-
LangChain RAG 구현 모듈 정리 (Document Loaders, Text Splitters, Text Embeddings & VectorStores , Retrievers, ... )AI/NLP 2024. 5. 14. 22:14728x90
LangChain RAG 구현 모듈 정리
(Document Loaders, Text Splitters, Text Embeddings & VectorStores , Retrievers, ... )

- 과정
- Document Loaders
- Text Spiltters
- Text Embeddings & VectorStores
- Retrievers
!pip install langchain pypdf unstructured pdf2image docx2txt pdfminer sentence-transformers chromadb# a class to create a question answering system based on information retrieval from langchain.chains import RetrievalQA # a class to create text embeddings using HuggingFace templates from langchain.embeddings import HuggingFaceEmbeddings # a class to create a neural language model using LlamaCpp, a C++ implementation of GPT-3 from langchain.llms import LlamaCpp # a class for splitting text into fixed-sized chunks with an optional overlay from langchain.text_splitter import RecursiveCharacterTextSplitter # a class to create a vector index using FAISS, a library for approximate nearest neighbor search from langchain.vectorstores import FAISS # a class for loading PDF documents from a directory from langchain.document_loaders import PyPDFDirectoryLoader1. Document Loaders

- 1) URL Document Loaders
- 대표적인 URL Loader는 WebBaseLoader와 UnstructuredURLLoader가 있다
- 다만 원치 않는 정보들까지 포함되어서 나오는 경우 있음
- 대표적인 URL Loader는 WebBaseLoader와 UnstructuredURLLoader가 있다
- 2) PDF Document Loaders
- PyPDFLoader : PDF 문서 페이지별로 로드
- UnstructuredPDFLoader : 형식이 없는 PDF 문서 로드
- PyMuPDFLoader : PDF 문서의 메타 데이터를 상세하게 추출
- OnlinePDFLoader : 온라인(on-line) PDF 문서 로드
- PyPDFDirectoryLoader : 특정 폴더의 모든 PDF 문서 로드
- 3) Word Document Loaders
- Docx2txtLoader : doc 형식
- TextLoader : txt 형식
- 4) CSV Document Loader
- CSVLoader 클래스를 사용하여 CSV 파일에서 데이터를 로드
- CSV 파일의 각 행을 추출하여 서로 다른 Document 객체로 변환합
- CSVLoader 클래스를 사용하여 CSV 파일에서 데이터를 로드
- 5) Directory Loader
- DirectoryLoader를 사용하여 디렉토리 내의 모든 문서를 로드할 수 있다.
- 코드 ( PyPDFDirectoryLoader )
# load PDF files from a directory loader = PyPDFDirectoryLoader("/PDF_Documents/") data = loader.load() # print the loaded data, which is a list of tuples (file name, text extracted from the PDF) print(data)2. Text Spiltters


- 1) CharacterTextSplitter
- 2) RecursiveCharacterTextSplitter
- 3) 토큰 수를 기준으로 텍스트 분할 (Tokenizer 활용)
- LLM 모델에 적용되는 토크나이저를 기준으로 텍스트를 토큰으로 분할하고, 이 토큰들의 수를 기준으로 텍스트를 청크로 나누면 모델 입력 토큰 수를 조절할 수 있음
- LLM 앱을 개발하고자 한다면 앱에 얹힐 LLM의 토큰 제한을 파악하고, 해당 LLM이 사용하는 Embedder를 기반으로 토큰 수를 계산해야 합니다.
- 예를 들어, OpenAI의 GPT 모델은 tiktoken이라는 토크나이저를 기반으로 텍스트를 토큰화합니다. 따라서 tiktoken encoder를 기반으로 텍스트를 토큰화하고, 토큰 수를 기준으로 텍스트를 분할하는 것이 프로덕트 개발의 필수 요소라고 할 수 있습니다.
- OpenAI API의 경우 tiktoken 라이브러리를 통해 해당 모델에서 사용하는 토크나이저를 기준으로 분할할 수 있다
- LLM 모델에 적용되는 토크나이저를 기준으로 텍스트를 토큰으로 분할하고, 이 토큰들의 수를 기준으로 텍스트를 청크로 나누면 모델 입력 토큰 수를 조절할 수 있음
- 4) 그 외 특수한 상황
- 일반적인 글로 된 문서는 모두 `textsplitter로` 분할할 수 있으며, 대부분의 경우가 커버됩니다.
- 그러나 코드, latex 등과 같이 컴퓨터 언어로 작성되는 문서의 경우 `textsplitter로` 처리할 수 없으며 해당 언어를 위해 특별하게 구분하는 splitter가 필요합니다.
- 예를 들어 Python 문서를 split하기 위해서는 `def`, `class와` 같이 하나의 단위로 묶이는 것을 기준으로 문서를 분할할 필요가 있습니다. 이러한 원리로 Latex, HTML, Code 등 다양한 문서도 분할할 수 있습니다.
- 일반적인 글로 된 문서는 모두 `textsplitter로` 분할할 수 있으며, 대부분의 경우가 커버됩니다.

- 코드 (RecursiveCharacterTextSplitter)
# split the extracted data into text chunks using the text_splitter, which splits the text based on the specified number of characters and overlap text_splitter = RecursiveCharacterTextSplitter(chunk_size=10000, chunk_overlap=20) text_chunks = text_splitter.split_documents(data) # print the number of chunks obtained len(text_chunks)Text Splitter 사용시 메소드 create_documents VS split_documents VS split_text
- create_documents : 문자열 배열을 가져와서 분할하고 이에 대한 문서를 반환
- split_documents : 문서 배열을 가져와 문자열 배열로 변환한 후 create_documents에 전달
- split_text : 문자열을 가져와서 분할된 청크의 리스트를 반환3. Text Embeddings & VectorStores

- Vector library들은 Pure vector database들에 비해 기능이 빈약한 면이 있고, 아무래도 유지보수를 계속하기엔 적절하지 않다
- 무료로 사용하기에는 Chroma, 유료로 더 많은 기능 사용하기 위해서는 PineCone, Weaviate 사용한다고 함

- 1) Chroma
- 특징
- 임베딩 벡터를 저장하기 위한 오픈소스 소프트웨어
- 작동
- 텍스트와 임베딩 함수를 지정하여 from_documents() 함수에 보내면, 지정된 임베딩 함수를 통해 텍스트를 벡터로 변환하고, 이를 임시 db로 생성합니다.
- 저장소는 collection_name으로 구분되며, 여기서는 'history'라는 이름을 사용합니다.
- 저장된 데이터는 ./db/chromadb 디렉토리에 저장됩니다.
- 그리고 similarity_search() 함수에 쿼리를 지정해주면 이를 바탕으로 가장 벡터 유사도가 높은 벡터를 찾고 이를 자연어 형태로 출력합니다.
- 그런데, 대부분의 경우에서는 내가 활용하고자 하는 문서를 나만의 디스크에 저장하고 필요할 때마다 호출해야 합니다. persist() 함수를 통해 벡터저장소를 로컬 저장하고, Chroma 객체를 선언할 때 로컬 저장소 경로를 지정하여 필요할 때 다시 불러올 수 있습니다.
- 쿼리와 유사한 문서(청크)를 불러올 때, 유사도를 함께 제공하는 함수 similarity_search_with_score()를 제공합니다. 이를 통해서 내가 얻은 유사한 문장들의 유사도를 비교할 수 있으며, 특정 유사도 이상의 문서만 출력하도록 하는 등 다양한 활용이 가능합니다.
- 텍스트와 임베딩 함수를 지정하여 from_documents() 함수에 보내면, 지정된 임베딩 함수를 통해 텍스트를 벡터로 변환하고, 이를 임시 db로 생성합니다.
- 검색 방법
- 1) 유사도 기반
- Cosine 유사도 등 metadata에서 원하는 거 쓸 수 있음
- 2) MMR (Maximum Marginal Relevance, 최대 한계 관련성)
- 유사성과 다양성의 균형을 맞추어 검색 결과의 품질을 향상시키는 알고리즘
- 이 방식은 검색 쿼리에 대한 문서들의 관련성을 최대화하는 동시에, 검색된 문서들 사이의 중복성을 최소화하여, 사용자에게 다양하고 풍부한 정보를 제공하는 것을 목표
- 원리
- 쿼리에 대한 각 문서의 유사성 점수와 이미 선택된 문서들과의 다양성(또는 차별성) 점수를 조합하여, 각 문서의 최종 점수를 계산
- 1) 유사도 기반
- 특징

embeddings_model = OpenAIEmbeddings() db = Chroma.from_texts( texts, embeddings_model, collection_name = 'history', persist_directory = './db/chromadb', collection_metadata = {'hnsw:space': 'cosine'}, # l2 is the default ) query = '누가 한글을 창제했나요?' docs = db.similarity_search(query) print(docs[0].page_content)- 2) FAISS
- 특징
- FAISS(Facebook AI Similarity Search)는 Facebook AI Research에 의해 개발된 라이브러리로, 대규모 벡터 데이터셋에서 유사도 검색을 빠르고 효율적으로 수행할 수 있게 해줌
- 특히 벡터의 압축된 표현을 사용하여 메모리 사용량을 최소화하면서도 검색 속도를 극대화하는 특징
- 검색 방법
- Chroma와 같음
- 특징
- 코드 (HuggingFaceEmbeddings & Chroma)
from langchain.embeddings import HuggingFaceEmbeddings from langchain_community.vectorstores import Chroma # VectorDB model_name = "jhgan/ko-sbert-nli" encode_kwargs = {'normalize_embeddings': True} ko_embedding = HuggingFaceEmbeddings( model_name=model_name, encode_kwargs=encode_kwargs ) vectordb = Chroma.from_documents(documents=text_chunks, embedding=ko_embedding) # load it into Chroma db = Chroma.from_documents(text_chunks, ko_embedding) # query it query = "TCP UDP란 뭐야?" docs = db.similarity_search(query)4. Retrievers
- LLM에게 찾은 문서들에 대해 어떻게 전달하느냐에 따라 방법이 4가지가 있다
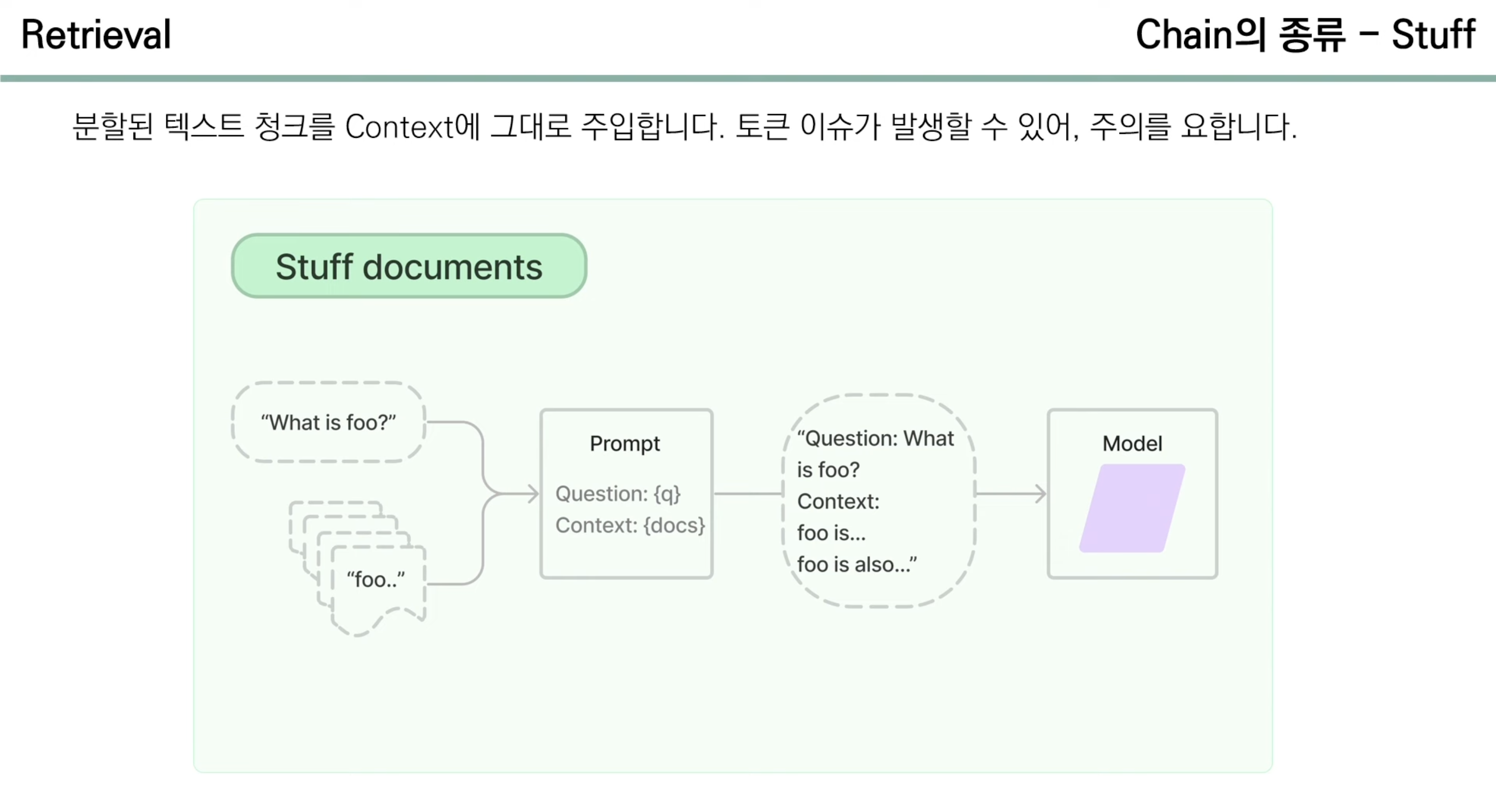
- 1) Stuff
- 분할된 텍스트 청크를 Context에 그대로 주입
- Text Chunk를 길게 했을 경우에 Token 이슈가 발생할 수 있어서 주의해야 함
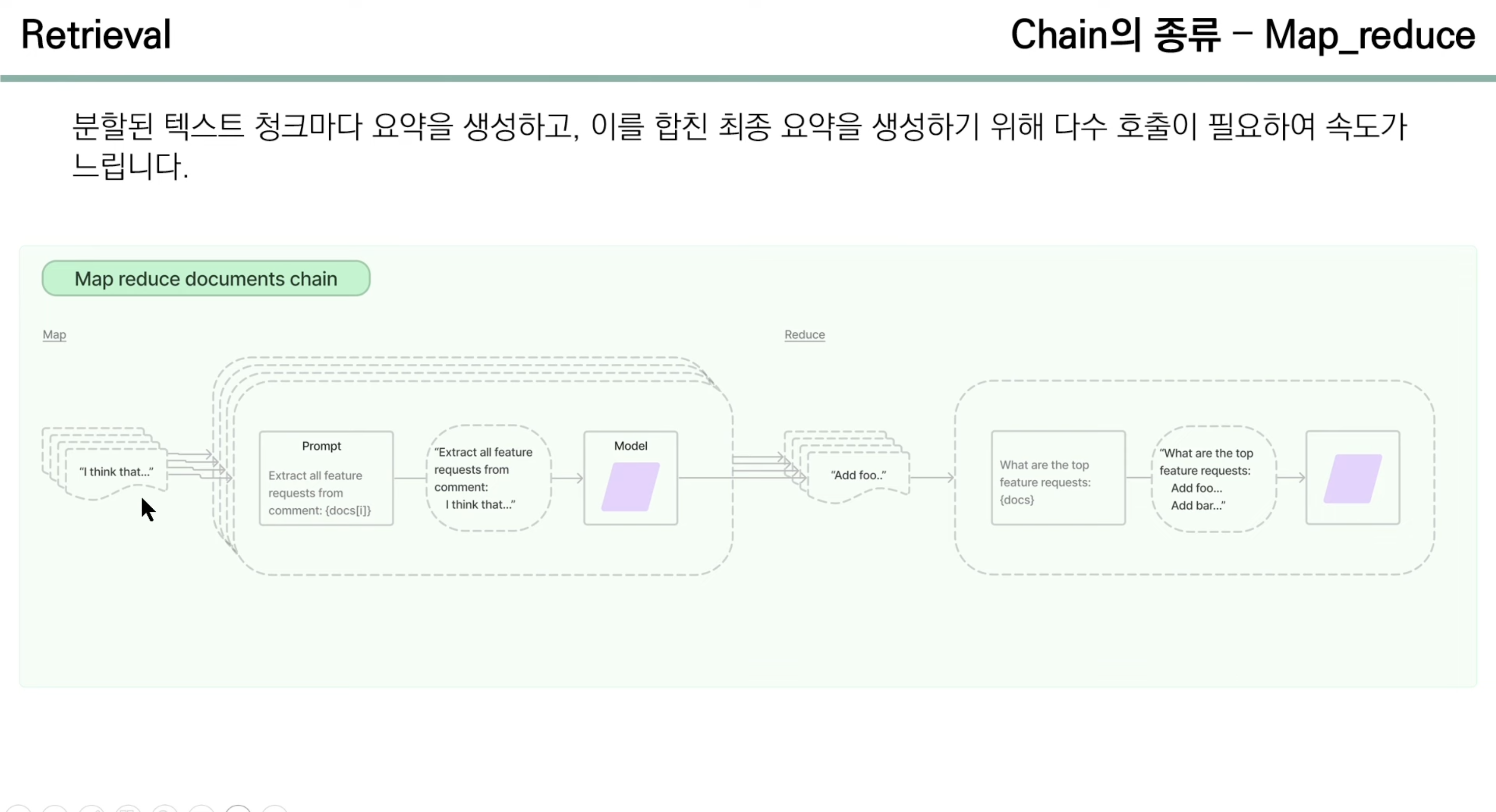
- 2) Map Reduce
- 분할된 텍스트 청크마다 요약을 생성하고, 이를 합친 최종 요약을 생성하기 위해 llm이 각 텍스트를 요약하고 합치는 과정에서 다수 호출이 필요하여 속도가 느림
- 3) Refine
- 분할된 텍스트 청크를 순회하면서 누적 답변을 생성함
- 품질이 뛰어나지만 시간이 오래 걸림 (병렬로 수행 불가)
- 4) Map re-rank
- 분할된 텍스트 청크를 순회하면서 누적 답변 생성
- 들어온 Context와 사용자의 질문 간의 유사도를 score로 매겨 반환해줌
- 품질이 뛰어나지만 시간이 오래 걸림
- 1) Stuff


- Retriever의 종류
- 1) 벡터스토어 검색도구(Vector Store Retriever)를 사용하면 대량의 텍스트 데이터에서 관련 정보를 효율적으로 검색
- LangChain의 벡터스토어와 임베딩 모델을 사용하여 문서들의 임베딩을 생성하고, 그 후 저장된 임베딩들을 기반으로 검색 쿼리에 가장 관련 있는 문서들을 검색
- 2) 멀티 쿼리 검색도구(MultiQueryRetriever)는 벡터스토어 검색도구(Vector Store Retriever)의 한계를 극복하기 위해 고안된 방법
- 사용자가 입력한 쿼리의 의미를 다각도로 포착하여 검색 효율성을 높이고, LLM을 활용하여 사용자에게 보다 관련성 높고 정확한 정보를 제공하는 것을 목표
- 이외의 Retriever들은 다음 포스트에서 살펴보도록 하겠다
- 1) 벡터스토어 검색도구(Vector Store Retriever)를 사용하면 대량의 텍스트 데이터에서 관련 정보를 효율적으로 검색
https://asidefine.tistory.com/298
LangChain RAG Retriever 방법 정리 (Multi-Query, Parent Document, Ensemble Retriever, ... )
LangChain RAG Retriever 방법 정리 (Multi-Query, Parent Document, Ensemble Retriever, ... ) 지난 포스트 마지막에서 언급했던 Retriever를 좀 더 심화해서 볼 것이다. Retriever 기법 1. Multi-Query : 대충
asidefine.tistory.com
Reference.
https://www.youtube.com/watch?v=tIU2tw3PMUE&t=564s
2-2. RAG - Document Loader
LangChain에서 Document Loader는 다양한 소스에서 문서를 불러오고 처리하는 과정을 담당합니다. 특히 사전지식이 필요한 지식 기반의 태스크, 정보 검색, 데이터…
wikidocs.net
https://medium.com/aimonks/multiple-pdf-chatbot-using-langchain-b3ee2296b1a7
Multiple-PDF Chatbot using Langchain
The goal of the project is to create a question answering system based on information retrieval, which is able to answer questions posed by…
medium.com
728x90'AI > NLP' 카테고리의 다른 글
- 과정