-
LLM Alignment 방법 정리 (RLHF, DPO, KTO, ... )AI/NLP 2024. 4. 22. 10:23728x90
LLM Alignment 방법 정리 (RLHF, DPO, KTO, ... )

- Alignment란 AI 시스템을 인간의 목표, 선호도 및 원칙에 맞추어 조정하는 과정
- 인간의 윤리적 기준, 사회적 가치, 그리고 개별 사용자의 특정 요구를 반영하도록 조정하는 것을 포함
- 이런 Alignment를 잘 수행하기 위해 인간의 행동을 더 잘 반영하는 Loss Function들이 제시되었는데 이를 Human-Aware Loss Function (HALOs)라고 한다
- PPO, DPO, MTO 등이 여기에 해당한다
Reinforcement Learning with Human Feedback (RLHF) /
Reinforcement learning from AI feedback (RLAIF)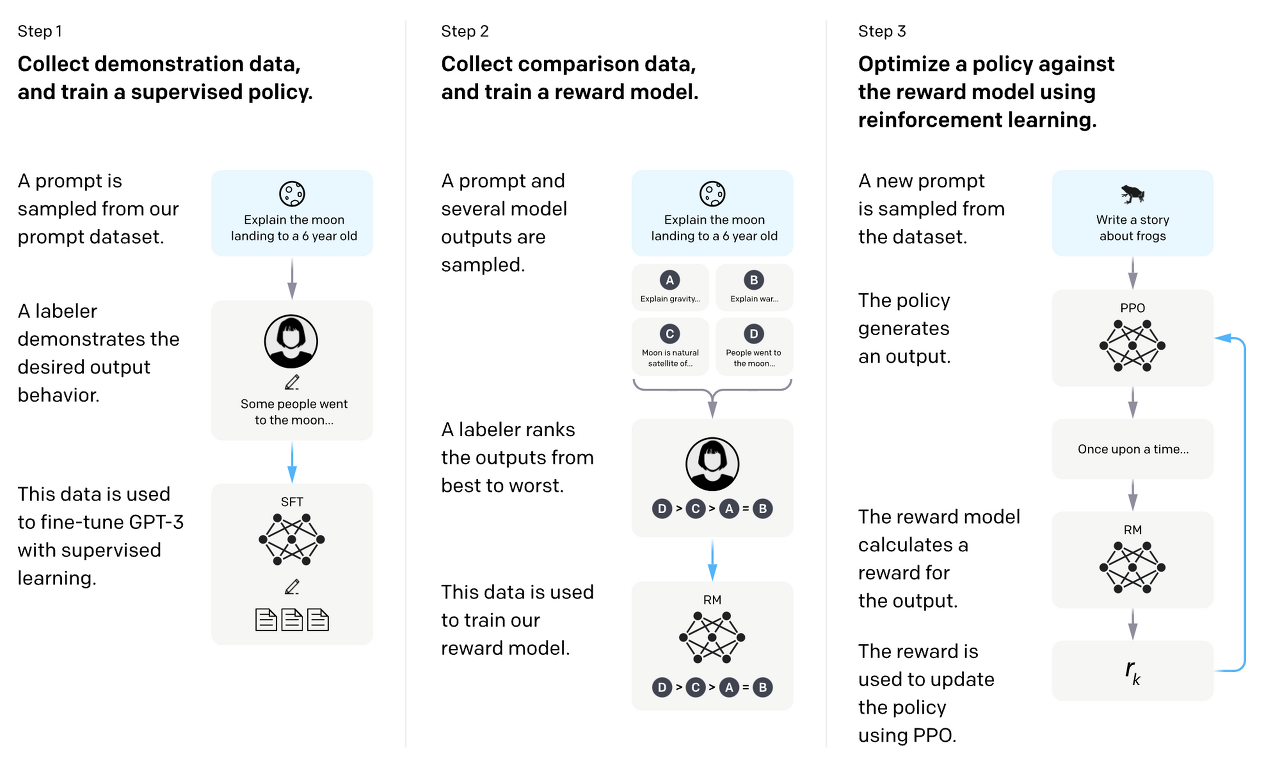
InstructGPT Overview 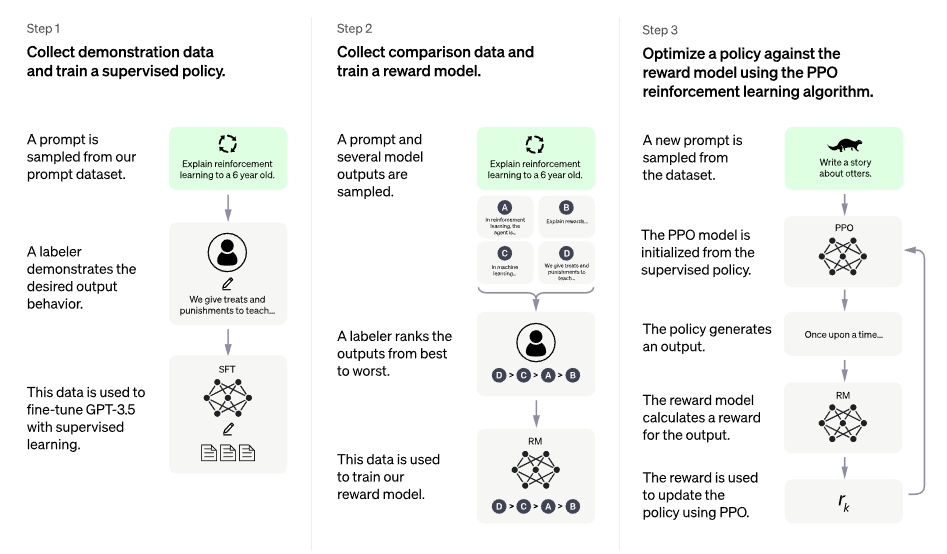
ChatGPT Overview - 3 Step으로 수행
Step 1. Supervised Learning
Step 2. Reward Model
- 학습된 모델이 생성한 여러 답변의 랭킹을 매기고 이를 기반으로 강화학습 모델(RM)을 학습

- 1. M을 이용하여 같은 query에 대해 k개의 output을 generation한 후, human이 k개에 대해 더 좋다고 판단되는 결과를 ranking하는 방식으로 human scoring을 진행
- ex) <query, output_a, output_b, output_c>와 같은 결과가 있을때, output의 퀄리티에 따라 output_b > output_a > output_c와 같이 랭킹을 하는 방식
- 2. human scoring된 데이터를 이용하여 reward model을 학습하게 됨
- 학습된 reward 모델을 이용하여 <query, generated_output>이 입력으로 주어졌을때, 모델이 생성한 generated_output에 대해 human scoring을 mimic할 수 있는 reward 결과를 부여할 수 있음
Step 3. Proximal Policy Optimization (PPO)

- 1) RLHF 학습을 위해 별도로 준비한 대화 문맥 c에 대해 SFT 모델이 답변 후보들 y1,…,yN을 생성
- 2) 리워드 모델이 생성한 답변들에 대해서 리워드 점수 r ϕ ( y 1 , c ) , … , r ϕ ( y N , c ) 를 계산
- 3) 이를 기반으로 다음 loss 함수와 같이 리워드 점수를 최대화 하는 방향으로 SFT 모델을 fine-tuning
- π_θ 와 π_ref 는 각각 Policy와 레퍼런스 모델이 주어진 문맥에 대해 문장의 확률을 계산하는 함수
- KL divergence term은 KL Penalty라고도 하는데, 원래의 레퍼런스 모델의 분포로부터 너무 크게 벗어나지 않도록 방지하는 regularization term


Direct Preference Optimization (DPO)
- RLHF의 과정 중 Reward model을 학습시키는 과정을 없애므로써, 기존의 RLHF 방법들의 복잡한 학습 파이프라인을, simple relative cross entropy training 으로 바꾼 접근법 제시

- 배경
- LM training 은 dataset maximum likelihood로 학습되므로, desired response, behavior를 잘 선택하여 모델에게 입력해주어야 똑똑한 LM이 학습될 수 있다
- 따라서 데이터셋 이상의 능력을 가진 LM을 학습시키려면 RL-based approach를 사용하는 것은 필수라고 볼 수 있다
- 따라서 데이터셋 이상의 능력을 가진 LM을 학습시키려면 RL-based approach를 사용하는 것은 필수라고 볼 수 있다
- LM training 은 dataset maximum likelihood로 학습되므로, desired response, behavior를 잘 선택하여 모델에게 입력해주어야 똑똑한 LM이 학습될 수 있다
- DPO는 여기서 Reward model 단계를 없애고 선호도 데이터셋만 있다면, relative log probability를 증가하는 objective로 LM을 tuning할 수 있다
- DPO는 reward model 학습이나, 학습동안 policy에서 샘플링하는 것 없이 simple binary cross entropy loss하나로 policy를 optimize할 수 있기 때문에, reward model을 고성능의 reward model을 사용할 수 없는 곳에서 RLHF를 하려면 DPO로 대체할 수 있을 것
- DPO는 reward model 학습이나, 학습동안 policy에서 샘플링하는 것 없이 simple binary cross entropy loss하나로 policy를 optimize할 수 있기 때문에, reward model을 고성능의 reward model을 사용할 수 없는 곳에서 RLHF를 하려면 DPO로 대체할 수 있을 것

import torch.nn.functional as F def dpo_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, beta): """ pi_logps: policy logprobs, shape (B,) ref_logps: reference model logprobs, shape (B,) yw_idxs: preferred completion indices in [0, B-1], shape (T,) yl_idxs: dispreferred completion indices in [0, B-1], shape (T,) beta: temperature controlling strength of KL penalty Each pair of (yw_idxs[i], yl_idxs[i]) represents the indices of a single preference pair. """ pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs] ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs] pi_logratios = pi_yw_logps - pi_yl_logps ref_logratios = ref_yw_logps - ref_yl_logps losses = -F.logsigmoid(beta * (pi_logratios - ref_logratios)) rewards = beta * (pi_logps - ref_logps).detach() return losses, rewardsKahneman-Tversky Optimization (KTO)
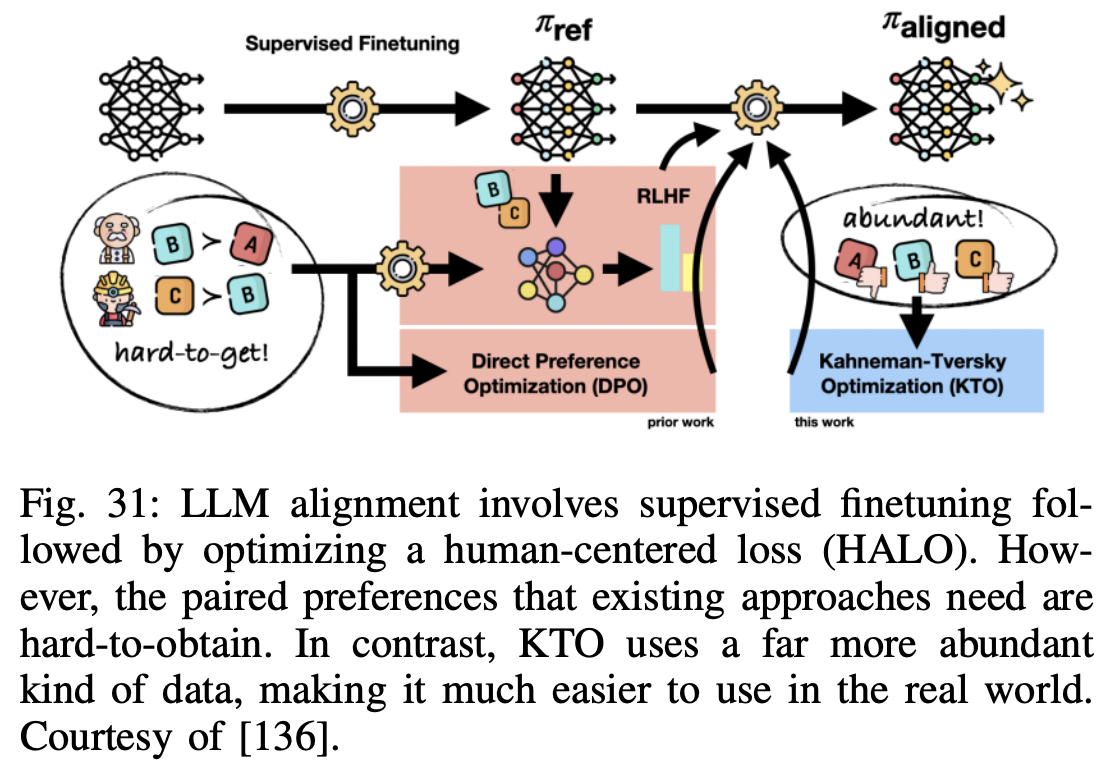
- 기존의 최신 접근 방식과 달리, KTO는 쌍으로 된 선호 데이터(x, yw, yl)를 요구하지 않으며, 오직 (x,y)와 y가 바람직한지 혹은 그렇지 않은지의 지식만 필요
- KTO로 정렬된 모델은 쌍으로 된 선호를 사용하지 않음에도 불구하고 1B부터 30B에 이르는 규모에서 DPO로 정렬된 모델보다 좋거나 더 나은 것으로 나타남
https://github.com/ContextualAI/HALOs
GitHub - ContextualAI/HALOs: A library with extensible implementations of DPO, KTO, PPO, and other human-aware loss functions (H
A library with extensible implementations of DPO, KTO, PPO, and other human-aware loss functions (HALOs). - ContextualAI/HALOs
github.com
+) 개인적으로 궁금했던 것
- 그럼 과연 몇 개의 쿼리 Pair가 있어야 의도한 대로 Alignment가 잘 될까?
- 관련 논문들을 보니 몇 천건에서 몇 만건 단위인가봄
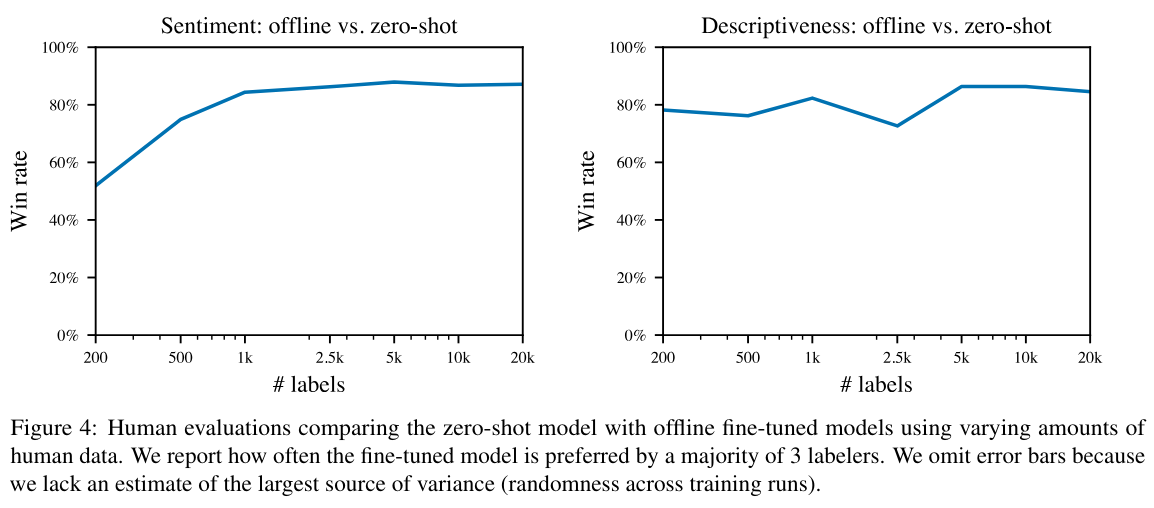
Fine-Tuning Language Models from Human Preferences (OpenAI에서 2020년에 낸 논문) https://arxiv.org/abs/1909.08593
Related Papers
https://arxiv.org/abs/2402.06196
Large Language Models: A Survey
Large Language Models (LLMs) have drawn a lot of attention due to their strong performance on a wide range of natural language tasks, since the release of ChatGPT in November 2022. LLMs' ability of general-purpose language understanding and generation is a
arxiv.org
https://arxiv.org/abs/2203.02155
Training language models to follow instructions with human feedback
Making language models bigger does not inherently make them better at following a user's intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user. In other words, these models are not ali
arxiv.org
https://arxiv.org/abs/2311.08401
Fine-tuning Language Models for Factuality
The fluency and creativity of large pre-trained language models (LLMs) have led to their widespread use, sometimes even as a replacement for traditional search engines. Yet language models are prone to making convincing but factually inaccurate claims, oft
arxiv.org
https://arxiv.org/abs/2305.18290
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining s
arxiv.org
https://arxiv.org/abs/2402.01306
KTO: Model Alignment as Prospect Theoretic Optimization
Kahneman & Tversky's $\textit{prospect theory}$ tells us that humans perceive random variables in a biased but well-defined manner; for example, humans are famously loss-averse. We show that objectives for aligning LLMs with human feedback implicitly incor
arxiv.org
Ref.
https://ebbnflow.tistory.com/382
[RLHF] Direct Preference Optimization, DPO
Direct Preference Optimization: Your Language Model is Secretly a Reward Model Link : https://arxiv.org/pdf/2305.18290.pdf Neurips 2023 논문이고, 이전 RLHF 방법론들에서 Reward model을 학습시키는 과정을 없애므로써, 기존의 RLHF
ebbnflow.tistory.com
https://velog.io/@nellcome/RLHF%EB%9E%80
RLHF란?
RLHF에 대해 알아보자
velog.io
https://grooms-academy.tistory.com/10
Behind ChatGPT: Reinforcement Learning from Human Feedback (RLHF)
본 포스트에서는 ChatGPT을 학습할때 1.3B만으로 175B만큼의 성능을 내는데 가장 중요한 역할을 했던 Reinforcement Learning from Human Feedback (RLHF)에 관해 설명한다. Detail은 InstructGPT 논문 리뷰에서 추가적
grooms-academy.tistory.com
https://tech.scatterlab.co.kr/luda-rlhf/
더 나은 생성모델을 위해 RLHF로 피드백 학습시키기
Human feedback을 학습할 수 있는 RLHF 방법론에 대해서 소개하고 루다에 적용한 사례한 경험을 공유합니다.
tech.scatterlab.co.kr
https://kyujinpy.tistory.com/79
[ChatGPT 리뷰] - GPT와 Reinforcement Learning Human Feedback
*ChatGPT에 대해서 설명하는 글입니다! 궁금하신 점은 댓글로 남겨주세요! InstructGPT: https://openai.com/research/instruction-following#guide Aligning language models to follow instructions We’ve trained language models that are mu
kyujinpy.tistory.com
https://github.com/ContextualAI/HALOs
GitHub - ContextualAI/HALOs: A library with extensible implementations of DPO, KTO, PPO, and other human-aware loss functions (H
A library with extensible implementations of DPO, KTO, PPO, and other human-aware loss functions (HALOs). - ContextualAI/HALOs
github.com
728x90'AI > NLP' 카테고리의 다른 글
- Alignment란 AI 시스템을 인간의 목표, 선호도 및 원칙에 맞추어 조정하는 과정