-
[Story Generation Study Week 01 : Fundamental of Text Generation] GPT-3 : Language Models are Few-Shot Learners (2020) ReviewAI/NLP 2022. 6. 28. 12:41728x90
[Story Generation Study Week 01 : Fundamental of Text Generation]
GPT-3 : Language Models are Few-Shot Learners (2020) Review
[Story Generation Study Week 01 : Fundamental of Text Generation]
GPT-1: Improving Language Understanding by Generative Pre-Training (2018)
GPT-2: Language Models are Unsupervised Multitask Learners (2019)
GPT-3: Language Models are Few-Shot Learners (2020)
22.06.28 워크샵 끝나고 12시까지 남은 개노답 GPT 세자매. 이 중에서 막내를 맡고 있다. 방학 중 내가 너무너무너무 궁금했던 Story Generation Study가 열리게 되었다! 신난다...!
첫 주 스터디에는 Text Generation의 기본에 대해서 하기로 했고, GPT-3를 맡게 되었다.
겸사겸사 오랜만에 블로그에 복습도 할 겸 들어와보니, GPT-2까지만 정리했어서 이번 기회에 GPT-3도 정리하고자 한다.
들어가기 전에 ...
이전에 간단히 정리한 블로그 글이 있지만, 이번에 스터디를 준비하면서 이 글 또한 많이 부족하다고 느껴진다. 스터디에서 발표해주실 내용들 잘 정리해서 다시 올려야겠다
GPT-1 / BERT / GPT-2 간단 정리
GPT-1 / BERT / GPT-2 간단 정리 [논문 목록] GPT-1 : Improving Language Understanding by Generative Pre-Training (2018) BERT : Pre-training of Deep Bidirectional Transformers for Language Unders..
asidefine.tistory.com
[GPT-1 : Improving Language Understanding by Generative Pre-Training (2018)]
: unsupervised pre-training과 supervised fine-tuning을 결합한 semi supervise approach!
: generative model 사용 == transformer의 decoder 사용 !
[ 기존 방안의 한계 ]
1) 원본 그대로의 텍스트에서 효과적으로 학습하는 능력 (기존 language model)
→ But, 자연어처리는 넓은 분야의 task를 수행하는데 이를 위한 학습 데이터가 부족하다 / 따라서 기존의 LM은 변화를 최소화한다
2) 미분류(unlabeled) 텍스트에서 단어 수준 정보 이상을 얻기 어렵다
→ 어떤 최적화 목적함수가 transfer에 유용한 텍스트 표현(representation)을 배우는 데 효과적인지 불분명
→ 학습된 표현을 다른 과제로 전이하는 최적의 방법 존재하지 않음
⇒ 약간의 조정만으로도 넓은 범위의 과제에 전이 및 적용할 수 있는 범용 표현을 학습하는 것!
⇒ (1) Unsupervised Pretraining + (2) Supervised Fine-Tuning
[ 1. Unsupervised Pretraining ]
: 이전 K개의 토큰을 통해서 현재의 토큰이 무엇인지를 예측하는 과정을 반복 (Masked Decoder Attention의 역할)
→ Transformer의 Decoder사용 (Encoder-Decoder attention은 제거)
: n-gram 목적 함수 사용
- 첫번째 학습단계 unsupervised pre-training은 unlabeled token u={u1,...,un}를 통해 일반적인 언어모델의 목적함수 Likelihood L1(u)를 최대화 하는 과정!
[ 2. Supervised Fine-Tuning ]
: 분류 데이터를 사용하여 특정 과제에 맞춰("traversal style approach") 모델을 Fine tuning함
→ 두 가지 목적 함수 1) Classification 목적함수와 2) Language Modeling 목적함수를 사용한다
⇒ 두 개의 목적함수를 병합하여 사용함, 병합하는 비율은 hyperparameter로 둔다
[3. Task Specific Input Transformations]
: Classifcation, Entailment, Similarity, Multiple Choice 등 서로 다른 task에 대해서 입력 형태 또한 다르기 때문에 구분자(delimiter)로 구분하여 하나로 연결하는 방식으로 입력 형태와 모델 형태가 달라지게 된다
[GPT-2: Language Models are Unsupervised Multitask Learners (2019)]
: GPT1에서 나아가 더 범용적인 LM을 만들자!
→ " 1) Fine Tuning 없이 적용 + 2) Zero shot Learning + 3) Byte Pair Encoding (BPE)"
[1. Byte Pair Encoding (BPE)]
→ 서브워드를 분리하는 알고리즘으로, 빈도수에 따라 문자를 병합하여 서브워드를 구성!
- Byte Pair Encoding를 거친 토큰을 입력 단위로 사용!
- 단어를 문자(char) 단위로 쪼갠 뒤, 가장 빈도수가 높은 쌍을 하나로 통합하는 과정을 반복하여 토큰 딕셔너리를 만든다
→ FastText에서 그랬듯이 OOV 문제 해결 !
: 이미 미세 조정한 모델은 해당 task외에는 사용할 수 없다는 문제점이 존재
[ 2. Fine-Tuning 없이 적용 ]
→ GPT-1과 달리, 지도 학습이 없는 상태로 만들어진다면 일반 상식 추론 등의 다양하게 범용적으로 사용할 수 있을 것
[ 3. Zero shot learning ]
- model을 바로 downstream task에 적용
- 위의 Fine Tuning, 즉 supervised learning을 없앴기 때문에 다양하게 범용적으로 사용할 수 있음
↔ one-shot learning / Few-shot learning : 모델이 1개 또는 몇개의 데이터에 맞게 업데이트
GPT-3
논문이 무려 70장이 넘어간다...! 다 읽을 엄두는 안 나서 중요한 일부만 기록하고자 한다.
[목차]
Abstract
1. Introduction
2. Approach
2.1 Model and Architectures
2.2 Training Dataset
2.3 Training Process
2.4 Evaluation
3. Results
3.1. Language Modeling, Cloze, and Completion Tasks
3.2. Closed Book Question Answering
3.3. Translation
3.4. Winograd-Style Tasks
3.5. Common Sense Reasoning
3.6. Reading Comprehension
3.7. SuperGLUE
3.8. NLI
3.9. Synthetic and Qualitative Tasks
4. Measuring and Preventing Memorization Of Benchmarks (벤치마크를 외웠는지 측정하고 예방하기)
5. Limitations
6. Broader Impacts
7. Related Work
8. Conclusion
Appendix A: Details of Common Crawl Filtering
Appendix B: Details of Model Training
Appendix C: tails of Test Set Contamination Studies
Appendix D: Total Compute Used to Train Language Models
Appendix E: Human Quality Assessment of Synthetic News Articles
Appendix F: Additional Samples from GPT-3
Appendix G: Details of Task Phrasing and Specifications
Appendix H: Results on All Tasks for All Model Sizes Refenrences Citation논문의 목차만 봐도 삶이 팍팍해지지만, 본 포스트에서는 인간적으로 요약하고자 한다.
Abstract & Introduction
Approach
Results
Limitations
ConclusionAbstract & Introduction
- 최근의 Language Model 연구들은, 대규모의 Corpus에서 Pretrain + 특정 Task에 Fine Tuning하는 방법을 통해 큰 발전을 이룩함

⇒ 위와 같이, 대부분의 Task에서 잘 작동하는 모델들을 Task-agnostic Model이라 한다
- 하지만 이런 Task-agnostic Model들도 다음과 같은 3가지 한계점이 존재한다
1. 자연어의 각 task에 대한 대용량의 labeled data가 매번 필요하다는 것은 실용적인 관점에서 매우 비효율적임
→ 심지어 몇몇 NLP Task는 labeling하는 데 드는 비용이 큼
2. pretrian된 대규모의 모델을 다시 적은 데이터로 fine-tuning하는 것은 매우 협소한 task에 대해 fine-tuning되는 것이기에(characterized) 일반화된(generalized) 성능을 잃게 된다
→ 이미 fine-tuning한 모델은 해당 task에 Overfitting되기 때문에 다른 Task에는 사용할 수 없다는 문제점이 존재 → 일반화 성능↘ / spurious correlations일 가능성 크다
(↔ GPT-1에서의 contribution이 약간의 조정만으로도 넓은 범위의 과제에 전이 및 적용할 수 있는 범용 표현을 학습하는 것! 과는 사뭇 대조적이다)
3. 인간은 실제로 새로운 Language Task를 배울 때 적은 데이터를 이용하여 충분히 학습 가능함 (agnostic)
→ 예시 1: 이 문장이 기쁜 혹은 슬픈 무언가를 말하는지 선택하라.
→ 예시 2:여기 용감한 행동을 하는 사람 예시 2개가 있다. 용감한 행동의 세 번째 예시를 들라
↔ 현재 Task-agnostic Model들은 이것이 불가능하다 ( 대부분이지 다 잘하진 않잖어~ )- 위의 한계점들을 GPT-3에서는 아래와 같은 방법으로 해결하고자 한다.
1. labeled data가 부족하다 ? → unlabeled data로 학습하면 된다 (Unsupervised Learning)
2. Fine-tuning이 일반화 성능을 잃게 한다 ? → Fine-tuning하지 않으면 더욱 범용적이고 일반화된 모델 될 것이다!
3. 적은 Labeled Data로 인간과 비슷한 학습하고 싶어? → Few Shot / Zero Shot Learning 으로 진행해보자 !⇒ 위의 모든 걸 해결할 단 두 가지의 방법: " Meta Learning ! " + "Parameter 늘리기!"
전작인 GPT-2에서 이미 Meta Learning 방식이 적용이 되었다.

Meta-Learning은 학습 과정에서 다양한 스킬과 패턴인식 능력을 동시에 키워, Inference 단계에서 원하는 task에 빠르게 적응할 수 있도록 모델을 학습시키는 방법이다.

GPT-3에서는 GPT-2와 마찬가지로 Metra-learning의 한가지 방법인 'in-context learning'을 통하여 학습되었다.
in-context learning은 원하는 task에 대한 간단한 설명을 함께 Input하여 주는 방법이며,
in-context learning은 모델의 context window에 주어지는 예시의 개수에 따라 One-shot, Zero-shot, Few-shot 환경으로 구별 될 수 있다. 본 논문에서는 Meta-learner로서의 성능을 검증하기 위하여 24개 이상의 데이터셋 환경에서 GPT-3를 앞선 세가지 조건(Zero, One, Few)으로 검증했다.
바로 아래에서 더 자세히 살펴보도록 하겠다.
Approach
논문에서는 Model 설명에 앞서서, in-context learning을 위한 실험 세팅 4가지를 figure와 함께 설명해준다.
in-context learning의 방법도 GPT-2와 비슷하지만, GPT-3에서는 Zero-shot, One-shot, Few-shot의 조건으로 in-context learning을 세분화한다.
GPT3 입력은 [task description, [SEP], examples, [SEP], prompt :]의 형태이며 출력은 prompt에 알맞은 token sequence이다. 즉, example 수가 많아지면 모델의 성능이 더 좋아지며, task description과 example들을 어떻게 주느냐가 모델의 성능에 영향을 주게 된다.하나씩 살펴보자면,....
- Fine-tuning (FT)
- Few Shot (FS)
- One Shot (1S)
- Zero Shot (0S)

(1) Fine-tuning 방식

Fine-tuning 방식은 비교를 위해 실험을 하고 실제 GPT-3에서는 쓰이진 않는다. Introduction에서 누차 말했듯이 Fine-tuning 방식에는 여러 한계가 존재한다.(2) Few-shot learning

task description과 함께 모델의 context window에 K개의 예시를 보여준다. 하지만 예시를 사용하여 가중치를 업데이트 하지 않는다.
물론 Few Shot Learning을 하면 Labeled Data 확보에 대한 부담감을 덜 수 있고, Fine Tuning 방식보다는 덜 Overfitting된다는 장점이 있지만,
역으로 단점을 짚자면, 여전히 Labeled Data를 확보해야 하며, Fine Tuning 방식보다는 성능이 다소 떨어진다.
GPT-2의 Down-stream tasks in Zero-shot setting의 가능성을 보고 Few-shot setting으로 발전시켜 fine-tuning 없이도 좋은 성능을 낼 수 있도록 하였다.
(3) One-shot learning

모델의 context window에 1개의 예시만을 사용한다는 것을 제외하고는 Few-shot과 동일한 특징을 가지고 있다.
그러나, Introduction에서 살펴봤던 세번째 한계점을 생각해봤을 땐, 이 One-Shot Learning이 가장 인간의 학습 방법과 유사하다고 볼 수 있다.
(4) Zero-shot learning

모델의 context window에 예시를 보여주지 않고, Task에 대한 설명만을 넣어준다.
Zero-shot learning은 극도의 편의성을 제공하는 동시에(Unlabeled Data만 넣어주면 되니까) robustness 능력을 제공하고, spurious correlation을 피할 수 있게 해준다.
하지만 Zero-shot 환경은 예시 없이 설명만으로 이루어지기 때문에 가장 어려운 조건이다. 어떤 경우에는 인간에게 마저도 어려운 작업이다. Fine-tuning에 비해서 성능은 저조할 수 있지만, 인간 능력과의 비교를 위해서는 향후 One-shot 혹은 Zero-shot에 대한 결과는 중요도가 높다.1) Model and Architectures

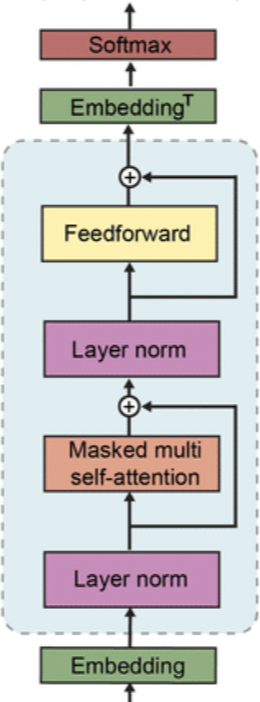
GPT-1 / GPT-2 / GPT-3의 Decoder Block 

GPT-3은 GPT-2의 모델 구조를 그대로 차용하지만, 차이점을 살펴보자면,
- 모델의 크기, 데이터셋의 크기, 다양성, 학습 횟수를 전반적으로 늘렸다.
- Dense와 locally banded sparse attention을 번갈아가며 사용한다. (sparse transformer에서 따옴)


column이 input, row가 output이다. 각 output은 제한된 개수의 input token에만 attention을 볼 수 있고, strieded 와 fix의 경우 그 구현이 조금 다르다. [ sparse transformer ]
이것 역시 OpenAI의 연구로, Transformer 가 가지고 있는 문제점인 과도한 메모리 사용을 줄일 수 있는 방안이라고 한다.
이미지나 Audio와 같이 요소의 수가 엄청 큰 데이터에 대해서 Attention을 적용하게 된다면, 각각의 layer 마다 NxN attention matrix 와 attention head 를 필요로 하게 되어 메모리 요구량이 엄청 많아지게 되는 문제를 해결하고자 한다.
각각의 출력 중에서 입력들의 일부 서브셋만 계산하는 sparse attention pattern을 적용하는 것으로, 서브셋이 상대적으로 적으면 매우 긴 sequence 에도 무리 없이 적용 가능해서 성능을 올릴 수 있다고 한다.
간단히 말하자면, 일정한 패턴을 두고 Attention을 적용하는 것이다.
가장 큰 모델인 GPT-3 175B(1750억) 버전을 최종적으로 GPT-3이라고 부른다 전작인 GPT-2가 1.5B 파라미터를 가졌던 것에 비해 무려 100배가 넘게 몸집을 키웠다.
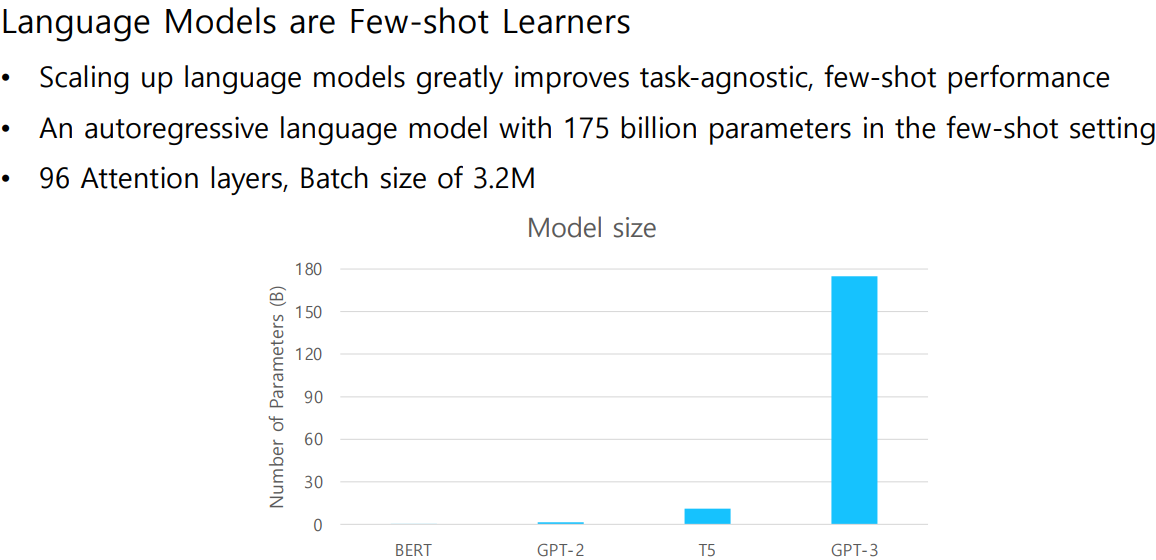
2) Training Dataset
GPT-3의 학습을 위해 사용된 최종 dataset의 구성 비율이며,
학습과정에서는 구성 비율이 아닌 데이터셋의 품질에 비례한 확률로 샘플링을 진행했다.
자세한 사항은 논문을 참고...
3) Training Process
- learning rate & batch size
- 큰 모델은 큰 batch size와 작은 lr이 필요하다. 위의 Table 2.1 참고
- Adam, β1 = 0.9, β2 = 0.95
- clip_by_global_norm = 1.0
- learning rate -> cosine decay (down to 10%)
- linear LR warmup = first 375 million tokens
- weight decay = 0.
Results
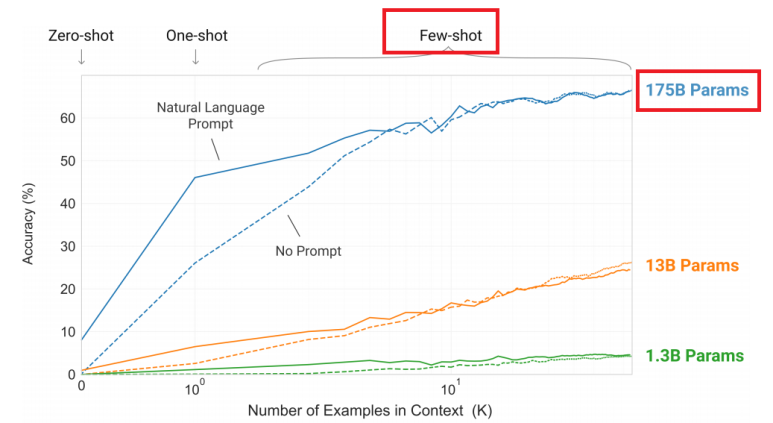
아래의 그래프를 보면 제로샷 러닝과 원샷 러닝을 사용할 때보다 퓨샷 러닝을 사용할 때 정확도가 좋음을 알 수 있음. 마찬가지로 파라미터 수가 1750억개인 파란색 그래프의 경우 가장 정확도가 좋음.

저자들은 데이터셋들을 아래와 같이 9개의 NLP task로 분류하여 모델 크기에 따른 cross-entropy 개선이 광범위한 NLP task의 성능 향상에 일관되게 관여하고 있음을 검증했다.
1. Language Modeling, Cloze, and Completion Tasks
2. Closed Book Question Answering
3. Translation
4. Winograd-Style Tasks
5. Common Sense Reasoning
6. Reading Comprehension
7. SuperGLUE
8. NLI
9. Synthetic and Qualitative Tasks아래에서 각 Task에 대한 설명과 함께 결과도 함께 보겠다. GPT-1에서 진행했던 것에 비해 더욱 실험이 풍성해짐을 알 수 있다.
모든 Results에서 공통적으로 모델의 크기가 커질수록 성능도 함께 올라감을 확인할 수 있다.(1) Language Modeling, Cloze, and Completion Tasks
(2) Closed Book Question Answering
Closed Book QA는 광범위한 지식에 관한 문제에 대해 Context 없이(Closed book) 답변을 생성하는 Task

One-Shot과 Few-Shot 환경에서 Fine-tuning 기반의 SOTA모델을 능가 (3) Translation
Translation은 GPT-2의 성능이 좋지 못했던 Task인데, 역시 GPT-3에서도 같은 문제를 가지고 있다.
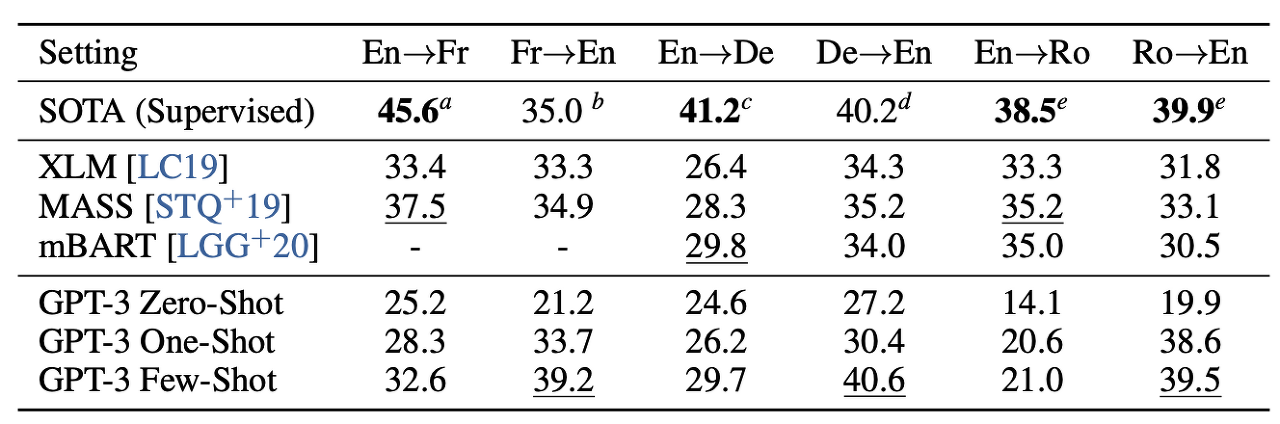

BLEU score를 통해 비교하였을 때, 역시 기존의 SOTA 모델에는 미치지 못하는 성능을 보임.
저자들은 GPT-2 모델의 BPE encoding이 영어에 맞지 않기 때문에 이러한 현상이 발생하는 것이라고 주장했다.
(개인적인 생각으로는 Bi-directional하지 못해서 의미를 제대로 파악하지 못하는 게 아닐까? 라는 생각..)
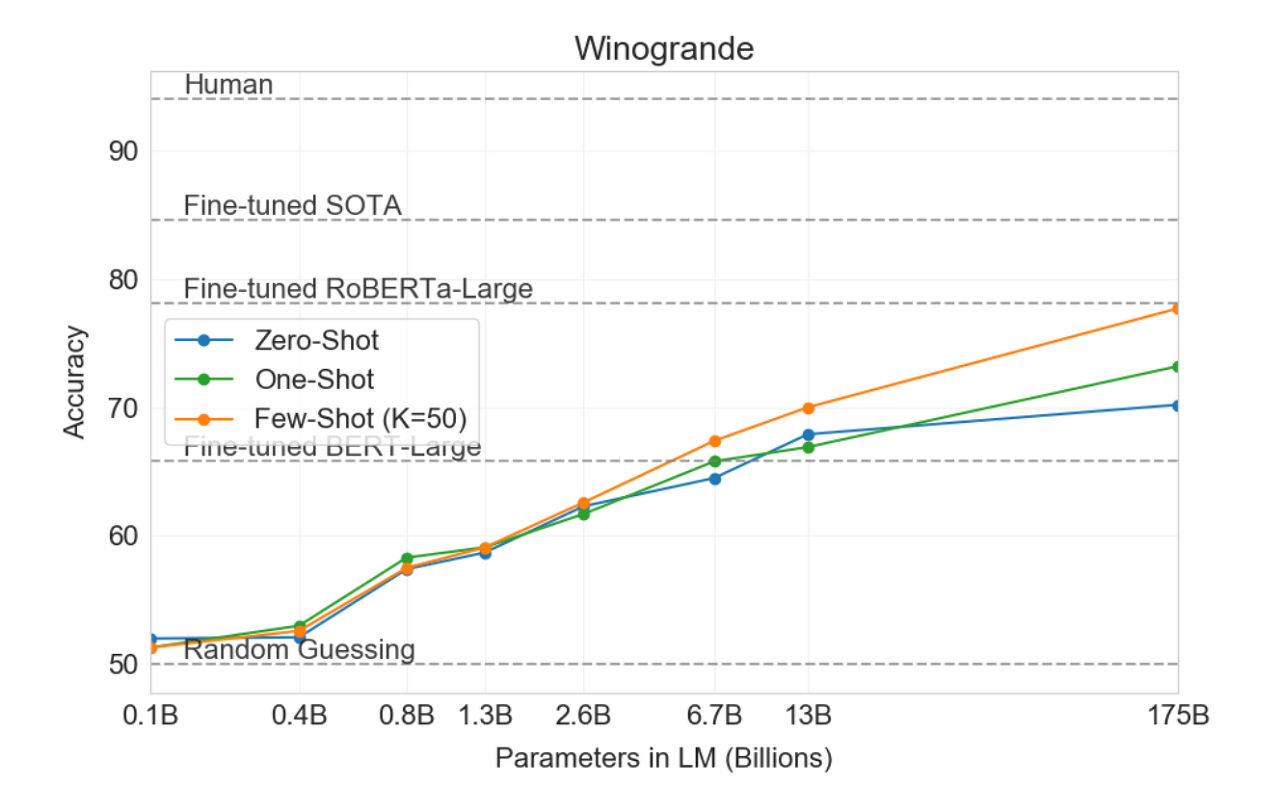
(4) Winograd-Style Tasks
Winograd는 대명사가 지칭하는 것을 맞추는 작업으로, 문법적으로는 매우 모호하지만(ambiguous) 인간에게는 전혀 모호하지 않은 작업이다.
Winograd task를 통해 모호성을 해소시키위한 추론 능력을 확인할 수 있다.마찬가지로 기존의 SOTA 모델에는 미치지 못하는 성능을 보임.

(5) Common Sense Reasoning
PhysicalQA는 물리학적인 이해와 세상에 대한 전반적인 이해를 묻는 Task.
GPT-3는 기존의 Fine-tuning기반 SOTA모델의 성능을 Zero-shot 환경에서도 능가했다,
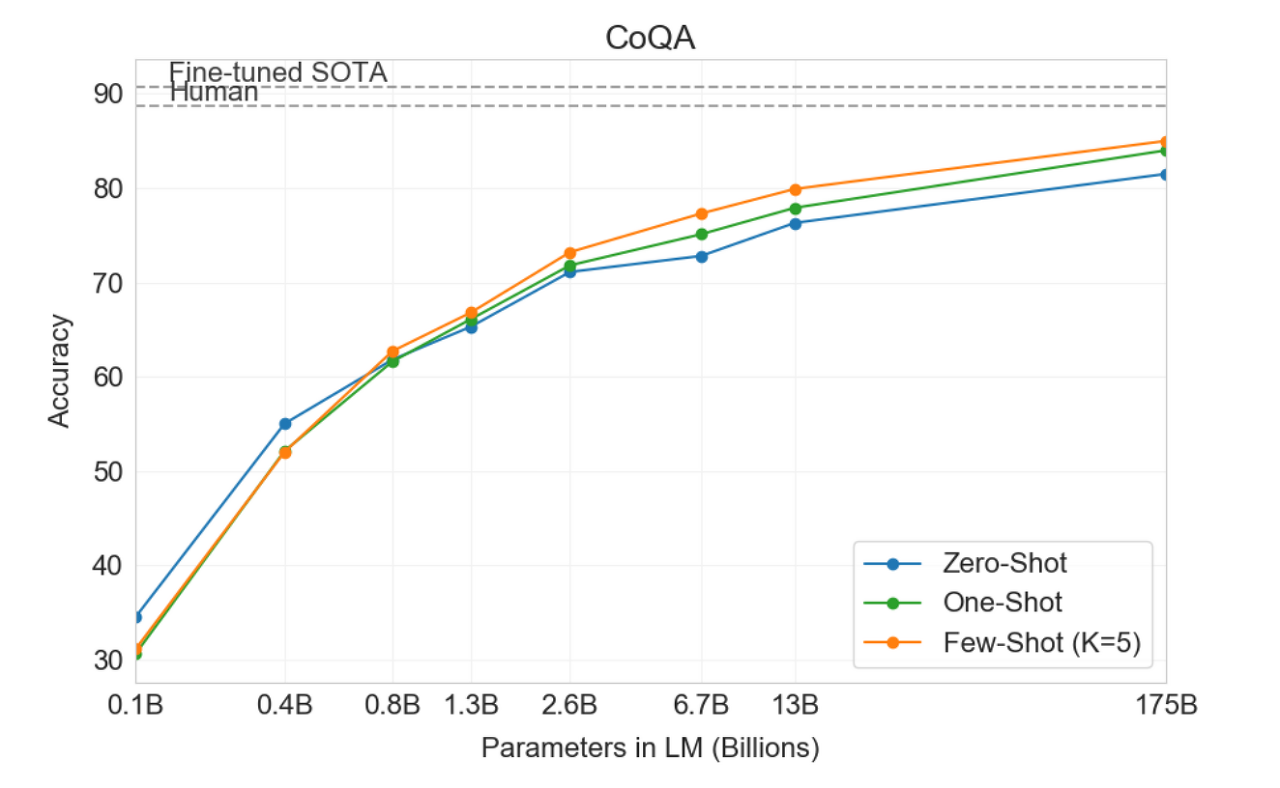
(6) Reading Comprehension
Reading Comprehension task는 모델의 독해력을 평가하기 위한 Task
자유형식 대화를 다루는 데이터셋은 CoQA에서는 인간 능력에 가까운 좋은 성능을 보여주었다.
하지만 대화의 주제, 형식에 따라 성능이 매우 저조하거나 편차가 큰 경우가 존재했다.
(7) SuperGLUE
SuperGLUE는 다양한 벤치마크 데이터셋을 포함하고 있는 Task
GPT-3와 BERT계열 fine-tuning 모델의 성능을 면밀하게 비교해보기 위하여 진행했다고 한다.
SOTA를 달성하지는 못하였으며, 일부는 비슷하거나 떨어지는 성능을 보였다.

(8) NLI
NLI는 두 문장 사이의 인과관계를 포착할 수 있는 능력을 판단하기 위한 Task
앞선 문장에 따라 다음 문장이 논리적으로 참인지,모순인지,중립인지를 판단하는 분류를 풀게 된다.
아쉽게도 가장 큰 모델의 Few-shot setting을 제외하고는 찍기와 같이 형편없는 결과를....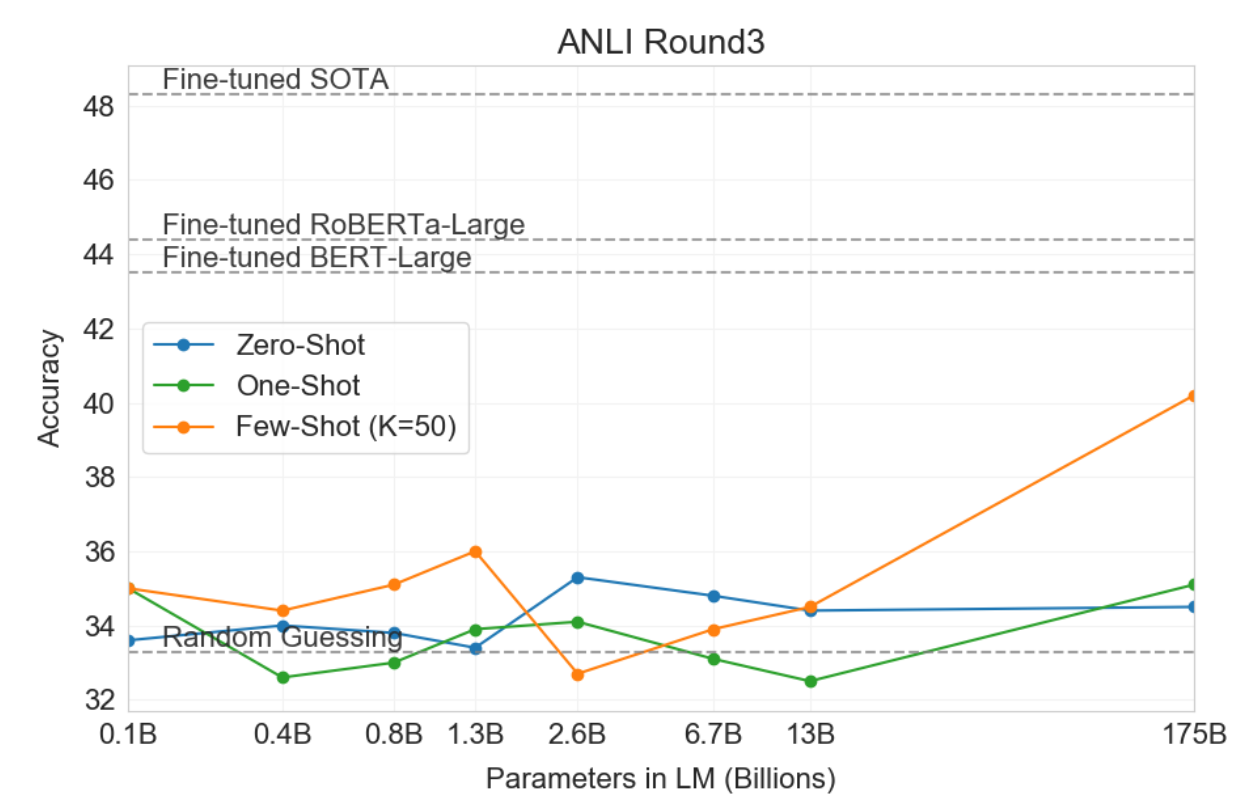
(9) Synthetic and Qualitative Tasks
GPT-3의 Few-shot 성능을 증명할 수 있는 가장 좋은 방법은 계산과 같이 학습 데이터셋에서 잘 등장하지 않는 새로운 패턴을 찾거나 빠르게 적응해야 하는 작업을 하는 것
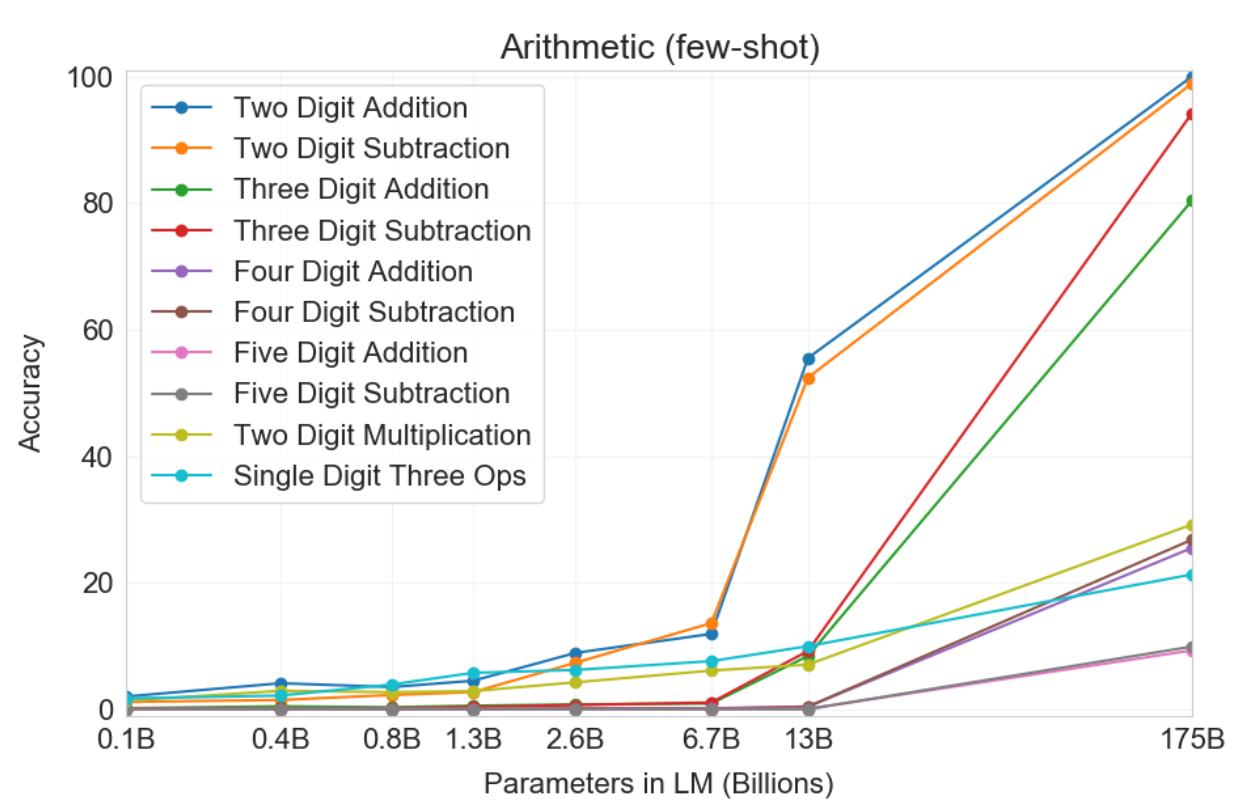
Arithmetic
Fine-tuning없이 간단한 수학계산을 하는 task에서 GPT-3는 주목할만한 성능을 보였다.
두 자릿수, 세 자릿수 덧샘, 뺄샘의 경우 Few-shot 환경에서 거의 100%에 가까운 성능을 확인할 수 있다.
모델 크기에 따라 성능이 증가했으며, 가장 큰 GPT-3 모델의 경우 전반적으로 합리적인 계산 능력을 갖출 수 있었다.

Word Scrambling and Manipulation tasks
Word Scrambling and Manipulation은 몇가지의 문자조작을 포착하는 능력을 확인하는 작업


SAT Analogies
SAT Analogy는 일반적인 text distribution에서 벗어난 문제 해결을 실험해 보기 위해 진행
SAT 시험의 다지선다 문제를 풀게 됨

이 외에도 다양한 Task 진행...
Limitations
GPT-3의 한계점으로는 7개를 정의할 수 있다.
- 성능적 한계
- 구조와 알고리즘의 한계
- 근본적인 한계
- 훈련의 비 효율성
- Few-shot learning의 불확실성
- 비용
- 설명 가능성
- Few-shot in-context learning의 성능적 한계
- 텍스트 생성 시 문단 수준에서 동일한 내용을 반복하는 경우
- 간단한 물리학 상식 분야를 잘 풀지 못함
- "치즈가 냉장고에 있으면 녹을까?"
- 독해능력 떨어짐
- 구조와 알고리즘의 한계
- GPT 계열의 모델들은 Transformer의 Decoder block으로 구성되었기 때문에 Bi-directional하지 못함
- 만약 GPT-3와 비슷한 크기의 bidirectional 모델이 있었다면?
- 향후 연구 : GPT-3 규모의 bidirectional 모델 / Few-shot, Zero-shot 기반의 bidirectional 모델
- GPT-3에서는 de-noising을 고려하는 목적함수를 설정하지 않음
- GPT 계열의 모델들은 Transformer의 Decoder block으로 구성되었기 때문에 Bi-directional하지 못함
- 근본적인 한계
- 최근 언어 모델들은 "Scaling Up"에 집중하고 있음
- 즉, 언어 모델 자체의 근본적인 문제보다는 모델과 데이터의 크기에만 집중
- Pre-training 과정에서 기존의 목적함수는 본질적인 한계가 존재
- 현재의 목적함수는 모든 토큰에 동일한 가중치를 부여하며, 어떠한 토큰이 덜 중요한지, 더 중요한지를 고려하지 못하고 있음
- 최근 언어 모델들은 "Scaling Up"에 집중하고 있음
- 훈련의 비 효율성
- GPT-3는 Pre-training 동안 인간이 한평생 보는 것 보다 많은 양의 텍스트를 학습
- 인간의 학습을 모델링하는 측면에서 효율적이지 못한 훈련
- GPT-3는 Pre-training 동안 인간이 한평생 보는 것 보다 많은 양의 텍스트를 학습
- Few-shot learning의 불확실성
- GPT-3의 성능이 잘 나오는 것이 Few-shot Learning 때문인지, 아니면 훈련 과정에서 이미 해당 문제를 학습했기 때문인지 불명확
- 인간의 학습에서도 마찬가지. 예시를 통해 학습했는지 과거에 이미 학습했는지 불분명
- GPT-3의 성능이 잘 나오는 것이 Few-shot Learning 때문인지, 아니면 훈련 과정에서 이미 해당 문제를 학습했기 때문인지 불명확
- 비용
- GPT-3에 대한 Train Cost와 Inference Cost가 매우 크다
- 실제로 사용하기 위해선 Distilation 과정이 필요하지만, 현재는 이런 대규모 모델을 Distilation할 수 없다.
- Distilation이란? : 크고 무거운 모델의 정보(Knowledge)를 작고 가벼운 모델로 전달하여 작고 가벼운 모델이 더 정확한 추론을 하도록 학습시키는 방법론
- 설명 가능성
- GPT-3 역시 Black Box이기에 예측값에 대한 설명력이 떨어진다
- 새로운 input에 대한 Variance가 큼에도 불구하고, Data 자체에 대한 Bias를 해결하지 못한다
Conclusion
- GPT 모델을 모두 요약하자면...
GPT-1 GPT-2 GPT-3 Transformer decoder + LM objective pretraining Meta-learning을 통한 zero-shot 학습 & 추론 크기를 엄청나게(175B) 키움 - GPT-3을 요약하자면....
- 기존 LM의 한계를 극복하기 위하여, Meta Learning의 한 가지 방법인 in-context learning의 효율성을 One-shot, Zero-shot, Few-shot 환경을 통해 검증하였으며
- 또한 1750억개의 파라미터를 가진 거대 LM을 구축했다
- 다양한 Task들에 대한 실험으로 GPT-3의 강점, 약점 그리고 한계에 집중하는 동시에 언어모델의 few-shot learning에 대한 전반적인 연구를 포함했다
- 개인적 감상
Reference
http://arxiv.org/abs/2005.14165
Language Models are Few-Shot Learners
Recent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically task-agnostic in architecture, this method still requires task-specific fi
arxiv.org
https://supkoon.tistory.com/27
[자연어처리][paper review] GPT-3 : Language Models are Few-Shot Learners
Attention Mechanism과 Transformer의 등장, 그리고 대용량 corpus에서의 pre-training과 task-specific Fine-tuning으로 학습하는 언어모델은 근래에 대부분의 NLP task 성능을 몰라보게 끌어올렸습니다. 이러한..
supkoon.tistory.com
[GPT3] 주요 내용 정리
GPT 모델은 auto-regressive 모델 계열 중 하나이며 특히 GPT3는 transformer 계열 언어모델의 크기에 따른 성능을 매우 잘 보여주었다. 본 글에서는 GPT3 논문의 주요 내용 및 궁금했던 점들을 정리하고자
soundprovider.tistory.com
GPT 모델의 발전 과정 그리고 한계
GPT란 무엇인가?
medium.com
https://amber-chaeeunk.tistory.com/98
[NLP] GPT-2 , GPT-3 , ALBERT , ELECTRA
지난 포스팅에서 다룬 Self-supervised Pre-training Model GPT-1, BERT에 이어서 Advanced Self-supervised Pre-training Model GPT-2, GPT-3, ALBERT, ELECTRA에 대해 살펴볼 것이다. https://amber-chaeeunk.t..
amber-chaeeunk.tistory.com
https://velog.io/@tobigs-nlp/GPT-3-Language-Models-are-Few-Shot-Learners
GPT-3: Language Models are Few-Shot Learners
패러다임의 변화! GPT3! | 15기 조효원
velog.io
https://jaeyoon-95.tistory.com/180
Language Models are Few-Shot Learners
논문 https://arxiv.org/pdf/2005.14165.pdf Github https://github.com/openai/gpt-3 이 논문은 GPT-3에 대한 논문입니다. 등장 배경 GPT-3는 아래와 같은 기존 모델들의 한계점들을 해결하기 위해 제안되..
jaeyoon-95.tistory.com
Python, Machine & Deep Learning
Python, Machine Learning & Deep Learning
greeksharifa.github.io
728x90'AI > NLP' 카테고리의 다른 글
