-
"[SK TECH SUMMIT 2023] RAG를 위한 Retriever 전략" 영상 리뷰AI/NLP 2024. 4. 22. 10:40728x90
"[SK TECH SUMMIT 2023] RAG를 위한 Retriever 전략" 영상 리뷰
- 목차
- Retrieval Augmented Generation
- RAG가 왜 어려운가?
- Document Parsing - Table
- Retriever 전략
Retrieval Augmented Generation

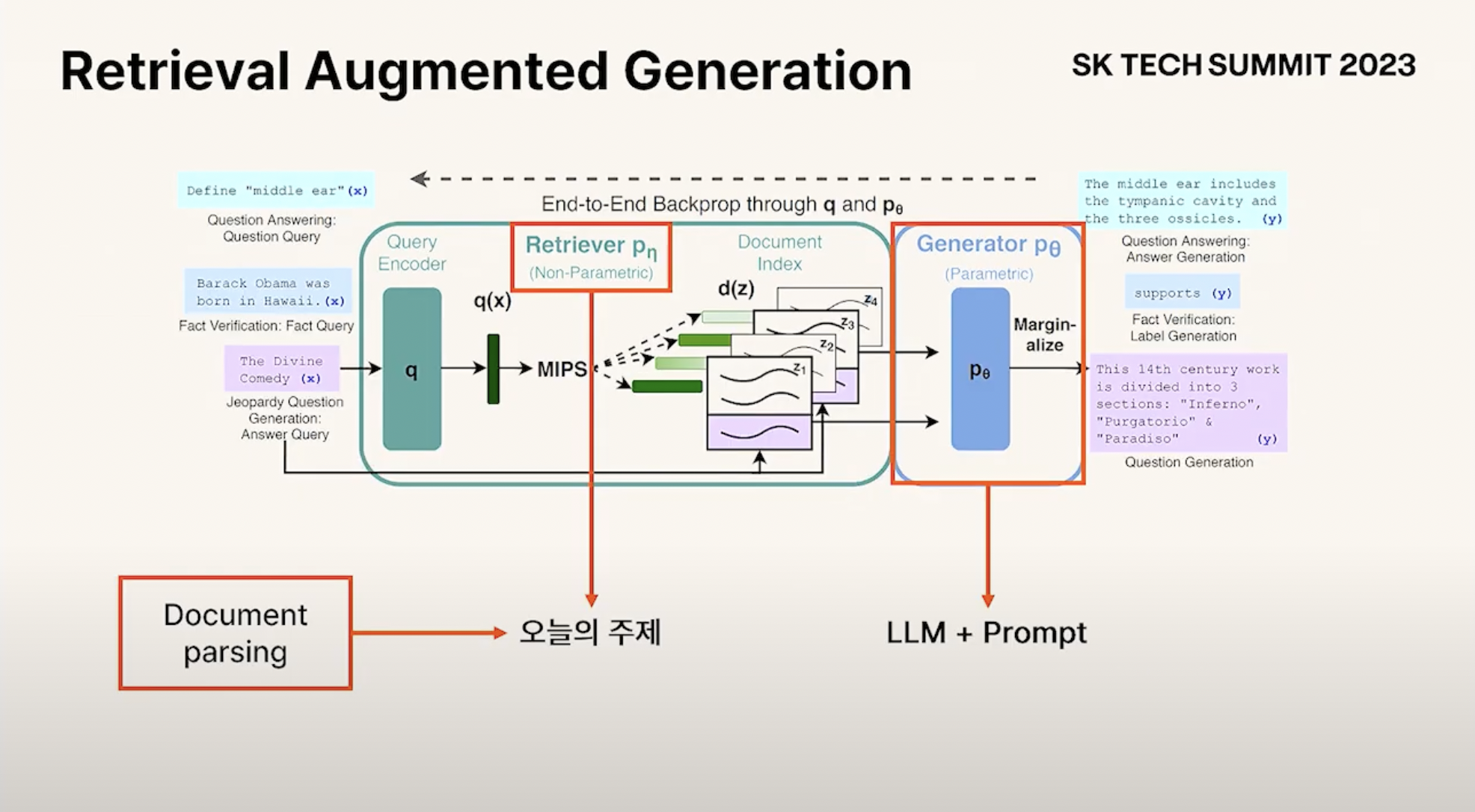
- RAG가 처음 등장한 건 GPT-3 등장 때쯤, 이때는 Generator의 성능 자체가 그다지 좋지 못하다 보니까 ...
- 요즘엔 LLM의 등장으로 Generator 성능 향상 -> Retriever & Document Parsing 부분의 중요성 !
- 아직도 기업 내부 문서를 가지고 RAG하기에는 Retriever & Document Parsing 이 부분에서 어려움이 있다 ....
RAG가 왜 어려운가?

- OpenAI API로 Retrieval 했을 때에도 숫자나 답변 내용이 맞지 않는 등 성능 그다지 좋지 못하다
- 왜 그럴까? -> 우리가 다루는 문서의 특징을 보자



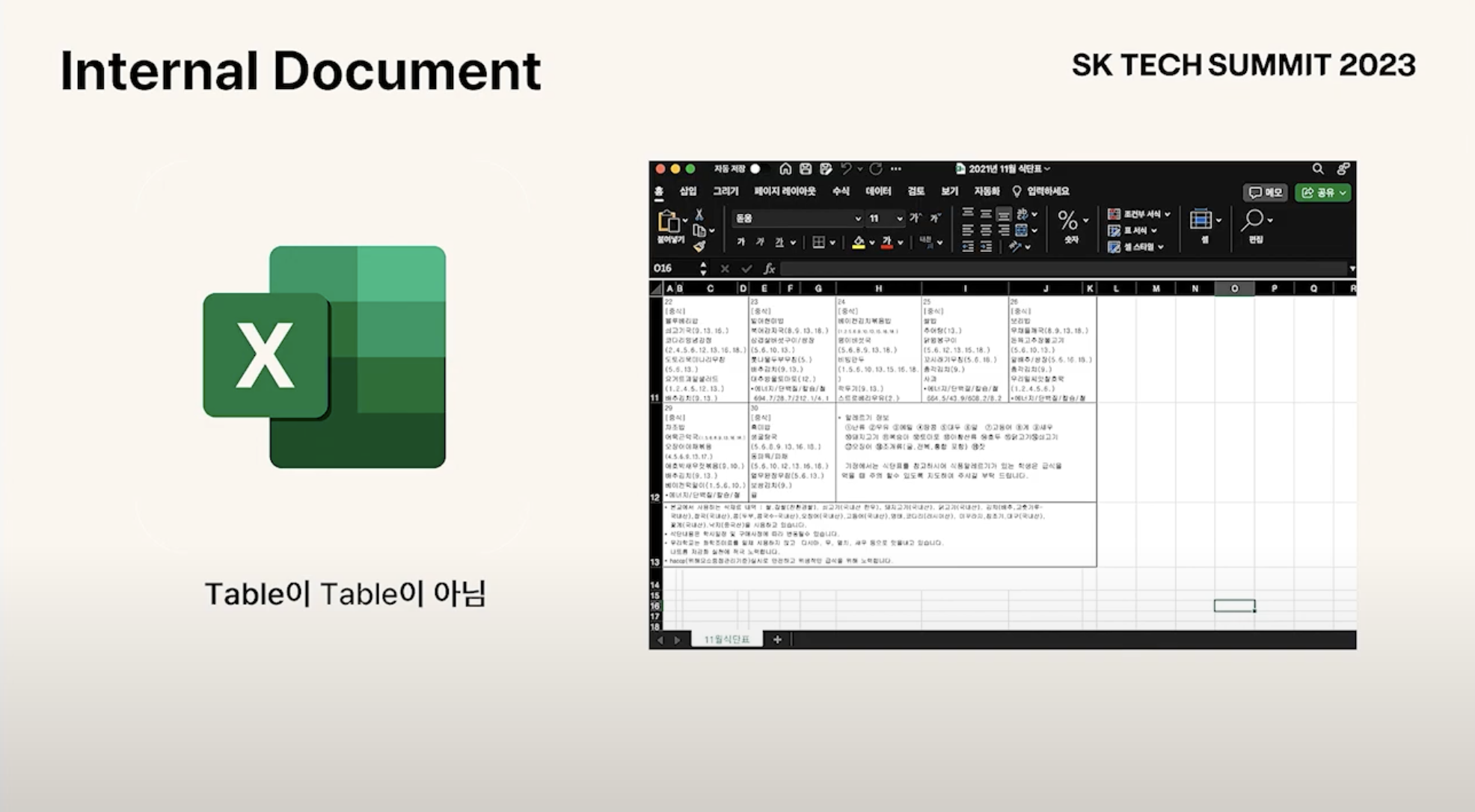
- 기업 내부에서 많이 쓰는 문서 형식을 보면 아래와 같은 특징과 어려움 있다
- PDF의 경우,
- 조판 시스템
- 다단과 같은 경우에 글의 순서 순차적으로 적혀있지 않는 등 ... Layout 알 수 없음
- Table을 잘 인식하지 못함
- Header와 Footer 모름
- Word
- 조판 시스템
- CSV
- Table이 Table이 아님
- PDF의 경우,


- OpenAI API와 Alli에서 생성한 답변 차이
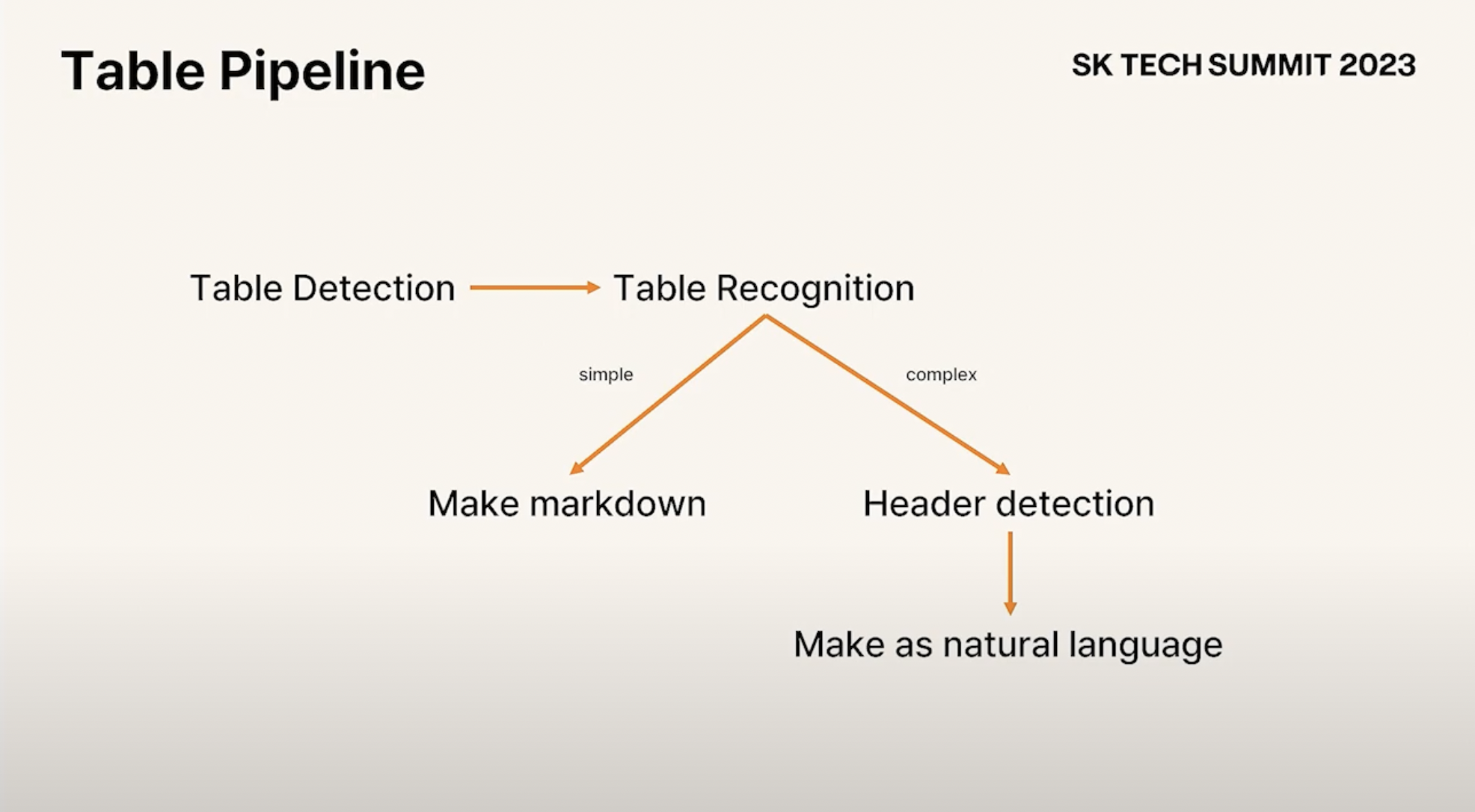
1. Document Parsing - Table
- 문서를 parsing할 때 가장 어려운 Table, 어떻게 다뤄야 할까?
- 1. Markdown
- 작은 Table 넣었을 땐 잘 되지만, 조금만 더 커지면 잘 되지 않는다
- MD의 형식이 깨지는 경우: |나 엔터와 같은 특수문자 들어가면 ...
- 2. Natural Language
- Table의 Header등을 참고해서 자연어로 바꿔준다 ㅇㅇ
- Merged cell 등 어려운 형식의 Table이더라도 Header만 잘 잡을 수 있으면 잘 변환하더라
- Retriever에서도 잘 추출해내더라
- 1. Markdown


- 요약하자면 ...
2. Retriever 전략
- 1. Sparse Retriever
- Keyword 기반의 Search
- 문제 :
- 꼭 답변이 Keyword가 언급된 곳에서 찾을 수 있는 것인가? 그렇지 않은 경우도 있잖아 -> 한계

- 2. Ensemble Retriever
- 아래 그림은 실제 고객 문서들로 Retrieve했을 때의 성능
- 하지만 성능이 천차만별이다 .... !
- 따라서, 고객 문서와 질문에 따라서 Weight를 자동으로 조절할 필요가 있다

- 3. Dense Retriever
- 그럼 DPR (Dense Passage Retreival)을 학습을 하면 다 성능이 좋나? -> 실세계에 적용했을 때 문제가 발생
- 우선 Dense Retriever 학습 방법
- 1) Cross Encoder
- 얘는 성능은 좋으나, 사실상 쓸 수 없는 애
- Context가 수십 만개인데, 실시간으로 질문 하나 들어올 때마다 하나씩 다 모델에 태우는 게 불가능하잖아
- 2) Bi Encoder
- 위와 비슷한 문제 발생 ...
- Data가 쌓일 때마다 또 학습하고 또 학습하고 ... 몇십만개의 Vector 학습 모두 하는 거 불가능
- 1) Cross Encoder


- 결국 아래와 같은 모습으로 Retriever 구성될 수밖에 없다 - input question만 학습하는 것!
- 그럼 저 Model을 학습할 데이터셋은 어떻게 구하나?
- Positive sample에 대해선 GPT등으로 생성할 수 있음 ㅇㅇ
- 하지만 현재까지는 Negative sample에 대해선 GPT 등의 모델로는 생성하기 어렵다 ...
- 그럼 뭐 1번 페이지의 Positive Sample을 2번 페이지의 Negative Sample로 사용할 수 있지 않을까? -> 그것도 불가능한 경우 많음
- 그럼 저 Model을 학습할 데이터셋은 어떻게 구하나?
=> 결국엔, Positive Sample만 구할 수 있으므로, Binary Cross Entropy같은 loss function을 사용할 수 없게 되고 Cosine Embedding Loss나 벡터끼리 비교하는 MSE만 가능하게 된다 ...


- OpenAI Embedding을 Baseline으로 위 방식 (MSE, Cosine) 실험해보았다 (이유: Context Window 제일 길어서 )
- 왼쪽 그림을 봤을 때, 2D로 PCA 했을 때 질문 벡터(빨간색)와 문서 벡터(파란색) 분리되어 있음 ㅇㅇㅇ
- 오른쪽의 모델 통과한 그림을 보면, 학습 후 질문 벡터(초록색)이 문서 벡터와 거의 맵핑됨 ㅇㅇㅇ 잘된다 !

- 하지만 발표자 분의 말로는, 이게 왜 잘 되는지 의구심이 든다며 ... 호호
- 아래와 같이 잘 되지만, 또 데이터셋에 따라 성능이 달라지는 경향을 보인다

정리

- 감상
- 양질의 영상, 재밌다 ... 이번 Tech Summit은 수료식 참가하느라 다른 강연들 못 들었는데 올해 열리면 꼭 참석해봐야겠다
- Retriever 관련 논문들 좀 더 읽어보고 싶다는 생각
- Document Parsing할 때 OCR 중요하겠다, 좀 더 찾아보니 Huggingface 페이지에서 관련 아티클 볼 수 있었음
Ref.
https://www.youtube.com/watch?v=sy2asT2c8FM&t=651s
728x90'AI > NLP' 카테고리의 다른 글
- 목차