-
Understanding Reasoning LLMs 번역AI/NLP 2025. 8. 10. 10:47728x90
추론 LLM 이해하기
이 아티클은 추론 모델을 구축하는 네 가지 주요 접근법, 즉 LLM에 추론 능력을 향상시키는 방법에 대해 설명함. 이 글이 가치 있는 통찰을 제공하고 이 주제를 둘러싼 빠르게 발전하는 문헌과 과대광고를 탐색하는 데 도움이 되길 바람.
2024년에 LLM 분야는 점점 더 전문화되는 모습을 보임. 사전 훈련과 파인튜닝을 넘어서, RAG부터 코드 어시스턴트까지 전문화된 애플리케이션의 부상을 목격함. 이 트렌드가 2025년에도 가속화될 것으로 예상되며, 도메인과 애플리케이션 특화 최적화(즉, "전문화")에 더욱 중점을 둘 것임.

1-3단계가 LLM 개발의 일반적인 단계들임. 4단계는 특정 사용 사례를 위해 LLM을 전문화함.추론 모델의 개발은 이러한 전문화 중 하나임. 이는 퍼즐, 고급 수학, 코딩 챌린지와 같이 중간 단계가 있어야 가장 잘 해결되는 복잡한 작업에서 뛰어난 성과를 내도록 LLM을 개선한다는 의미임. 하지만 이 전문화가 다른 LLM 애플리케이션을 대체하는 것은 아님. LLM을 추론 모델로 변환하는 것도 나중에 논의할 특정 단점들을 도입하기 때문임.
아래 내용을 간략히 살펴보면, 이 글에서 다룰 내용들:
- "추론 모델"의 의미 설명
- 추론 모델의 장단점 논의
- DeepSeek R1 뒤의 방법론 개요
- 추론 모델을 구축하고 개선하는 네 가지 주요 접근법 설명
- DeepSeek V3와 R1 출시 이후 LLM 환경에 대한 생각 공유
- 제한된 예산으로 추론 모델을 개발하는 팁 제공
AI가 올해 급속한 발전을 계속하는 가운데 이 글이 유용하길 바람!
"추론 모델"을 어떻게 정의할까?
AI(또는 일반적으로 머신러닝) 분야에서 일한다면, 모호하고 격렬하게 논쟁되는 정의들에 익숙할 것임. "추론 모델"이라는 용어도 예외가 아님. 결국 누군가가 논문에서 공식적으로 정의하고, 다음 논문에서 다시 정의되고, 이런 식으로 계속됨.
이 글에서는 "추론"을 중간 단계가 필요한 복잡하고 다단계 생성을 요구하는 질문에 답하는 과정으로 정의함. 예를 들어, "프랑스의 수도는 무엇인가?"와 같은 사실적 질문 답변은 추론을 포함하지 않음. 반면, "기차가 시속 60마일로 움직이며 3시간 동안 여행한다면, 얼마나 멀리 갈까?"와 같은 질문은 간단한 추론이 필요함. 예를 들어, 답에 도달하기 전에 거리, 속도, 시간 간의 관계를 인식해야 함.
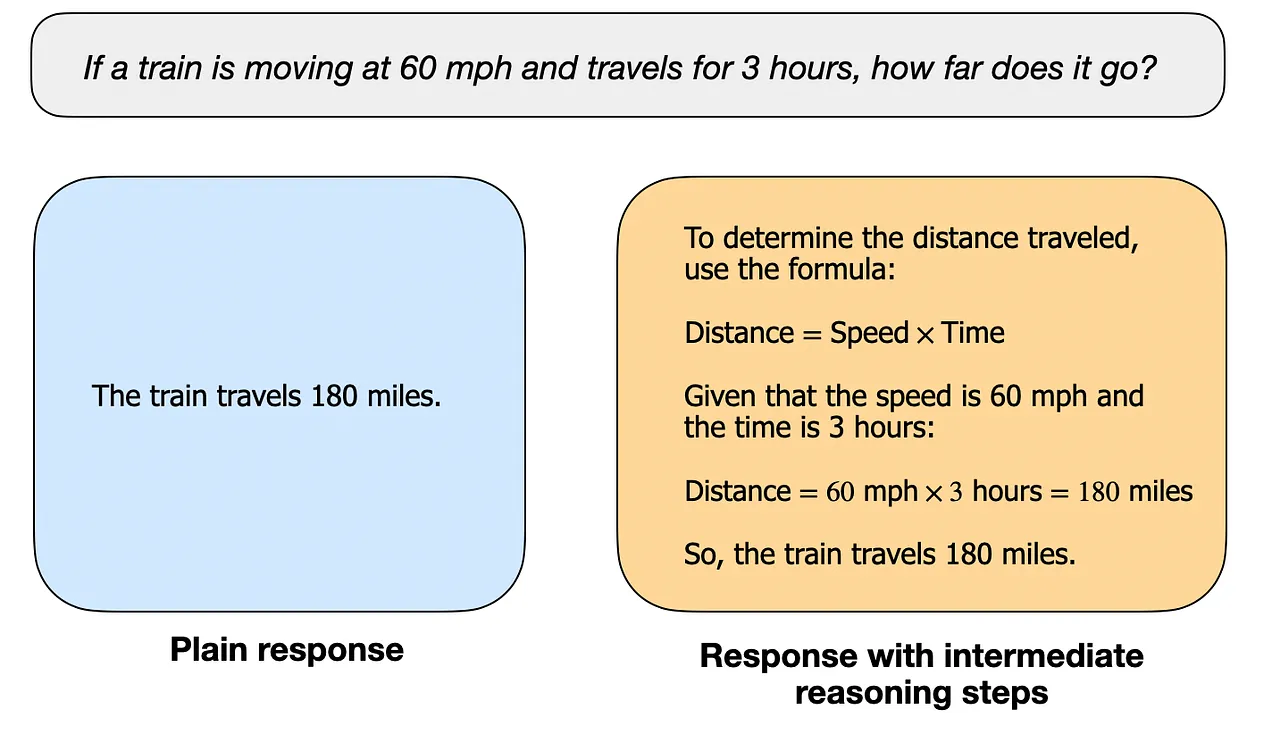
일반적인 LLM은 짧은 답만 제공할 수 있지만(왼쪽에 표시된 것처럼), 추론 모델은 일반적으로 사고 과정의 일부를 드러내는 중간 단계를 포함함. (추론 작업을 위해 특별히 개발되지 않은 많은 LLM들도 답변에서 중간 추론 단계를 제공할 수 있다는 점 참고.)대부분의 현대 LLM들은 기본적인 추론이 가능하며 "기차가 시속 60마일로 움직이며 3시간 동안 여행한다면, 얼마나 멀리 갈까?"와 같은 질문에 답할 수 있음. 그래서 오늘날 추론 모델이라고 할 때는 일반적으로 퍼즐 해결, 수수께끼, 수학적 증명과 같은 더 복잡한 추론 작업에서 뛰어난 LLM을 의미함.
또한, 오늘날 추론 모델로 브랜딩된 대부분의 LLM들은 응답의 일부로 "사고" 또는 "생각" 과정을 포함함. LLM이 실제로 "생각"하는지와 어떻게 생각하는지는 별개의 논의임.
추론 모델의 중간 단계는 두 가지 방식으로 나타날 수 있음. 첫째, 이전 그림에서 보여진 것처럼 응답에 명시적으로 포함될 수 있음. 둘째, OpenAI의 o1과 같은 일부 추론 LLM은 사용자에게 보여지지 않는 중간 단계를 가진 여러 반복을 실행함.

"추론"은 두 가지 다른 수준에서 사용됨: 1) 입력을 처리하고 여러 중간 단계를 통해 생성하는 것과 2) 사용자에게 응답의 일부로 어떤 종류의 추론을 제공하는 것.언제 추론 모델을 사용해야 할까?
추론 모델을 정의했으니, 이제 더 흥미로운 부분으로 넘어갈 수 있음: 추론 작업을 위해 LLM을 구축하고 개선하는 방법. 하지만 기술적 세부사항에 들어가기 전에, 추론 모델이 실제로 언제 필요한지 고려하는 것이 중요함.
언제 추론 모델이 필요할까? 추론 모델은 퍼즐 해결, 고급 수학 문제, 도전적인 코딩 작업과 같은 복잡한 작업에 좋도록 설계됨. 하지만 요약, 번역, 또는 지식 기반 질문 답변과 같은 간단한 작업에는 필요하지 않음. 실제로 모든 것에 추론 모델을 사용하는 것은 비효율적이고 비쌀 수 있음. 예를 들어, 추론 모델은 일반적으로 사용하기 더 비싸고, 더 장황하며, "과도한 사고" 때문에 때때로 오류에 더 취약함. 여기서도 간단한 규칙이 적용됨: 작업에 적합한 도구(또는 LLM의 유형)를 사용하라.
추론 모델의 주요 강점과 제한사항이 아래 그림에 요약되어 있음.
추론 모델의 주요 강점과 약점.DeepSeek 훈련 파이프라인 간략히 살펴보기
다음 섹션에서 추론 모델을 구축하고 개선하는 네 가지 주요 접근법을 논의하기 전에, DeepSeek R1 기술 보고서에 설명된 DeepSeek R1 파이프라인을 간략히 설명하고 싶음. 이 보고서는 흥미로운 사례 연구이자 추론 LLM 개발을 위한 청사진 역할을 함.
DeepSeek은 단일 R1 추론 모델을 출시한 것이 아니라 세 가지 서로 다른 변형을 도입했음: DeepSeek-R1-Zero, DeepSeek-R1, DeepSeek-R1-Distill.
기술 보고서의 설명을 바탕으로, 아래 다이어그램에서 이러한 모델들의 개발 과정을 요약함.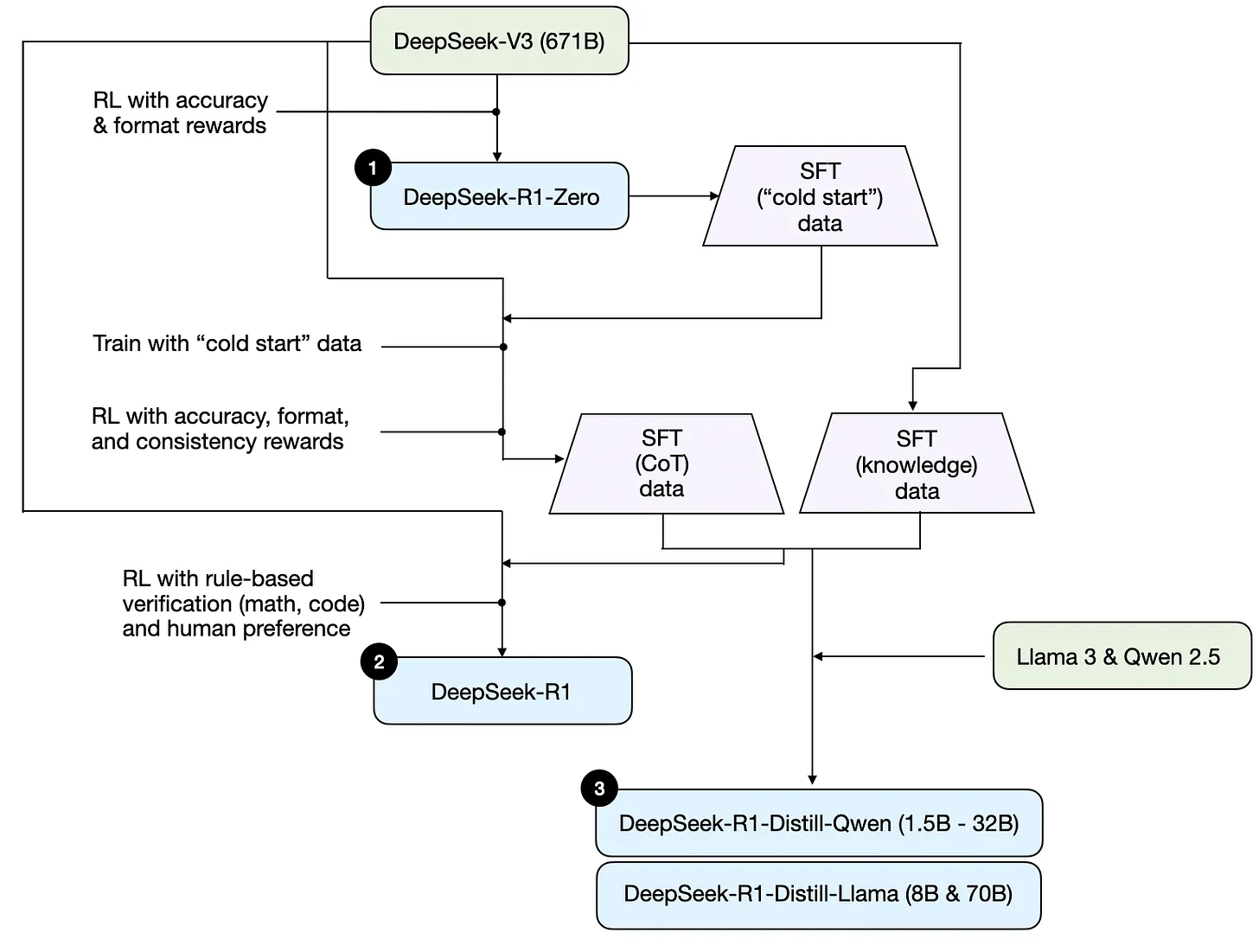
DeepSeek R1 기술 보고서에서 논의된 DeepSeek의 세 가지 다른 추론 모델의 개발 과정.다음으로, 위 다이어그램에 표시된 과정을 간략히 살펴보겠음. 더 자세한 내용은 추론 모델을 구축하고 개선하는 네 가지 주요 접근법을 논의하는 다음 섹션에서 다룰 예정임.
(1) DeepSeek-R1-Zero: 이 모델은 2024년 12월에 출시된 671B 사전 훈련된 DeepSeek-V3 기본 모델을 기반으로 함. 연구팀은 두 가지 유형의 보상을 사용하여 강화학습(RL)으로 훈련시킴. 이 접근법은 일반적으로 인간 피드백을 통한 강화학습(RLHF)의 일부인 지도 파인튜닝(SFT) 단계를 포함하지 않았기 때문에 "콜드 스타트" 훈련이라고 불림.
(2) DeepSeek-R1: 이것은 DeepSeek-R1-Zero를 기반으로 구축된 DeepSeek의 플래그십 추론 모델임. 팀은 추가적인 SFT 단계와 추가 RL 훈련으로 더욱 개선하여, "콜드 스타트"된 R1-Zero 모델을 향상시킴.
(3) DeepSeek-R1-Distill: 이전 단계에서 생성된 SFT 데이터를 사용하여, DeepSeek 팀은 Qwen과 Llama 모델을 파인튜닝하여 추론 능력을 향상시킴. 전통적인 의미의 증류는 아니지만, 이 과정은 더 큰 DeepSeek-R1 671B 모델의 출력으로 더 작은 모델들(Llama 8B와 70B, Qwen 1.5B-30B)을 훈련시키는 것을 포함함.추론 모델을 구축하고 개선하는 4가지 주요 방법
이 섹션에서는 LLM의 추론 능력을 향상시키고 DeepSeek-R1, OpenAI의 o1 & o3와 같은 전문화된 추론 모델을 구축하는 데 현재 사용되는 핵심 기술들을 개괄할 것임.
참고: o1과 o3의 정확한 작동 방식은 OpenAI 외부에서는 알려지지 않음. 하지만 추론과 훈련 기법의 조합을 활용한다는 소문이 있음.1) 추론 시간 스케일링
LLM의 추론 능력(또는 일반적으로 모든 능력)을 향상시키는 한 가지 방법은 추론 시간 스케일링임. 이 용어는 여러 의미를 가질 수 있지만, 이 맥락에서는 추론 중에 계산 자원을 늘려 출력 품질을 향상시키는 것을 의미함.
대략적인 비유로, 인간들이 복잡한 문제를 생각할 시간을 더 많이 받으면 더 나은 응답을 생성하는 경향이 있음. 마찬가지로, LLM이 답을 생성하는 동안 더 "생각"하도록 격려하는 기법들을 적용할 수 있음. (물론 LLM이 실제로 "생각"하는지는 다른 논의임.)
추론 시간 스케일링의 한 가지 직접적인 접근법은 영리한 프롬프트 엔지니어링임. 전형적인 예는 연쇄 사고(CoT) 프롬프팅으로, 입력 프롬프트에 "단계별로 생각해보세요"와 같은 구문을 포함함. 이는 모델이 최종 답으로 직접 뛰어넘기보다는 중간 추론 단계를 생성하도록 격려하며, 이는 종종(항상은 아니지만) 더 복잡한 문제에서 더 정확한 결과로 이어질 수 있음. ("프랑스의 수도는 무엇인가?"와 같은 간단한 지식 기반 질문에는 이 전략을 사용하는 것이 의미가 없다는 점 참고. 이는 다시 주어진 입력 쿼리에서 추론 모델이 의미가 있는지 알아내는 좋은 경험칙임.)

2022년 Large Language Models are Zero-Shot Reasoners 논문의 고전적인 CoT 프롬프팅 예시.앞서 언급한 CoT 접근법은 더 많은 출력 토큰을 생성하여 추론을 더 비싸게 만들기 때문에 추론 시간 스케일링으로 볼 수 있음.
추론 시간 스케일링의 또 다른 접근법은 투표와 검색 전략의 사용임. 간단한 예는 다수결 투표로, LLM이 여러 답을 생성하게 하고 다수결 투표로 올바른 답을 선택함. 마찬가지로, 빔 서치와 다른 검색 알고리즘을 사용하여 더 나은 응답을 생성할 수 있음.

다양한 검색 기반 방법들은 최고의 답을 선택하기 위해 프로세스 보상 기반 모델에 의존함. LLM Test-Time Compute 논문의 주석이 달린 그림.DeepSeek R1 기술 보고서는 일반적인 추론 시간 스케일링 방법들(프로세스 보상 모델 기반 및 몬테카를로 트리 검색 기반 접근법 등)을 "실패한 시도들" 아래로 분류함. 이는 DeepSeek이 V3 기본 모델에 비해 암시적인 추론 시간 스케일링 형태 역할을 하는 더 긴 응답을 생성하는 R1 모델의 자연스러운 경향을 넘어서는 이러한 기법들을 명시적으로 사용하지 않았음을 시사함.
하지만 명시적인 추론 시간 스케일링은 종종 LLM 자체 내에서가 아니라 애플리케이션 계층에서 구현되므로, DeepSeek도 여전히 앱 내에서 그러한 기법들을 적용할 수 있음.
OpenAI의 o1과 o3 모델이 추론 시간 스케일링을 사용한다고 의심하며, 이는 GPT-4o와 같은 모델에 비해 상대적으로 비싼 이유를 설명할 것임. 추론 시간 스케일링에 더해, o1과 o3는 아마도 DeepSeek R1에 사용된 것과 유사한 RL 파이프라인을 사용하여 훈련되었을 것임. 아래 다음 두 섹션에서 강화학습에 대해 더 다룰 예정임.
2) 순수 강화학습(RL)
DeepSeek R1 논문에서 개인적으로 가장 흥미로운 부분 중 하나는 순수 강화학습(RL)에서 추론이 행동으로 나타난다는 발견임. 이것이 더 자세히 무엇을 의미하는지 탐구해보겠음.
앞서 개괄한 바와 같이, DeepSeek은 세 가지 유형의 R1 모델을 개발함. 첫 번째인 DeepSeek-R1-Zero는 2024년 12월에 출시한 표준 사전 훈련된 LLM인 DeepSeek-V3 기본 모델 위에 구축됨. RL 전에 지도 파인튜닝(SFT)이 적용되는 일반적인 RL 파이프라인과 달리, DeepSeek-R1-Zero는 아래 다이어그램에서 강조된 바와 같이 초기 SFT 단계 없이 독점적으로 강화학습으로만 훈련됨.
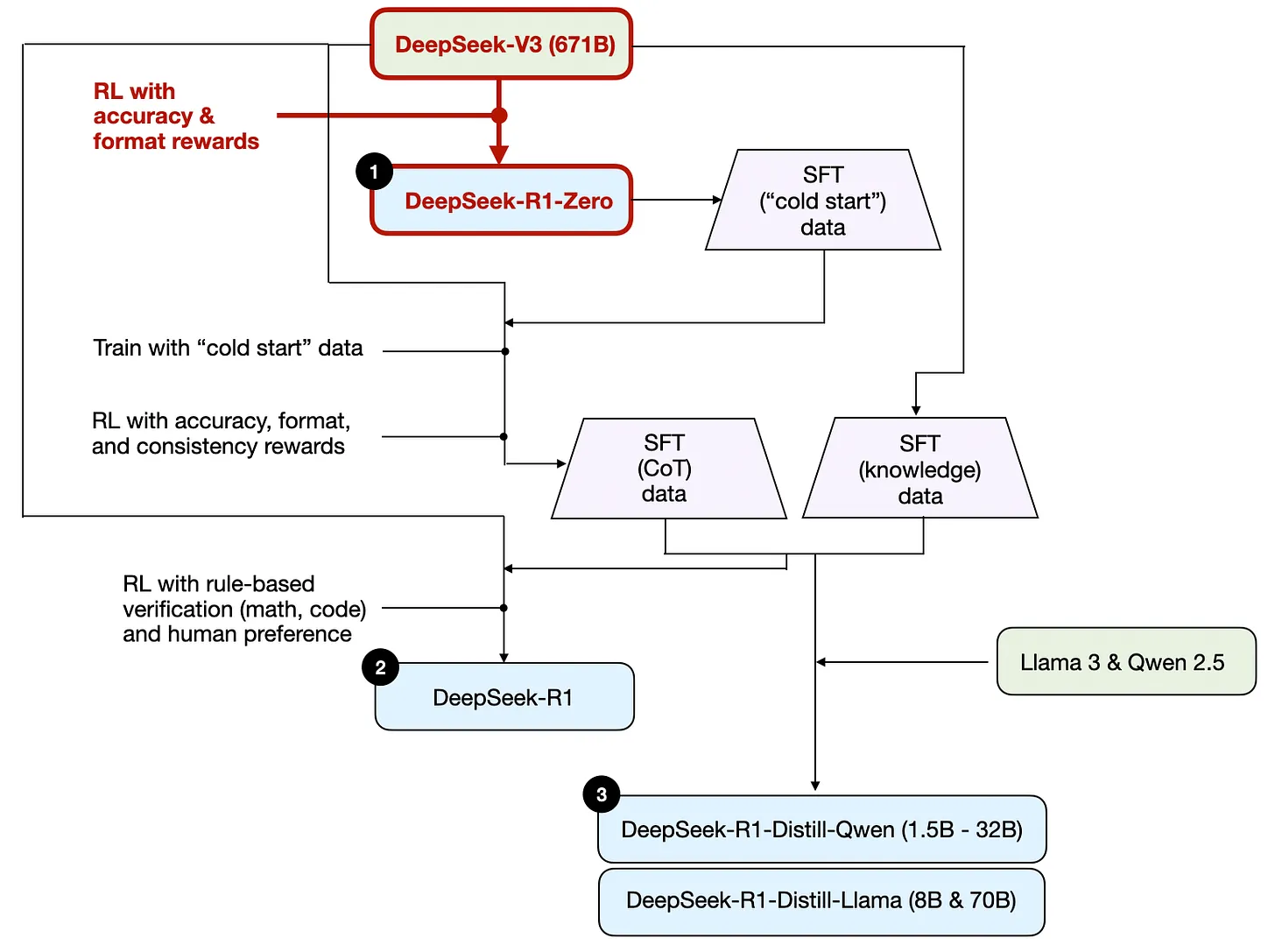
DeepSeek-R1-Zero 모델의 개발 과정.여전히 이 RL 과정은 LLM을 선호도 튜닝하는 데 일반적으로 사용되는 RLHF 접근법과 유사함. (RLHF에 대해서는 LLM Training: RLHF and Its Alternatives 글에서 더 자세히 다룸.) 하지만 위에서 언급했듯이, DeepSeek-R1-Zero의 주요 차이점은 명령어 튜닝을 위한 지도 파인튜닝(SFT) 단계를 건너뛰었다는 것임. 이것이 "순수" RL이라고 부르는 이유임. (비록 LLM 맥락에서의 RL은 전통적인 RL과 상당히 다르며, 이는 다른 시점의 주제임.)
보상의 경우, 인간 선호도로 훈련된 보상 모델을 사용하는 대신, 두 가지 유형의 보상을 사용함: 정확도 보상과 형식 보상.
- 정확도 보상은 LeetCode 컴파일러를 사용하여 코딩 답을 검증하고 수학적 응답을 평가하는 결정론적 시스템을 사용함.
- 형식 보상은 LLM 판사에 의존하여 응답이 추론 단계를 <think> 태그 안에 배치하는 것과 같은 예상 형식을 따르는지 확인함.
놀랍게도, 이 접근법은 LLM이 기본적인 추론 기술을 개발하기에 충분함. 연구자들은 모델이 명시적으로 그렇게 하도록 훈련받지 않았음에도 불구하고 응답의 일부로 추론 추적을 생성하기 시작하는 "아하!" 순간을 관찰함. 아래 그림에서 보여지는 것처럼.
"아하" 순간의 출현을 보여주는 DeepSeek R1 기술 보고서의 그림.
R1-Zero는 최고 성능의 추론 모델은 아니지만, 위 그림에서 보여지는 것처럼 중간 "생각" 단계를 생성하여 추론 능력을 보여줌. 이는 순수 RL을 사용하여 추론 모델을 개발하는 것이 가능하다는 것을 확인하며, DeepSeek 팀이 이 접근법을 최초로 증명(또는 적어도 발표)함.

3) 지도 파인튜닝과 강화학습 (SFT + RL)
다음으로, 추론 모델 구축을 위한 청사진 역할을 하는 DeepSeek의 플래그십 추론 모델인 DeepSeek-R1의 개발을 살펴보겠음. 이 모델은 추론 성능을 향상시키기 위해 추가적인 지도 파인튜닝(SFT)과 강화학습(RL)을 통합하여 DeepSeek-R1-Zero를 개선함.
실제로 표준 RLHF 파이프라인에서 볼 수 있듯이 RL 전에 SFT 단계를 포함하는 것은 일반적임. OpenAI의 o1도 유사한 접근법을 사용하여 개발되었을 가능성이 높음.
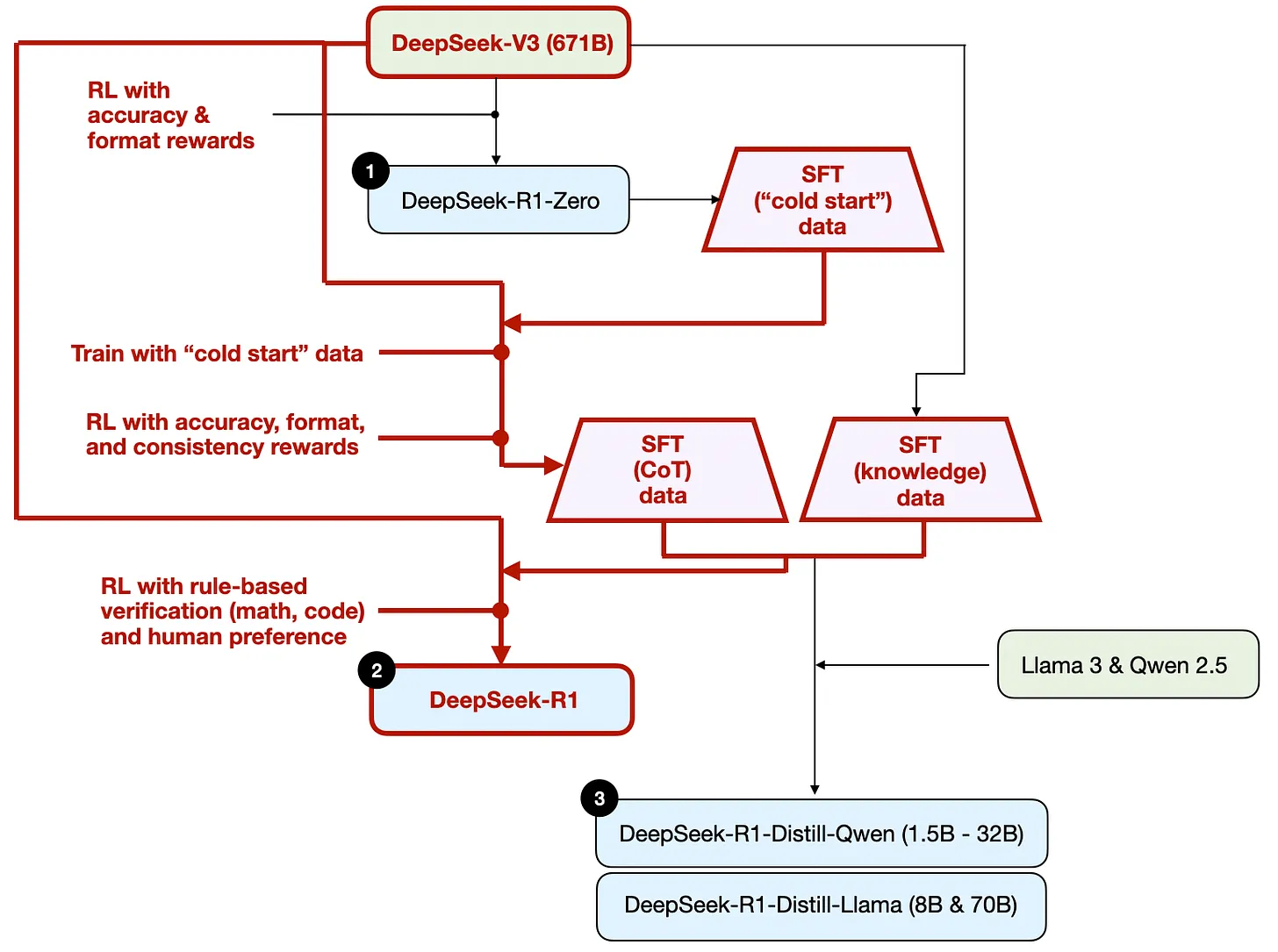
DeepSeek-R1 모델의 개발 과정.- 위 다이어그램에서 보여지는 것처럼, DeepSeek 팀은 DeepSeek-R1-Zero를 사용하여 "콜드 스타트" SFT 데이터라고 부르는 것을 생성함. "콜드 스타트"라는 용어는 이 데이터가 자체적으로 지도 파인튜닝(SFT) 데이터로 훈련받지 않은 DeepSeek-R1-Zero에 의해 생성되었다는 사실을 의미함.
-
이 콜드 스타트 SFT 데이터를 사용하여, DeepSeek은 명령어 파인튜닝을 통해 모델을 훈련시킨 후, 또 다른 강화학습(RL) 단계를 거침. 이 RL 단계는 DeepSeek-R1-Zero의 RL 과정에서 사용된 동일한 정확도와 형식 보상을 유지함. 하지만 응답 내에서 여러 언어를 전환하는 언어 혼합을 방지하기 위해 일관성 보상을 추가함.
- RL 단계 다음에는 또 다른 SFT 데이터 수집 라운드가 이어짐. 이 단계에서는 가장 최근의 모델 체크포인트를 사용하여 600K 연쇄 사고(CoT) SFT 예시를 생성하고, DeepSeek-V3 기본 모델을 사용하여 추가로 200K 지식 기반 SFT 예시를 생성함.
- 이 600K + 200K SFT 샘플들은 최종 RL 라운드를 따르기 전에 DeepSeek-V3 기본을 명령어 파인튜닝하는 데 사용됨. 이 단계에서 수학과 코딩 질문에는 다시 정확도 보상을 위한 규칙 기반 방법을 사용하고, 다른 질문 유형에는 인간 선호도 라벨을 사용함. 전체적으로 이는 SFT 데이터에 (더 많은) CoT 예시가 포함되어 있다는 것을 제외하고는 일반적인 RLHF와 매우 유사함. 그리고 RL은 인간 선호도 기반 보상에 더해 검증 가능한 보상을 가짐.
최종 모델인 DeepSeek-R1은 아래 표에서 보여지는 것처럼 추가적인 SFT와 RL 단계 덕분에 DeepSeek-R1-Zero에 비해 눈에 띄는 성능 향상을 보임.

OpenAI O1과 DeepSeek R1 모델들의 벤치마크 비교. DeepSeek-R1 기술 보고서의 주석이 달린 그림.4) 순수 지도 파인튜닝(SFT)과 증류
지금까지 추론 모델을 구축하고 개선하는 세 가지 핵심 접근법을 다룸:
- 기본 모델을 훈련하거나 수정하지 않고 추론 능력을 향상시키는 기법인 추론 시간 스케일링.
- DeepSeek-R1-Zero에서처럼 지도 파인튜닝 없이도 추론이 학습된 행동으로 나타날 수 있음을 보여준 순수 강화학습(RL).
- DeepSeek의 플래그십 추론 모델인 DeepSeek-R1로 이어진 지도 파인튜닝(SFT) + RL.
그럼 남은 것은? 모델 "증류"임.
놀랍게도, DeepSeek은 증류라고 부르는 과정을 통해 훈련된 더 작은 모델들도 출시함. 하지만 LLM의 맥락에서 증류는 딥러닝에서 사용되는 고전적인 지식 증류 접근법을 반드시 따르지는 않음. 전통적으로, 지식 증류에서는(Machine Learning Q and AI 책의 6장에서 간략히 설명된 바와 같이), 더 작은 학생 모델이 더 큰 교사 모델의 로짓과 타겟 데이터셋 모두로 훈련됨.
대신, 여기서 증류는 Llama 8B와 70B, Qwen 2.5 모델(0.5B부터 32B까지)과 같은 더 작은 LLM들을 더 큰 LLM들에 의해 생성된 SFT 데이터셋으로 명령어 파인튜닝하는 것을 의미함. 구체적으로, 이러한 더 큰 LLM들은 DeepSeek-V3와 DeepSeek-R1의 중간 체크포인트임. 실제로, 이 증류 과정에 사용된 SFT 데이터는 이전 섹션에서 설명한 대로 DeepSeek-R1을 훈련하는 데 사용된 동일한 데이터셋임.
이 과정을 명확히 하기 위해, 아래 다이어그램에서 증류 부분을 강조함.

DeepSeek-R1-Distill 모델들의 개발 과정.왜 이러한 증류된 모델들을 개발했을까? 개인적으로 두 가지 핵심 이유가 있다고 생각함:
- 더 작은 모델들이 더 효율적임. 이는 실행 비용이 더 저렴하다는 의미이지만, 또한 더 낮은 사양의 하드웨어에서도 실행할 수 있어서 나와 같은 많은 연구자들과 개발자들에게 특히 흥미로움.
- 순수 SFT의 사례 연구. 이러한 증류된 모델들은 강화학습 없이 순수 지도 파인튜닝(SFT)만으로 모델이 어디까지 갈 수 있는지를 보여주는 흥미로운 벤치마크 역할을 함.
아래 표는 이러한 증류된 모델들의 성능을 다른 인기 모델들뿐만 아니라 DeepSeek-R1-Zero와 DeepSeek-R1과 비교함.

증류된 모델 대 비증류된 모델의 벤치마크 비교. DeepSeek-R1 기술 보고서의 주석이 달린 그림.보다시피, 증류된 모델들은 DeepSeek-R1보다는 눈에 띄게 약하지만, 규모가 몇 배 작음에도 불구하고 DeepSeek-R1-Zero에 비해서는 놀랍도록 강함. 또한 이러한 모델들이 o1 mini와 비교해서 얼마나 잘 수행하는지도 흥미로움 (o1-mini 자체도 o1의 유사하게 증류된 버전일 수 있다고 의심함).
이 섹션을 결론으로 마무리하기 전에, 언급할 가치가 있는 한 가지 더 흥미로운 비교가 있음. DeepSeek 팀은 DeepSeek-R1-Zero에서 보인 창발적 추론 행동이 더 작은 모델들에서도 나타날 수 있는지 테스트함. 이를 조사하기 위해, DeepSeek-R1-Zero와 동일한 순수 RL 접근법을 Qwen-32B에 직접 적용함.
이 실험의 결과는 아래 표에 요약되어 있으며, QwQ-32B-Preview는 Qwen 팀이 Qwen 2.5 32B를 기반으로 개발한 참조 추론 모델 역할을 함 (훈련 세부사항은 공개되지 않았다고 생각함). 이 비교는 순수 RL만으로도 DeepSeek-R1-Zero보다 훨씬 작은 모델에서 추론 능력을 유도할 수 있는지에 대한 추가적인 통찰을 제공함.

더 작은 32B 모델에서의 증류와 RL 벤치마크 비교. DeepSeek-R1 기술 보고서의 주석이 달린 그림.흥미롭게도, 결과들은 증류가 더 작은 모델들에게는 순수 RL보다 훨씬 더 효과적임을 시사함. 이는 RL만으로는 이 규모의 모델에서 강한 추론 능력을 유도하기에 충분하지 않을 수 있는 반면, 고품질 추론 데이터에 대한 SFT는 작은 모델로 작업할 때 더 효과적인 전략이 될 수 있다는 아이디어와 일치함.
완성도를 위해, 표에서 추가적인 비교들을 보는 것이 유용했을 것임:
- DeepSeek-R1이 개발된 방식과 유사하게 SFT + RL로 훈련된 Qwen-32B. 이는 순수 RL과 순수 SFT에 비해 RL이 SFT와 결합될 때 얼마나 개선될 수 있는지 결정하는 데 도움이 될 것임.
- 증류된 모델들이 생성된 방식과 유사하게 순수 SFT로 훈련된 DeepSeek-V3. 이는 RL + SFT가 순수 SFT에 비해 얼마나 효과적인지 직접 비교할 수 있게 해줄 것임.
결론
이 섹션에서는 추론 모델을 구축하고 개선하는 네 가지 다른 전략을 탐구함:
- 추론 시간 스케일링은 추가 훈련이 필요하지 않지만 추론 비용을 증가시켜서 사용자 수나 쿼리 볼륨이 증가함에 따라 대규모 배포를 더 비싸게 만듦. 그럼에도 불구하고, 이미 강한 모델의 성능을 향상시키는 데는 여전히 당연한 선택임. o1이 추론 시간 스케일링을 활용한다고 강하게 의심하며, 이는 DeepSeek-R1에 비해 토큰당 더 비싼 이유를 설명하는 데 도움이 됨.
- 순수 RL은 추론을 창발적 행동으로서의 통찰을 제공하기 때문에 연구 목적으로는 흥미로움. 하지만 실용적인 모델 개발에서는 RL + SFT가 더 강한 추론 모델로 이어지므로 선호되는 접근법임. o1도 RL + SFT를 사용하여 훈련되었다고 강하게 의심함. 더 정확히 말하면, o1은 DeepSeek-R1보다 더 약하고 작은 기본 모델에서 시작하지만 RL + SFT와 추론 시간 스케일링으로 보상한다고 믿음.
- 위에서 언급했듯이, RL + SFT는 고성능 추론 모델을 구축하는 핵심 접근법임. DeepSeek-R1은 이것이 어떻게 이루어질 수 있는지를 보여주는 좋은 청사진임.
- 증류는 특히 더 작고 효율적인 모델을 만드는 데 매력적인 접근법임. 하지만 한계는 증류가 혁신을 주도하거나 차세대 추론 모델을 생산하지 않는다는 것임. 예를 들어, 증류는 항상 지도 파인튜닝(SFT) 데이터를 생성하기 위해 기존의 더 강한 모델에 의존함.
다음에 보게 될 흥미로운 측면 중 하나는 RL + SFT(접근법 3)와 추론 시간 스케일링(접근법 1)을 결합하는 것임. 이는 아마도 OpenAI o1이 하고 있는 것으로, DeepSeek-R1보다 더 약한 기본 모델을 기반으로 하고 있을 것이며, 이는 DeepSeek-R1이 추론 시간에 상대적으로 저렴하면서도 그렇게 잘 수행하는 이유를 설명함.DeepSeek R1에 대한 생각
최근 몇 주 동안 많은 사람들이 DeepSeek-R1 모델에 대한 생각을 물어봄. 간단히 말해서, 이들은 놀라운 성취라고 생각함. 연구 엔지니어로서, 내가 배울 수 있는 방법론에 대한 통찰을 제공하는 상세한 기술 보고서를 특히 높이 평가함.
가장 매력적인 결론 중 하나는 순수 RL에서 추론이 행동으로 나타났다는 것임. 그리고 DeepSeek이 Meta의 Llama 모델보다도 더 적은 제한이 있는 허용적인 오픈소스 MIT 라이선스 하에 모델들을 오픈소스화한 것도 인상적임.o1과 어떻게 비교될까?
DeepSeek-R1이 o1보다 나을까? 대략 비슷한 수준이라고 말하겠음. 하지만 눈에 띄는 것은 DeepSeek-R1이 추론 시간에 더 효율적이라는 것임. 이는 DeepSeek이 훈련 과정에 더 많이 투자한 반면, OpenAI는 o1을 위해 추론 시간 스케일링에 더 의존했을 수 있음을 시사함.
그렇긴 하지만, OpenAI가 o1에 대해 많은 것을 공개하지 않았기 때문에 o1과 DeepSeek-R1을 직접 비교하기는 어려움. 예를 들어, 우리는 다음을 모름:- o1도 전문가 혼합(MoE)인가?
- o1은 얼마나 큰가?
- o1이 단지 최소한의 RL + SFT와 광범위한 추론 시간 스케일링만을 가진 GPT-4o의 약간 개선된 버전일 수 있을까?
이러한 세부사항들을 모르면, 직접 비교는 여전히 사과와 오렌지를 비교하는 것임.
DeepSeek-R1의 훈련 비용
또 다른 논의점은 DeepSeek-R1 개발 비용이었음. 일부는 약 600만 달러의 훈련 비용을 언급했지만, 아마도 DeepSeek-V3(작년 12월에 출시된 기본 모델)와 DeepSeek-R1을 혼동했을 것임.
600만 달러 추정치는 가정된 GPU 시간당 2달러와 2024년 12월에 원래 논의된 DeepSeek-V3의 최종 훈련 실행에 필요한 GPU 시간 수를 기반으로 함.
하지만 DeepSeek 팀은 R1의 정확한 GPU 시간이나 개발 비용을 공개한 적이 없으므로, 모든 비용 추정치는 순전한 추측임.
어쨌든, 궁극적으로 DeepSeek-R1은 오픈 웨이트 추론 모델의 주요 이정표이며, 추론 시간의 효율성은 OpenAI의 o1에 대한 흥미로운 대안이 됨.제한된 예산으로 추론 모델 개발하기
DeepSeek-V3와 같은 오픈 웨이트 기본 모델에서 시작하더라도 DeepSeek-R1 수준의 추론 모델을 개발하는 데는 수십만에서 수백만 달러가 필요할 가능성이 높음. 이는 제한된 예산으로 작업하는 연구자나 엔지니어들에게는 낙담스럽게 느껴질 수 있음.
좋은 소식: 증류가 큰 도움이 됨
다행히도, 모델 증류는 더 비용 효율적인 대안을 제공함. DeepSeek 팀은 DeepSeek-R1보다 상당히 작음에도 불구하고 놀랍도록 강한 추론 성능을 달성하는 R1-증류 모델들로 이를 입증함. 하지만 이 접근법도 완전히 저렴하지는 않음. 그들의 증류 과정은 상당한 컴퓨팅을 요구하는 800K SFT 샘플을 사용함.
흥미롭게도, DeepSeek-R1이 출시되기 불과 며칠 전에, 소규모 팀이 단 17K SFT 샘플만을 사용하여 오픈 웨이트 32B 모델을 훈련시킨 매력적인 프로젝트인 Sky-T1에 대한 글을 발견함. 총 비용은? 단 450달러로, 대부분의 AI 컨퍼런스 등록비보다도 적음.
이 예시는 대규모 훈련이 여전히 비싸지만, 더 작고 타겟팅된 파인튜닝 노력들은 여전히 비용의 일부로 인상적인 결과를 낼 수 있음을 강조함.
"Sky-T1: Train your own O1 preview model within $450" 글의 그림.
그들의 벤치마크에 따르면, Sky-T1은 낮은 훈련 비용을 고려할 때 인상적인 o1과 대략 동등한 성능을 보임.예산 내 순수 RL: TinyZero
Sky-T1이 모델 증류에 초점을 맞춘 반면, "순수 RL" 공간에서도 흥미로운 작업을 발견함. 주목할 만한 예는 DeepSeek-R1-Zero 접근법을 복제하는 3B 파라미터 모델인 TinyZero임 (부수적으로, 훈련 비용이 30달러 미만임).
놀랍게도 단 3B 파라미터에서도 TinyZero는 일부 창발적 자기 검증 능력을 보여주며, 이는 순수 RL을 통해 추론이 나타날 수 있다는 아이디어를, 심지어 작은 모델에서도 지원함.
TinyZero 저장소는 연구 보고서가 아직 작업 중이라고 언급하며, 더 자세한 내용을 확실히 주목하고 있을 것임.
모델이 자기 검증이 가능함을 보여주는 TinyZero 저장소의 그림. (비교를 위해 기본 모델의 응답을 보는 것이 흥미로웠을 것임.)위에서 언급한 두 프로젝트는 제한된 예산으로도 추론 모델에 대한 흥미로운 작업이 가능함을 보여줌. 두 접근법 모두 DeepSeek-R1의 방법들을 복제하는데, 하나는 순수 RL(TinyZero)에, 다른 하나는 순수 SFT(Sky-T1)에 초점을 맞추고 있어, 이러한 아이디어들이 어떻게 더 확장될 수 있는지 탐구하는 것이 매력적일 것임.
논문의 핵심 아이디어는 "지름길 학습"의 대안으로서 **"여정 학습"**임.지름길 학습은 모델이 올바른 해결 경로만을 사용하여 훈련되는 명령어 파인튜닝의 전통적인 접근법을 의미함.
반면 여정 학습은 잘못된 해결 경로도 포함하여 모델이 실수로부터 학습할 수 있게 함.
이 접근법은 TinyZero의 순수 RL 훈련에서 관찰된 자기 검증 능력과 어느 정도 관련이 있지만, 전적으로 SFT를 통해 모델을 개선하는 데 초점을 맞춤. 모델을 잘못된 추론 경로와 그 수정에 노출시킴으로써, 여정 학습은 또한 자기 수정 능력을 강화할 수 있어, 잠재적으로 추론 모델을 이런 방식으로 더 신뢰할 수 있게 만들 수 있음.

전통적인 지름길 학습과 달리 SFT 데이터에 잘못된 해결 경로를 포함하는 여정 학습. O1 Replication Journey: A Strategic Progress Report – Part 1의 주석이 달린 그림.
이는 특히 RL 기반 접근법이 계산적으로 비실용적일 수 있는 저예산 추론 모델 개발을 위한 흥미로운 미래 작업 방향이 될 수 있음.
어쨌든, 추론 모델 분야에서 현재 많은 흥미로운 작업이 일어나고 있으며, 앞으로 몇 달 안에 더 많은 흥미진진한 작업을 보게 될 것이 확실함!- 논문은 또한 추론 모델을 프롬프팅하는 방법에 대한 몇 가지 통찰을 포함함:
(1) 제로샷이 퓨샷보다 우수함 - 그들의 광범위한 테스트는 퓨샷 프롬프팅이 전통적인 LLM 모범 사례와 달리 일관되게 모델 성능을 저하시킨다는 것을 밝혀냄.(3) 언어 일관성이 중요함 - 프롬프트 전체에서 동일한 언어를 사용하는 것이 중요한데, 프롬프트에 여러 언어가 포함되어 있을 때 모델이 추론 체인에서 언어를 혼합할 수 있기 때문임. - [원문] https://magazine.sebastianraschka.com/p/understanding-reasoning-llms
- (2) 직접적인 문제 설명이 승리함 - 모델은 사용자가 단순히 문제를 명시하고 출력 형식을 지정할 때 최고의 성능을 보이며, 복잡한 프롬프팅 패턴을 피함.
추론 LLM 이해하기
이 아티클은 추론 모델을 구축하는 네 가지 주요 접근법, 즉 LLM에 추론 능력을 향상시키는 방법에 대해 설명함. 이 글이 가치 있는 통찰을 제공하고 이 주제를 둘러싼 빠르게 발전하는 문헌과 과대광고를 탐색하는 데 도움이 되길 바람.
2024년에 LLM 분야는 점점 더 전문화되는 모습을 보임. 사전 훈련과 파인튜닝을 넘어서, RAG부터 코드 어시스턴트까지 전문화된 애플리케이션의 부상을 목격함. 이 트렌드가 2025년에도 가속화될 것으로 예상되며, 도메인과 애플리케이션 특화 최적화(즉, "전문화")에 더욱 중점을 둘 것임.
1-3단계가 LLM 개발의 일반적인 단계들임. 4단계는 특정 사용 사례를 위해 LLM을 전문화함.추론 모델의 개발은 이러한 전문화 중 하나임. 이는 퍼즐, 고급 수학, 코딩 챌린지와 같이 중간 단계가 있어야 가장 잘 해결되는 복잡한 작업에서 뛰어난 성과를 내도록 LLM을 개선한다는 의미임. 하지만 이 전문화가 다른 LLM 애플리케이션을 대체하는 것은 아님. LLM을 추론 모델로 변환하는 것도 나중에 논의할 특정 단점들을 도입하기 때문임.
아래 내용을 간략히 살펴보면, 이 글에서 다룰 내용들:
- "추론 모델"의 의미 설명
- 추론 모델의 장단점 논의
- DeepSeek R1 뒤의 방법론 개요
- 추론 모델을 구축하고 개선하는 네 가지 주요 접근법 설명
- DeepSeek V3와 R1 출시 이후 LLM 환경에 대한 생각 공유
- 제한된 예산으로 추론 모델을 개발하는 팁 제공
AI가 올해 급속한 발전을 계속하는 가운데 이 글이 유용하길 바람!
"추론 모델"을 어떻게 정의할까?
AI(또는 일반적으로 머신러닝) 분야에서 일한다면, 모호하고 격렬하게 논쟁되는 정의들에 익숙할 것임. "추론 모델"이라는 용어도 예외가 아님. 결국 누군가가 논문에서 공식적으로 정의하고, 다음 논문에서 다시 정의되고, 이런 식으로 계속됨.
이 글에서는 "추론"을 중간 단계가 필요한 복잡하고 다단계 생성을 요구하는 질문에 답하는 과정으로 정의함. 예를 들어, "프랑스의 수도는 무엇인가?"와 같은 사실적 질문 답변은 추론을 포함하지 않음. 반면, "기차가 시속 60마일로 움직이며 3시간 동안 여행한다면, 얼마나 멀리 갈까?"와 같은 질문은 간단한 추론이 필요함. 예를 들어, 답에 도달하기 전에 거리, 속도, 시간 간의 관계를 인식해야 함.
일반적인 LLM은 짧은 답만 제공할 수 있지만(왼쪽에 표시된 것처럼), 추론 모델은 일반적으로 사고 과정의 일부를 드러내는 중간 단계를 포함함. (추론 작업을 위해 특별히 개발되지 않은 많은 LLM들도 답변에서 중간 추론 단계를 제공할 수 있다는 점 참고.)대부분의 현대 LLM들은 기본적인 추론이 가능하며 "기차가 시속 60마일로 움직이며 3시간 동안 여행한다면, 얼마나 멀리 갈까?"와 같은 질문에 답할 수 있음. 그래서 오늘날 추론 모델이라고 할 때는 일반적으로 퍼즐 해결, 수수께끼, 수학적 증명과 같은 더 복잡한 추론 작업에서 뛰어난 LLM을 의미함.
또한, 오늘날 추론 모델로 브랜딩된 대부분의 LLM들은 응답의 일부로 "사고" 또는 "생각" 과정을 포함함. LLM이 실제로 "생각"하는지와 어떻게 생각하는지는 별개의 논의임.
추론 모델의 중간 단계는 두 가지 방식으로 나타날 수 있음. 첫째, 이전 그림에서 보여진 것처럼 응답에 명시적으로 포함될 수 있음. 둘째, OpenAI의 o1과 같은 일부 추론 LLM은 사용자에게 보여지지 않는 중간 단계를 가진 여러 반복을 실행함.
"추론"은 두 가지 다른 수준에서 사용됨: 1) 입력을 처리하고 여러 중간 단계를 통해 생성하는 것과 2) 사용자에게 응답의 일부로 어떤 종류의 추론을 제공하는 것.언제 추론 모델을 사용해야 할까?
추론 모델을 정의했으니, 이제 더 흥미로운 부분으로 넘어갈 수 있음: 추론 작업을 위해 LLM을 구축하고 개선하는 방법. 하지만 기술적 세부사항에 들어가기 전에, 추론 모델이 실제로 언제 필요한지 고려하는 것이 중요함.
언제 추론 모델이 필요할까? 추론 모델은 퍼즐 해결, 고급 수학 문제, 도전적인 코딩 작업과 같은 복잡한 작업에 좋도록 설계됨. 하지만 요약, 번역, 또는 지식 기반 질문 답변과 같은 간단한 작업에는 필요하지 않음. 실제로 모든 것에 추론 모델을 사용하는 것은 비효율적이고 비쌀 수 있음. 예를 들어, 추론 모델은 일반적으로 사용하기 더 비싸고, 더 장황하며, "과도한 사고" 때문에 때때로 오류에 더 취약함. 여기서도 간단한 규칙이 적용됨: 작업에 적합한 도구(또는 LLM의 유형)를 사용하라.
추론 모델의 주요 강점과 제한사항이 아래 그림에 요약되어 있음.
추론 모델의 주요 강점과 약점.DeepSeek 훈련 파이프라인 간략히 살펴보기
다음 섹션에서 추론 모델을 구축하고 개선하는 네 가지 주요 접근법을 논의하기 전에, DeepSeek R1 기술 보고서에 설명된 DeepSeek R1 파이프라인을 간략히 설명하고 싶음. 이 보고서는 흥미로운 사례 연구이자 추론 LLM 개발을 위한 청사진 역할을 함.
DeepSeek은 단일 R1 추론 모델을 출시한 것이 아니라 세 가지 서로 다른 변형을 도입했음: DeepSeek-R1-Zero, DeepSeek-R1, DeepSeek-R1-Distill.
기술 보고서의 설명을 바탕으로, 아래 다이어그램에서 이러한 모델들의 개발 과정을 요약함.
DeepSeek R1 기술 보고서에서 논의된 DeepSeek의 세 가지 다른 추론 모델의 개발 과정.다음으로, 위 다이어그램에 표시된 과정을 간략히 살펴보겠음. 더 자세한 내용은 추론 모델을 구축하고 개선하는 네 가지 주요 접근법을 논의하는 다음 섹션에서 다룰 예정임.
(1) DeepSeek-R1-Zero: 이 모델은 2024년 12월에 출시된 671B 사전 훈련된 DeepSeek-V3 기본 모델을 기반으로 함. 연구팀은 두 가지 유형의 보상을 사용하여 강화학습(RL)으로 훈련시킴. 이 접근법은 일반적으로 인간 피드백을 통한 강화학습(RLHF)의 일부인 지도 파인튜닝(SFT) 단계를 포함하지 않았기 때문에 "콜드 스타트" 훈련이라고 불림.
(2) DeepSeek-R1: 이것은 DeepSeek-R1-Zero를 기반으로 구축된 DeepSeek의 플래그십 추론 모델임. 팀은 추가적인 SFT 단계와 추가 RL 훈련으로 더욱 개선하여, "콜드 스타트"된 R1-Zero 모델을 향상시킴.
(3) DeepSeek-R1-Distill: 이전 단계에서 생성된 SFT 데이터를 사용하여, DeepSeek 팀은 Qwen과 Llama 모델을 파인튜닝하여 추론 능력을 향상시킴. 전통적인 의미의 증류는 아니지만, 이 과정은 더 큰 DeepSeek-R1 671B 모델의 출력으로 더 작은 모델들(Llama 8B와 70B, Qwen 1.5B-30B)을 훈련시키는 것을 포함함.추론 모델을 구축하고 개선하는 4가지 주요 방법
이 섹션에서는 LLM의 추론 능력을 향상시키고 DeepSeek-R1, OpenAI의 o1 & o3와 같은 전문화된 추론 모델을 구축하는 데 현재 사용되는 핵심 기술들을 개괄할 것임.
참고: o1과 o3의 정확한 작동 방식은 OpenAI 외부에서는 알려지지 않음. 하지만 추론과 훈련 기법의 조합을 활용한다는 소문이 있음.1) 추론 시간 스케일링
LLM의 추론 능력(또는 일반적으로 모든 능력)을 향상시키는 한 가지 방법은 추론 시간 스케일링임. 이 용어는 여러 의미를 가질 수 있지만, 이 맥락에서는 추론 중에 계산 자원을 늘려 출력 품질을 향상시키는 것을 의미함.
대략적인 비유로, 인간들이 복잡한 문제를 생각할 시간을 더 많이 받으면 더 나은 응답을 생성하는 경향이 있음. 마찬가지로, LLM이 답을 생성하는 동안 더 "생각"하도록 격려하는 기법들을 적용할 수 있음. (물론 LLM이 실제로 "생각"하는지는 다른 논의임.)
추론 시간 스케일링의 한 가지 직접적인 접근법은 영리한 프롬프트 엔지니어링임. 전형적인 예는 연쇄 사고(CoT) 프롬프팅으로, 입력 프롬프트에 "단계별로 생각해보세요"와 같은 구문을 포함함. 이는 모델이 최종 답으로 직접 뛰어넘기보다는 중간 추론 단계를 생성하도록 격려하며, 이는 종종(항상은 아니지만) 더 복잡한 문제에서 더 정확한 결과로 이어질 수 있음. ("프랑스의 수도는 무엇인가?"와 같은 간단한 지식 기반 질문에는 이 전략을 사용하는 것이 의미가 없다는 점 참고. 이는 다시 주어진 입력 쿼리에서 추론 모델이 의미가 있는지 알아내는 좋은 경험칙임.)
2022년 Large Language Models are Zero-Shot Reasoners 논문의 고전적인 CoT 프롬프팅 예시.앞서 언급한 CoT 접근법은 더 많은 출력 토큰을 생성하여 추론을 더 비싸게 만들기 때문에 추론 시간 스케일링으로 볼 수 있음.
추론 시간 스케일링의 또 다른 접근법은 투표와 검색 전략의 사용임. 간단한 예는 다수결 투표로, LLM이 여러 답을 생성하게 하고 다수결 투표로 올바른 답을 선택함. 마찬가지로, 빔 서치와 다른 검색 알고리즘을 사용하여 더 나은 응답을 생성할 수 있음.
다양한 검색 기반 방법들은 최고의 답을 선택하기 위해 프로세스 보상 기반 모델에 의존함. LLM Test-Time Compute 논문의 주석이 달린 그림.DeepSeek R1 기술 보고서는 일반적인 추론 시간 스케일링 방법들(프로세스 보상 모델 기반 및 몬테카를로 트리 검색 기반 접근법 등)을 "실패한 시도들" 아래로 분류함. 이는 DeepSeek이 V3 기본 모델에 비해 암시적인 추론 시간 스케일링 형태 역할을 하는 더 긴 응답을 생성하는 R1 모델의 자연스러운 경향을 넘어서는 이러한 기법들을 명시적으로 사용하지 않았음을 시사함.
하지만 명시적인 추론 시간 스케일링은 종종 LLM 자체 내에서가 아니라 애플리케이션 계층에서 구현되므로, DeepSeek도 여전히 앱 내에서 그러한 기법들을 적용할 수 있음.
OpenAI의 o1과 o3 모델이 추론 시간 스케일링을 사용한다고 의심하며, 이는 GPT-4o와 같은 모델에 비해 상대적으로 비싼 이유를 설명할 것임. 추론 시간 스케일링에 더해, o1과 o3는 아마도 D
728x90'AI > NLP' 카테고리의 다른 글






