정보를 위한 Embedding layer을 추가
2. BERT의 입력마다 Word Embedding Vector + Positional Embedding Vector
3) Segment Embedding
⇒ QA 등과 같은 두 개의 문장(또는 문서/문단) 입력이 필요한 경우, 문장을 구분하기 위해서 사용!

- 첫번째 문장에는 Sentence 0 임베딩, 두번째 문장에는 Sentence 1 임베딩을 더해주는 방식!
1. BERT의 Pretraining
⇒ 사전 훈련 방식 크게 두 가지로 나뉨! 1) Masked LM 2) Next Sentence Prediction(NSP, 다음 문장 예측)
⇒ 마스크드 언어 모델과 다음 문장 예측은 따로 학습하는 것이 아닌 loss를 합하여 학습이 동시에 이루어진다!
(1) Masked Language Model
→ 사전 훈련을 위해서 인공 신경망의 입력으로 들어가는 입력 텍스트의 15%의 단어를 랜덤으로 마스킹!
- 80% 단어 [MASK]로 대체
- 10% 단어 랜덤으로 대체
- 10% 그대로 둔다
ex1)
- dog' 토큰이 [MASK]로 변경되어서 BERT 모델이 원래 단어를 맞춘다
- 출력층에 있는 다른 위치의 벡터들은 예측과 학습에 사용되지 않고, 오직 'dog' 위치의 출력층의 벡터만이 사용
- 출력층에서는 예측을 위해 단어 집합의 크기만큼의 밀집층(Dense layer)에 소프트맥스 함수가 사용된 1개의 층을 사용하여 원래 단어가 무엇인지를 맞추게 됨

ex 2)
- 'dog' 토큰은 [MASK]로 변경 / 'he'는 랜덤 단어 'king'으로 변경 / 'play'는 변경되진 않았지만 예측에 사용

(2) Next Sentence Prediction (NSP, 다음 문장 예측)
→ 두 개의 문장을 준 후에 이 문장이 이어지는 문장인지 아닌지를 맞추는 방식으로 훈련!
- 이어지는 문장의 경우
- Sentence A : The man went to the store.
-Sentence B : He bought a gallon of milk.
- Label = IsNextSentence
- 이어지는 문장이 아닌 경우
- Sentence A : The man went to the store.
- Sentence B : dogs are so cute.
- Label = NotNextSentence

- BERT의 입력으로 넣을 때에는 [SEP]라는 특별 토큰을 사용해서 문장을 구분
- 이 두 문장이 실제 이어지는 문장인지 아닌지를 [CLS] 토큰의 위치의 출력층에서 이진 분류 문제를 풀도록 함
2. BERT의 Fine Tuning (Testing)
(1) 하나의 텍스트에 대한 텍스트 분류 유형(Single Text Classification)
(2) 하나의 텍스트에 대한 태깅 작업(Tagging)

- Named Entity Recognition 문제에 사용
(3) 텍스트의 쌍에 대한 분류 또는 회귀 문제(Text Pair Classification or Regression)

- 자연어 추론 문제(Natural language inference)란, 두 문장이 주어졌을 때, 하나의 문장이 다른 문장과 논리적으로 어떤 관계에 있는지를 분류하는 것
- 모순 관계(contradiction), 함의 관계(entailment), 중립 관계(neutral)
(4) 질의 응답(Question Answering)

- 질문과 본문을 입력받으면, 본문의 일부분을 추출해서 질문에 답변하는 것
ex)
- 질문 : "강우가 떨어지도록 영향을 주는 것은?"
- 본문 : "기상학에서 강우는 대기 수증기가 응결되어 중력의 영향을 받고 떨어지는 것을 의미합니다. 강우의 주요 형태는 이슬비, 비, 진눈깨비, 눈, 싸락눈 및 우박이 있습니다."
- 정답 : "중력"
Reference
https://lsjsj92.tistory.com/618?category=792966
BERT 논문 정리(리뷰)- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding paper review
포스팅 개요 본 포스팅은 Google에서 발표한 자연어 처리(NLP) 논문 중 BERT(BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding) 논문을 리뷰한 포스팅입니다. 앞서 GPT-1 논문..
lsjsj92.tistory.com
17. BERT(Bidirectional Encoder Representations from Transformers)
트랜스포머(transformer)의 등장 이후, 다양한 자연어 처리 태스크에서 사용되었던 RNN 계열의 신경망인 LSTM, GRU는 트랜스포머로 대체되어가는 추세입니다. 이 ...
wikidocs.net
02) 버트(Bidirectional Encoder Representations from Transformers, BERT)
* 트랜스포머 챕터에 대한 사전 이해가 필요합니다.  BERT(Bid ...
wikidocs.net
GPT-2
Abstract
1. Introduction
2. Approach
2.1. Training Dataset
2.2. Input Representation
2.3. Model
3. Experiments
3.1. Language Modeling
3.2. Children’s Boot Test
3.3. LAMBADA
3.4. Winograd Schema Challenge
3.5. Reading Comprehension
3.6. Summarization
3.7. Translation
3.8. Question Answering
4. Generalization vs Memorization
5. Related Work
6. Discussion
7. Conclusion
8. Appendix A: Samples
8.1. Model capacity
8.2. Text Memorization
8.3. Diversity
8.4. Robustness⇒ GPT1에서 나아가 더 범용적인 LM을 만들자!
→ " Fine Tuning 없이 적용 + Zero shot Learning + Byte Pair Encoding (BPE) "
1) Byte Pair Encoding (BPE)
→ 서브워드를 분리하는 알고리즘으로, 빈도수에 따라 문자를 병합하여 서브워드를 구성!
- Byte Pair Encoding를 거친 토큰을 입력 단위로 사용!
- 단어를 문자(char) 단위로 쪼갠 뒤, 가장 빈도수가 높은 쌍을 하나로 통합하는 과정을 반복하여 토큰 딕셔너리를 만든다
→ FastText에서 그랬듯이 OOV 문제 해결 !
2) Fine-Tuning 없이 적용
→ GPT-1과 달리, 지도 학습이 없는 상태로 만들어진다면 일반 상식 추론 등의 다양하게 범용적으로 사용할 수 있을 것
3) Zero shot learning
- model이 바로 downstream task에 적용
- downstream task : 구체적으로 하고자 하는 task (QA , Classification 등 ..)
- 위의 Fine Tuning, 즉 supervised learning을 없앴기 때문에 다양하게 범용적으로 사용할 수 있음
↔ one-shot learning / Few-shot learning : 모델이 1개 또는 몇개의 데이터에 맞게 업데이트
[ GPT-2에서의 Zero Shot Learning 수행 방법 ]
GPT-2에서 zero-shot으로 생성하기 위해 TL;DR: 라는 annotation을 첨가해서 100개의 토큰을 생성했다.Reference
https://hyyoka-ling-nlp.tistory.com/8
All about GPT-2 : 이론부터 fine-tuning까지(1)
OpenAI의 GPT-2는 NLG(Natural Language Generation)에서 가장 탁월한 성능을 보인다고 알려져 있습니다. 소설을 작성하는 데모를 제공함으로써 그 뛰어난 능력을 세상에 알렸죠. 그래서 흔히 소설쓰는 인공
hyyoka-ling-nlp.tistory.com
https://lsjsj92.tistory.com/620
GPT-2 논문 정리(논문 리뷰) - Language Models are Unsupervised Multitask Learners paper review
포스팅 개요 이번 포스팅은 자연어 처리(NLP) 논문 중 GPT-2(Language Models are Unsupervised Multitask Learners) 논문에 대한 리뷰를 작성하는 포스팅입니다. 앞서 GPT-1, BERT에 이어서 자연어 처리 논문 시..
lsjsj92.tistory.com
Python, Machine & Deep Learning
Python, Machine Learning & Deep Learning
greeksharifa.github.io
https://modulabs-hub.oopy.io/db1871c6-75b1-4229-a86b-72516d4b735f
Language Models are Unsupervised Multitask Learners (GPT-2)
GPT-2
modulabs-hub.oopy.io
GPT와 BERT의 특징 차이
GPT
(Generative Pre-trained Transformer)BERT
(Bidirectional Encoder Representations from Transformers)정의 Language Model
- 이전 단어들이 주어졌을 때 다음 단어가 무엇인지 맞추는 과정에서 pretrain
- 문장 시작부터 순차적으로 계산한다는 점에서 일방향(unidirectional)Masked Language Model
- 문장 중간에 빈칸을 만들고 해당 빈칸에 어떤 단어가 적절할지 맞추는 과정에서 pretrain
- 빈칸 앞뒤 문맥을 모두 살필 수 있다는 점에서 양방향(bidirectional)강점 문장 생성 문장의 의미 추출 사용 Block Transformer의 Decoder Transformer의 Encoder Reference
https://ratsgo.github.io/nlpbook/docs/language_model/bert_gpt/
BERT & GPT
pratical tips for Natural Language Processing
ratsgo.github.io
728x90'AI > NLP' 카테고리의 다른 글