-
Query Expansion by Prompting Large Language Models (Google, 2023) 논문 리뷰AI/NLP 2024. 5. 24. 17:43728x90
Query Expansion by Prompting Large Language Models (Google, 2023) 논문 리뷰
Abstract + Introduction
- Query Expansion
- 정의 : 원문 Query에 몇가지 용어를 추가해서 검색 시스템의 성능을 향상시키는 방법
- 원문 Query랑 단어가 겹치지 않는 관련 document들을 뽑아내는 데 유용하다
- 기존의 방식
- Pseudo-Revevance Feedback (PRF): 원문 Query를 입력했을 때 나오는 Document에서 키워드를 추출해서, 그 키워드를 포함한 다른 Document 반환하는 방식
- 한계 : 가장 위에 retrieve되는 document가 query와 관련있다고 생각하는데, 실제로 특히 query가 짧은 경우엔 완벽하게 align되진 않음
- Lexical knowledge bases
- 이 논문과 비슷한 시도로는 Microsoft Research의 Query2Doc 논문이 있다 (https://arxiv.org/abs/2303.07678) - 읽어보자
- Pseudo-Revevance Feedback (PRF): 원문 Query를 입력했을 때 나오는 Document에서 키워드를 추출해서, 그 키워드를 포함한 다른 Document 반환하는 방식
- 정의 : 원문 Query에 몇가지 용어를 추가해서 검색 시스템의 성능을 향상시키는 방법
- Contribution
- 기존의 PRF이나 어휘 기반의 방식에서 벗어나서, LLM를 활용한 Query Expansion를 탐구하고자 함
- zero-shot, few shot, CoT 방식 등 여러 Prompt들로 실험해서 성능 비교해보겠다
- CoT가 그 중 성능 가장 좋았는데, Step-by-Step 방식이 실질적으로 도움이 되는 keyword를 많이 만들어냈다
- LLM을 활용한 Query Expansion 방식의 이점과 한계점을 살펴본다
Methodology
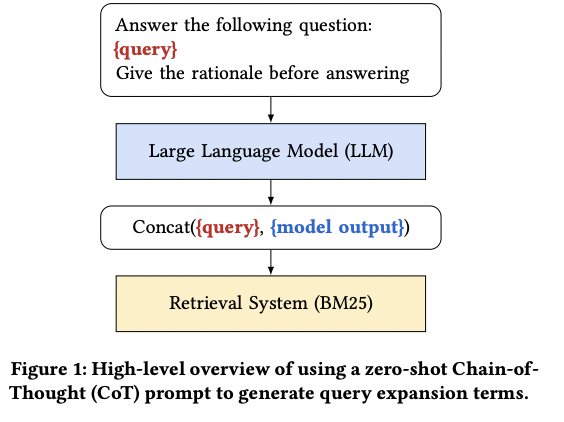
- 본 논문에서는 8가지 종류의 Prompt 사용
- Q2D
- The Query2Doc few-shot prompt, asking the model to write a passage that answers the query
- Q2D/ZS
- Q2D/PRF
- PRF 애들은 Top 3 Document들을 사용했다고 함
- Q2E
- Similar to the Query2Doc few-shot prompt but with examples of query expansion terms instead of documents
- Q2E/ZS
- Q2E/PRF
- CoT
- CoT/PRF
- Q2D

Experiments
- Retriever로는 BM25 모델 사용
- Baseline으로는 PRF 기반 방식의 3가지 방식과 Query2Doc 사용
- Bo1: Bose-Einstein 1 weighting
- Bo2: Bose-Einstein 2 weighting
- KL: Kullback-Leibler weighting
- 모델로는 Flan-T5랑 Flan-UL2 사용 (모델 사이즈는 여러 개 실험 다 해봄)
- Flan-T5-Small (60M parameters)
- Flan-T5-Base (220M parameters)
- Flan-T5-Large (770M parameters)
- Flan-T5-XL (3B parameters)
- Flan-T5-XXL (11B parameters)
- Flan-UL2 (20B parameters)
- Metrics
- Recall@1k
- 검색 결과로 가져온 k개의 문서들 중에서 얼마나 많은 (적합한) 관련 문서가 있는 가
- MRR@10 (Mean reciprocal rank): 질의(Q)에 대해 가장 적절한 아이템의 역순위 평균
- NDCG@10 (Normalized Discounted Cumulative Gain) : 모델이 예측한 순위를 반영한 측정 지표
- 기존 정보검색에서 많이 쓰였으며 , 특히 상위의 랭킹 리스트가 하위 랭킹 리스트 보다 확연하게 중요한 도메인에서는 유용한 평가 기준
- Recall@1k
Results
1. MS-MARCO Passage Ranking
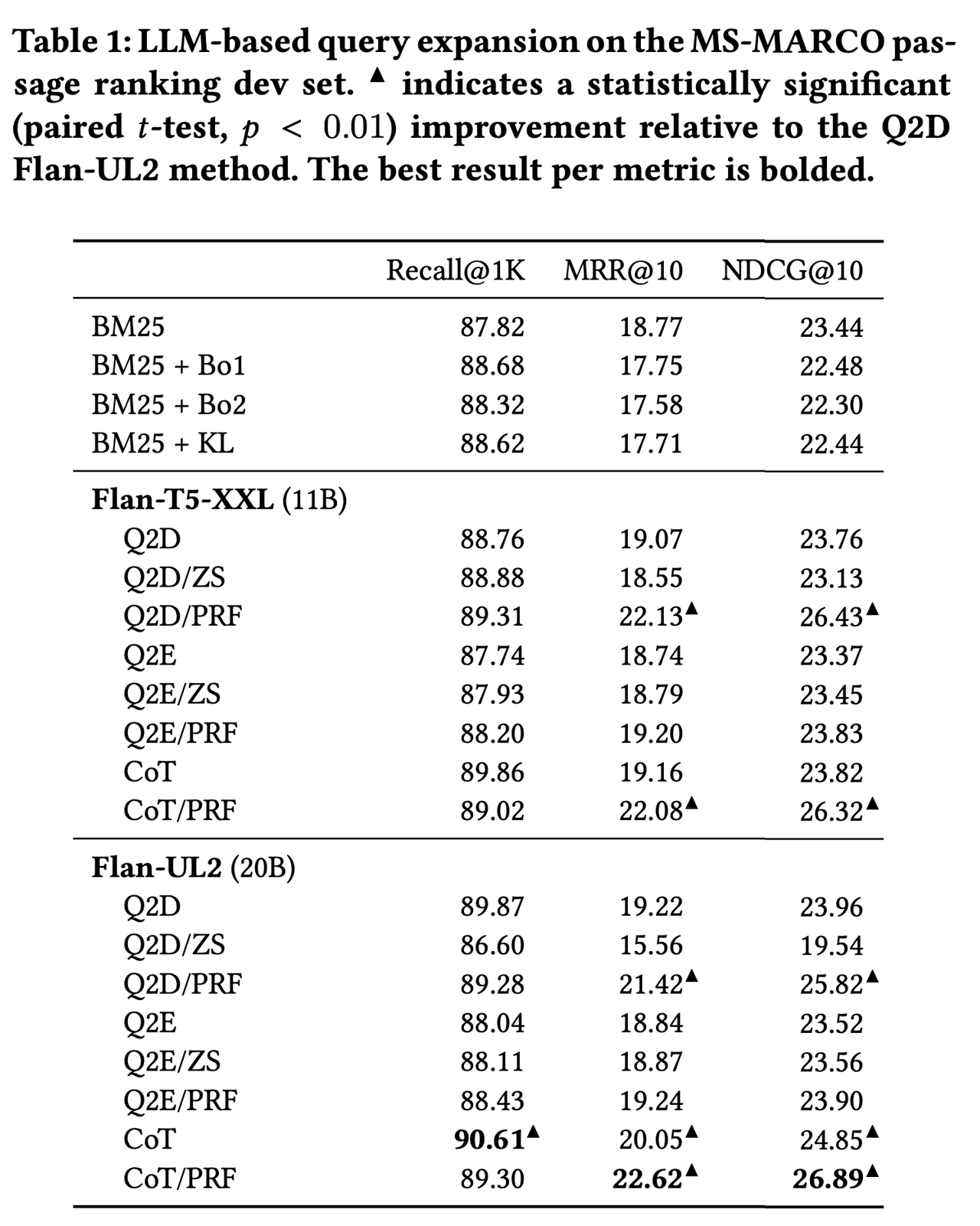
- CoT Prompt 방식이 가장 성능 좋음
- CoT 방식을 사용하면 말이 엄청 길어지고, 장황해지다보니 여러 잠재적인 단어들을 포함하게 되어서 인 것 같다고 추측
- PRF 방식에 Query 추가해주는 것 성능 향상 있음
- LM이 이미 relelvant passage들을 포함하고 있을 수 있는 PRF document들에 대해 효과적으로 distilling하고, 그 결과로 promising한 keyword들을 출력하기에
2. BEIR
- 여러 분야에서의 Retrieval Task에 효과적인지를 확인하기 위해 BEIR Dataset으로도 실험

- PRF-based query expansion에서 성능 좋음
- academic and scientific한 domain의 dataset에서 잘 작동하는 것을 확인
- general-purpose LLM에서는 반대로 이런 도메인에서 잘 못 한다
- question-answering 형식의 dataset에서는 LLM 방식이 좋더라
- LM이 query에 대해 relevant한 answer를 생성하고, 이러한 generated relevant answer가 효과적으로 relevant passage를 retrieve하기에
3. The Impact of Model Size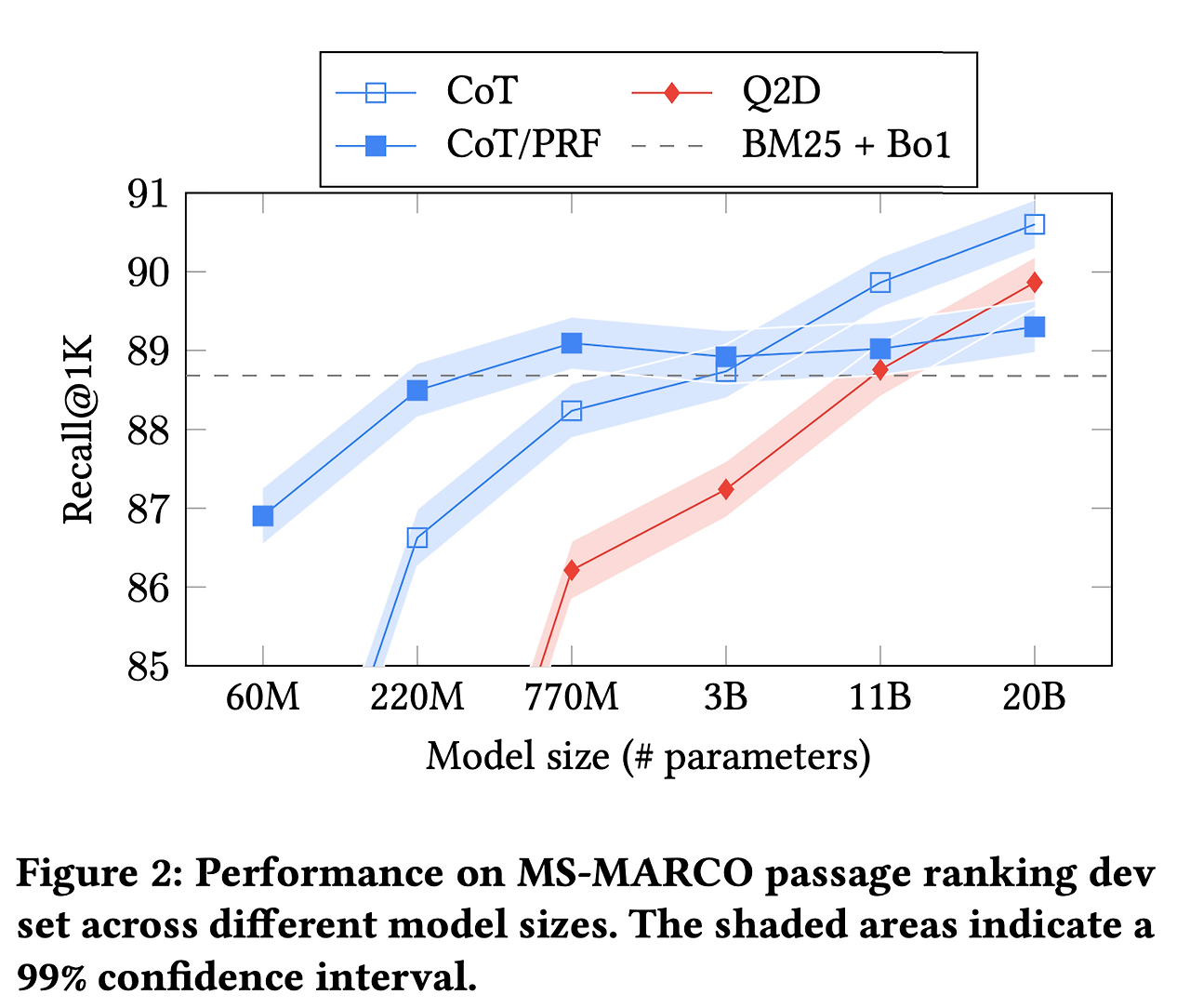
- 전반적으로 LLM 크기가 커질수록 더 좋은 성능을 냄
- CoT+PRF의 성능 변화의 경우엔
- PRF document가 주어지면, model이 제공된 document에만 집중하여 model의 창의성을 제한하기 때문
- 하지만 모델 사이즈가 작은 경우엔 가장 좋은 성능을 보이더라
소감
- Query Expansion 시에 LLM 사용하게 된다면 RAG 시스템에 적용할 때 너무 많은 단계를 거쳐야 하는 게 아닌가?
- query 받고 llm으로 CoT하고 keyword 뽑아서 retrieve하고 또 llm에 넣고 ...
- Query2Doc 논문처럼, Retriever로 Sparse 모델 말고도 Dense 모델도 넣어서 비교해봤으면 좋았을 듯
-> 적어놓고 보니 Limitations에 같은 내용 적혀있네 ...
https://arxiv.org/abs/2305.03653
Query Expansion by Prompting Large Language Models
Query expansion is a widely used technique to improve the recall of search systems. In this paper, we propose an approach to query expansion that leverages the generative abilities of Large Language Models (LLMs). Unlike traditional query expansion approac
arxiv.org
https://arxiv.org/abs/2303.07678
Query2doc: Query Expansion with Large Language Models
This paper introduces a simple yet effective query expansion approach, denoted as query2doc, to improve both sparse and dense retrieval systems. The proposed method first generates pseudo-documents by few-shot prompting large language models (LLMs), and th
arxiv.org
728x90'AI > NLP' 카테고리의 다른 글
- Query Expansion