-
[Story Generation Study Week 03 : Story Generation & Story Completion] Story Realization: Expanding Plot Events into Sentences (AAAI, 2020) ReviewAI/NLP 2022. 6. 29. 16:15728x90
[Story Generation Study Week 03 : Story Generation & Story Completion]
Story Realization: Expanding Plot Events into Sentences (AAAI, 2020) ReviewSummary
[2주차 논문 Remind]
0. Event Representation : 각 문장을 Event의 형식으로 표현한 것

1. event2event : 하위의 여러 event represnetation 생성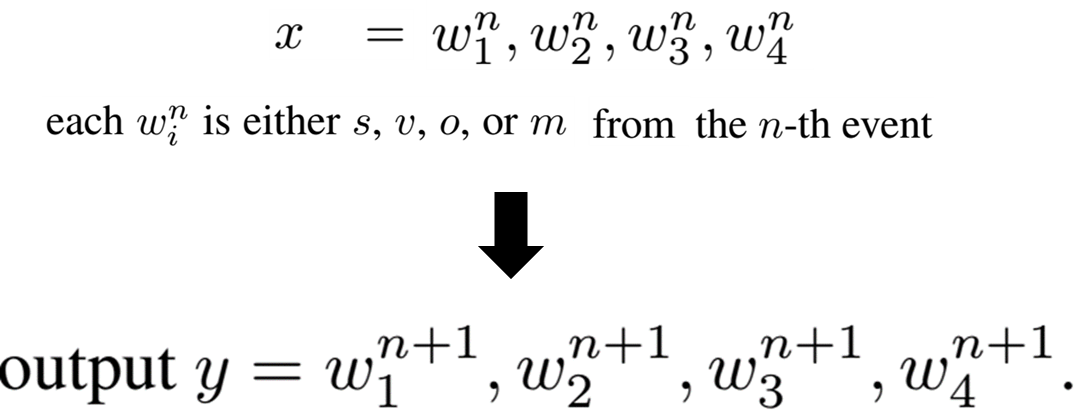
2. event2sentence : 추상적인 event → 인간이 읽을 수 있는 자연스러운 문장으로 translate
원본 : https://asidefine.tistory.com/195- Event Representation은 Story Generation task의 성능을 높이는 데 효과적이다
- 하지만 이 Event Representation은 unreadable하고 abstract함
- (1) 구문적+의미적으로 잘 구성되고, (2) 원본 이야기의 의미와 흥미를 이어나갈 수 있는 문장으로 번역할 필요 있음
- 이 논문에서는 4개의 event-to-sentence 모델을 앙상블하는 방식 소개
- 각 모델들은 서로의 취약점을 잘 보완하고 교정해주더라
- 결국 실제 사람이 만든 듯한 이야기 잘 생성해냈음
Introduction
- Automated story plot generation 발전 과정
- Early work : Symbolic planning, case-based reasoning
- 최근 : Neural-based Approaches!
- Neural-based Approaches
- 장점 : 도메인 특화된 모델링을 하지 않아도 됨
- 단점 : story corpus에서 각 문장이 한번씩만 등장한다는 문제 존재 (Sparsity of Events)
- 이 문제 해결하기 위해 2주차 논문 등장 → Event Representation 방식으로 해결하고자 함
- Event Representation : event-to-event + event-to-sentence (2주차 논문)
- 문제점 1
- event-to-event 모델은 과거에 봤던 event만 생성하는 경향 있어서,
- 그 결과가 event-to-sentence 모델로 들어가면 예상하지 못한 결과 나올 때 있음
- 문제점 2
- 각 문장들이 전체 corpus에서 딱 한 번만 있을 가능성 높음
- 그 문장들은 Event Representation으로 바꿔도 아직 Sparsity of Event 문제를 해결하는 데 한계 있음
- 문제점 1
" we framed the event-to-sentence task as guided language generation, using a generated event as a guide. "
- Contributions
- ensemble 기반의 Event-to-Sentence 시스템 제시
- Event의 원래 의미 유지하는 것과 전체 story의 흥미 유지 간의 밸런스 유지하기 위해
- baseline model(seq2seq / 2주차 논문)보다 우리의 our system for guided language generation이 성능 더 좋더라
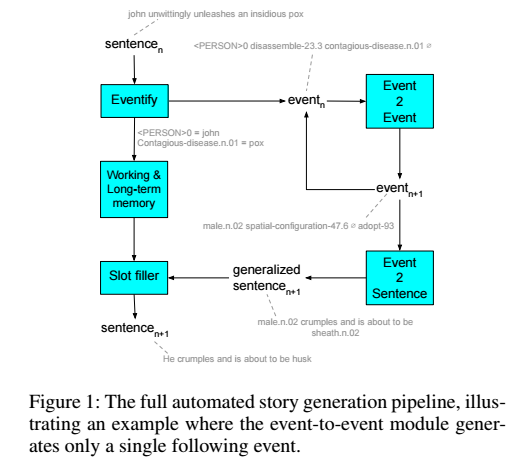
- a full end-to-end story generation pipeline 제시 (figure 1)
- ensemble 기반의 Event-to-Sentence 시스템 제시
Event-to-Sentence
- 이 논문에서는 4개의 Event-to-Sentence 기법을 앙상블함 !
- Retrieve-and-Edit
- Sentence Templating
- Monte-Carlo Beam Search
- Finite State Machine Constrained Beams / Standard beam search
1. Retrieve-and-Edit (RetEdit)
- Retriever Model
- 먼저 각 이벤트를 출력 문장을 재구성할 수 있는 임베딩에 매핑하도록 인코더-디코더 훈련을 통해 이벤트 튜플 간의 작업별 유사성을 학습
- Retriever Model 을 사용하여 train set에서 가장 가까운 이웃 이벤트와 해당 문장을 검색
- Editor Model
- 입력 이벤트와 위에서 검색된 event-sentence example 쌍이 모두 주어졌을 때 빔 검색을 사용하여 목표 문장을 생성할 가능성을 최대화
- seq2seq 모델 사용
- 학습 및 훈련 과정
- 먼저 어휘가 부족한 단어에 대한 무작위 초기화를 사용하여 새로운 GLoVe 단어 임베딩 세트를 초기화
- train set를 사용하여 두 모델에 대한 가중치를 학습하고,
- valid set를 사용하여 모델에 대한 신뢰 임계값을 설정하고,
- test 세트를 사용하여 성능을 평가한다.
- 장점 및 단점
- 이 모델에 의해 생성된 많은 성공은 우리의 train corpus에 나타나는 복잡한 문장 구조를 유지하는 능력에서 비롯
- 일관성을 유지하는 것과 흥미로운 것 사이에서 균형을 유지하려고 시도
- 훈련 데이터와의 이러한 상호 작용은 이 방법의 주요 단점
- 훈련 데이터와 임베딩 공간에서 멀리 떨어져 있는 대상 이벤트는 일반적으로 문장의 품질을 저하시킴
- event에서 문장으로의 매핑은 일대일이 아니기 때문에 때때로 단일 이벤트에 매핑되는 여러 개의 문장이 존재하여 검색 거리가 0이 되는데, 이 경우 예제 문장은 수정 없이 반환
- 검색 거리가 낮을수록 신뢰도가 높아지기 때문에
- 이 모델에 의해 생성된 많은 성공은 우리의 train corpus에 나타나는 복잡한 문장 구조를 유지하는 능력에서 비롯
2. Sentence Templating
- 앞서 언급했듯이, baseline sequence-to-sequence network 종종 문장을 생성할 때 입력 이벤트를 무시할 수 있음
- 입력 이벤트 튜플이 POS로 이뤄진다는 것을 활용하여, 이벤트에서 생성된 문장의 구문에 대한 단순화된 문법을 구축함
- 결과 문장은 [___s]{v [___o] [p____m]이 될 것이며, 여기서 빈칸은 완전한 문장을 만들기 위해 단어를 추가해야 할 위치를 나타낸다.

- 입력 이벤트의 내용(몇 개의 인수가 채워지고 어떤 인수가 채워지는지)을 기반으로 가장 가능성이 높은 VerbNet 프레임을 예측
- VerbNet은 동사가 어떻게 사용되는지에 따라 다양한 동사 클래스에 대한 많은 구문 구조를 제공
- 입력 이벤트가 2개의 명사와 전치사가 없는 동사를 포함하는 경우, 출력 문장은 [NP V NP]의 형태를 취하지만, 2개의 명사와 동사와 명사를 가진 경우 [NP V PP]가 되어야 함
- 훈련 말뭉치의 일반화된 문장에 대해 훈련된 양방향 LSTM 언어 모델을 적용
- 어떤 단어가 주어지면, 위의 규칙 중 일부에서 주어진 특정 구절 내에서 그것의 앞뒤에 단어를 생성할 수 있고, 생성된 문장 조각들을 함께 연결할 수 있다
- AWD-LSTM 사용
- 디코딩 시, (1) 최대 길이에 도달하거나 (2) 명사 구에서 생성되는 동사를 보는 등 다음 구에서 요소를 나타내는 토큰을 생성할 때까지 각 구에서 단어를 계속 생성한다.
- 문장의 다양성을 높이기 위해, 문장의 일관성을 유지하기 위해 가장 가능성이 높은 상위 k개의 다음 단어에서 표본을 추출하고 많은 문법 관련 규칙을 시행한다.
- 예를 들어, 두 개의 한정사 또는 두 개의 명사가 서로 옆에 생성되는 것을 허용하지 않는다.
- 각 문장에 대한 모델의 신뢰도를 결정하기 위해 생성된 각 토큰 이후의 손실을 합산하고, 문장 길이로 정규화하고, 손실이 클수록 신뢰도가 낮아지기 때문에 1에서 뺀다
- 장점과 단점
- 장점
- 이벤트에서 제공된 토큰이 생성된 문장에 나타나도록 보장할 수 있다. (일관성을 유지하도록 최적화)
- 장점
3. Monte-Carlo Beam Search
- 이벤트 쌍과 일반화된 문장에 대한 sequence-to-sequence model을 훈련하고 디코딩 시 몬테카를로 빔 탐색을 실행한다.

- Selection
- 결국, 가장 높은 selection value를 가진 자식노드를 선택하여 이동하면된다
- Expansion
- selection 할 때, 다음에 이동해서 멈출 노드의 확률을 생성한다. 한 노드의 방문 횟 수가 threshold에 도달하면 대부분의 수행은 한 노드의 모든 자식노드의 확장을 하도록한다.
- Simulation
- expansion 과정에서 만들어진 노드로 부터 게임을 실행한다. 기본적으로 게임이 끝날 때까지 실행하며 random하게 선택하여 움직인다. 최종적으로, 어떤 플레이어가 이겼는지 track을 유지하여 backpropagation 과정으로 움직인다.
- Backpropagation
- 트리의 root로 다시 올라가는 과정이다. 각 확률 노드에 대해, "visit" count를 증가시킨다. 또한 현재 player가 승리한 부모노드에 대해 "win" count를 증가시킨다. 이 4개의 과정을 결정한 만큼이나 시간이 되는 데까지 반복한다.최종적으로 자식노드 중 win/visit count 비율이 가장 높은 쪽으로 움직이면 된다.
- 이 모델의 신뢰 점수는 최고 점수 end node의 최종 점수이다
- 장점과 단점
- 장점
- 다양한 출력을 생성하는 데 탁월, 즉 흥미로운 문장을 생성하는 쪽으로 치우친다
- 몬테카를로 빔 디코더는 기존의 빔 디코더보다 입력에 더 충실하면서도 앙상블의 다른 기술보다 문법적으로 더 정확한 더 나은 문장을 생성하는 것으로 나타났다
- 단점
- 모든 입력 이벤트 토큰이 최종 출력 문장에 포함된다는 보장은 없다
- 장점
4. Finite State Machine Constrained Beams
유한상태기계(finite state machine, FSM)
주어지는 모든 시간에서 처해 있을 수 있는 유한 개의 상태를 가지고 주어지는 입력에 따라 어떤 상태에서 다른 상태로 전환시키거나 출력이나 액션이 일어나게 하는 장치 또는 그런 장치를 나타낸 모델이다.
FSM 이란 특정한 상태를 정의하기 위한 개념적 모델이다.
여러 개의 제한된 상태(State)가 존재하고 그 존재들이 특정 조건에 물려 서로 연결되어있는 형태를 의미한다.- 다양한 형태의 빔 검색 (including Monte Carlo)은 입력 이벤트의 토큰이 출력된 문장에 나타나도록 보장할 수 없다
- 어휘 제약 조건에 맞게 알고리즘을 조정!
- 원하는 토큰을 생성하는 방향으로 안내하기 위해 finite state machines 사용
- 빔 검색 접근법의 전형적인 유연성과 문장 품질 사이의 균형을 달성하려는 동시에, 더 직접적인 접근 방식(예: 섹션 3.2)이 달성할 수 있는 입력 이벤트에 인코딩된 맥락과 스토리를 고수하려고 한다
- 생성된 문장에 입력 토큰의 존재를 강제하는 상태로 구성
- input event n-token : {t1, t2, t3, ..., tn}
- 2n개의 state 가짐
- 빔 크기에 해당하는 최대 b개의 출력 문장로 B 크기의 검색 빔을 유지
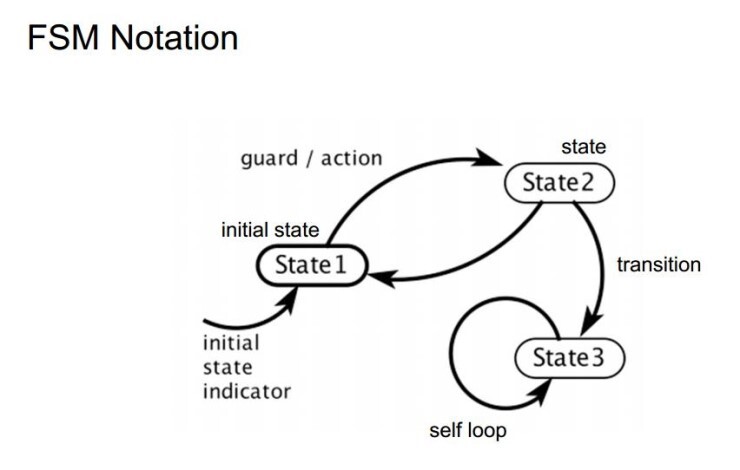
1. 외부에서 하나의 상태(입력 이벤트 토큰)가 기계 내부로 입력이 된다.
2. 현재 상태와 그 입력값에 대응하는 상태(출력 시퀀스)를 찾는다.
3. 그 상태로 전환하라고 기계 외부로 던져준다.
4. 외부에서 이를 받아 상태를 전이한다.- 각 단계에서, (초기 상태를 제외한) 이전 단계로부터 받은 모든 상태는 마지막으로 생성된 토큰이 입력 이벤트 토큰과 일치하는 출력 시퀀스를 명시한다.
- 그런 다음 상태는 수신된 출력 시퀀스로부터 가장 가능성이 높은 b를 빔에 추가한다.
- 토큰 t1을 생성하면 현재 상태가 초기 상태에서 t1, t3에 해당하는 상태로 전이하며, t3는 t3에 대한 상태로 전이한다. 상태 t1과 t3는 각각 토큰 t1과 t3을 생성한 후, 해당 문장를 상태 t1,3으로 전이한다. state와 transition은 입력 이벤트의 모든 토큰과 일치하는 최종 상태에 도달할 때까지 계속된다.
=> 최종 상태에서 완료된 문장은 모든 입력 이벤트 토큰을 포함하므로 이벤트의 의미론적 의미를 유지할 수 있는 기능을 제공한다.
- 장점과 단점
- 장점 : 어휘적 제약 조건을 만족시키는 좋은 문장을 생성하는 균형을 유지하는 데 기반 ( 생성된 문장이 모든 입력 토큰을 포함)
- 단점 : 적절한 문법과 구문을 잃거나 심지어 고정된 시간 범위 내에 최종 상태에 도달하지 못할 수도 있다.
- 입력 이벤트의 토큰 5개 중 적어도 3개가 일치하는 출력 시퀀스를 허용하도록 제약을 완화
5. Ensemble
- Cascade 방식으로 앙상블 ! (이전 단계 classifier의 결과값에서 얻은 모든 정보를 종속적으로 다음 단계의 classifier의 추가 정보로 활용하는 것)
- 각 모델의 출력 순위를 다시 매기기 위해 confidence score를 사용
- 한 단계에서 모델의 결과가 confidence score의 임계치를 넘지 못하면 다음 단계의 모델로 넘어감
- 개별 모델에 대한 신뢰 임계값이 충족될 경우 조기에 종료하고 출력 문장을 반환하기 때문에 계산을 절약
- retrieve-and-edit
- 먼저 문장과 confidence score 생성
- 검색 거리 측면에서 입력에 상대적으로 가까운 훈련 세트에서 샘플을 검색할 수 있을 때 잘 수행
- 데이터 세트의 희소성을 고려할 때 이는 비교적 낮은 확률로 발생하므로 이 모델을 시퀀스에 먼저 배치
- sentence templating
- 이벤트 내의 모든 토큰을 보유하므로 더 흥미로운 문장을 생성하는 것 대신 의미론적 의미를 전혀 잃지 않는다
- sentence templating 모델을 Monte Carlo 방식보다 먼저 함으로써, 사건의 의미론적 의미를 유지하는 목표에 암묵적으로 더 큰 중요성을 둔다.
- Monte Carlo beam search
- 이벤트 내에서 원래 토큰을 유지하는 것에 대해 보장하지 않지만 다양한 문장 세트를 생성할 수 있다.
- finite state constrained beam search
- confidence score 없음
- 이벤트 토큰을 사용하여 주어진 길이 내에서 문장을 생성하는 데 성공했다면 완료
- 어휘적 제약 조건을 만족시키는 좋은 문장을 생성하는 균형을 유지하는 역할
- standard beam search
- finite state constrained beam search가 문장을 생성하는 데 실패한 경우
- baseline sequence-to-sequence model with standard beam search decoding 사용
Dataset
- Story Generation 성능을 위해서 하나의 장르만 선택함 : Science Fiction
- SF 장편 드라마 plot의 요약본
- 다른 Dataset들(2018 AAAI - 2주차 발표)보다 더 길고 디테일한 요약본임
- 2276개의 이야기
- 각 이야기 당 평균 문장 개수 89.23
- 11개의 Show도 포함
- 닥터후, X-Files 같은..
- 각 Show 당 평균 207개 이야기
- 전처리
- 외계인 이름 간단하게 바꾸고
- "split-and-pruned" 방식으로 문장 나눔 (2018 AAAI - 2주차 발표)
- 장점 : 문장과 Event가 1:1 대응할 가능성 높아짐
- SF 장편 드라마 plot의 요약본
* S+P Sentence(split and prune sentences)
한 문장 당 하나의 Event 대신에 한 문장당 여러 이벤트로 표현한다! 전치사구 없애고, 접속사 단위로 쪼개고, .... 등의 방식으로 문장을 잘게 쪼갠다
예시
Original Sentence : Lenny begins to walk away but Sam insults him so he turnsand fires, but the gun explodes in his hand.
S+P Sentence :
Lenny begins to walk away. Sam insults him. He turns andfires. The gun explodes.
Experiments
- 2가지 실험 진행
- Event-to-Sentence 자체
- test 문장 eventify한 것을 다시 sentence로 잘 만드는지?
- 전체 Pipeline
- event-to-event system로 생성된 event sequences를 사용해서 실험
- generated event sequences를 generalized sentences로 바꾸는 실험
- generalized sentences는 slot filler를 거쳐 <PERSON>과 같은 entity tag에 올바른 단어 잘 채워넣게 된다
- Event-to-Sentence 자체

- 평가지표 ( + Event2Sentence 를 번역 task처럼 생각했지만 BLEU나 ROUGE는 creative generation tasks에 잘 맞지 않는다 )
- Perplexity
- BLEU-4 : Generated Sentence의 단어가 Reference Sentence에 포함되는 정도 (n-gram precision)
- ROUGE-4 : Reference Setence의 단어가 Generated Sentence에 포함되는 정도 (n-gram Recall)
Results

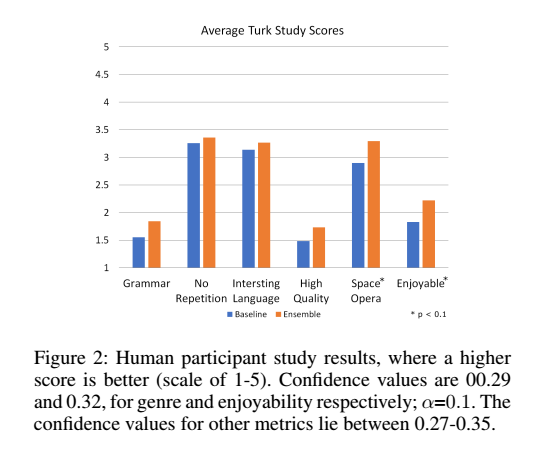
- Full Ensemble을 했을 때 Perplexity 제일 좋음
- 다른 모델들의 취약점 보완되어서 그렇다
- 평균 문장 길이는 다른 모델들과의 차이를 보려고 측정함
- Templates가 제일 짧고, finite state machine이 제일 긴데 이는 제약 조건 때문에 그렇다

- Ensemble 내에서도 어떤 모델이 자주 쓰이느냐 측정하고자 함
- Event-to-Sentence만 test할 때 (testing corpus eventify한 것 넣음 )
- 전체 pipeline
- Test
- RetEdit이 가장 많이 사용되었는데, 이유는 train과 test data의 분포가 비슷해서 그런 듯함
- Pipeline
- RetEdit이 test 때 비해 덜 사용되긴 하더라 training set과 event-2-event 결과로 나온 events들이 꽤 달라서 그런 듯함
- Monte Carlo beam search로 RetEdit의 떨어진 성능 보완한 듯

- Retrieve-and-edit
- 문장의 질을 희생하면서도, 의미에 중점 둠
- The sentence templates
- 입력 Event와 일치하지만, 매우 공식화된 output을 가짐
- Monte Carlo
- 재미있고 문법적으로 올바른 문장을 생성하지만 때때로 입력 이벤트의 의미를 잃어버린다.
- The finite state machine
- 의미과 entertaining output 생성 사이의 균형을 이루려고 시도하지만, 모델 자체의 제약 조건을 고려할 때 출력을 생성하지 못하는 경우가 있다.
Conclusion
- Event Representation은 각본 생성 task의 성능을 높이는 데 효과적이다
- 하지만 이 Event Representation은 unreadable하고 abstract함
- (1) 구문적+의미적으로 잘 구성되고, (2) 원본 이야기의 의미와 흥미를 이어나갈 수 있는 문장으로 번역할 필요 있음
- 이 논문에서는 4개의 event-to-sentence 모델을 앙상블하는 방식 소개
- 각 모델들은 서로의 취약점을 잘 보완하고 교정해주더라
- 결국 실제 사람이 만든 듯한 이야기 잘 생성해냈음
Reference
https://arxiv.org/abs/1909.03480
Story Realization: Expanding Plot Events into Sentences
Neural network based approaches to automated story plot generation attempt to learn how to generate novel plots from a corpus of natural language plot summaries. Prior work has shown that a semantic abstraction of sentences called events improves neural pl
arxiv.org
728x90'AI > NLP' 카테고리의 다른 글
- Event Representation은 Story Generation task의 성능을 높이는 데 효과적이다