-
Mask R-CNN 흐름 정리 (R-CNN, Fast R-CNN, Faster R-CNN)AI/Object Detection & Pose Estimation 2021. 9. 9. 20:44728x90
Computer Vision 분야에는 Image Classification 외에도 Semantic Segmentation, Classification + Localization, Object Detection, Instance Segmentation와 같은 Task들이 있음
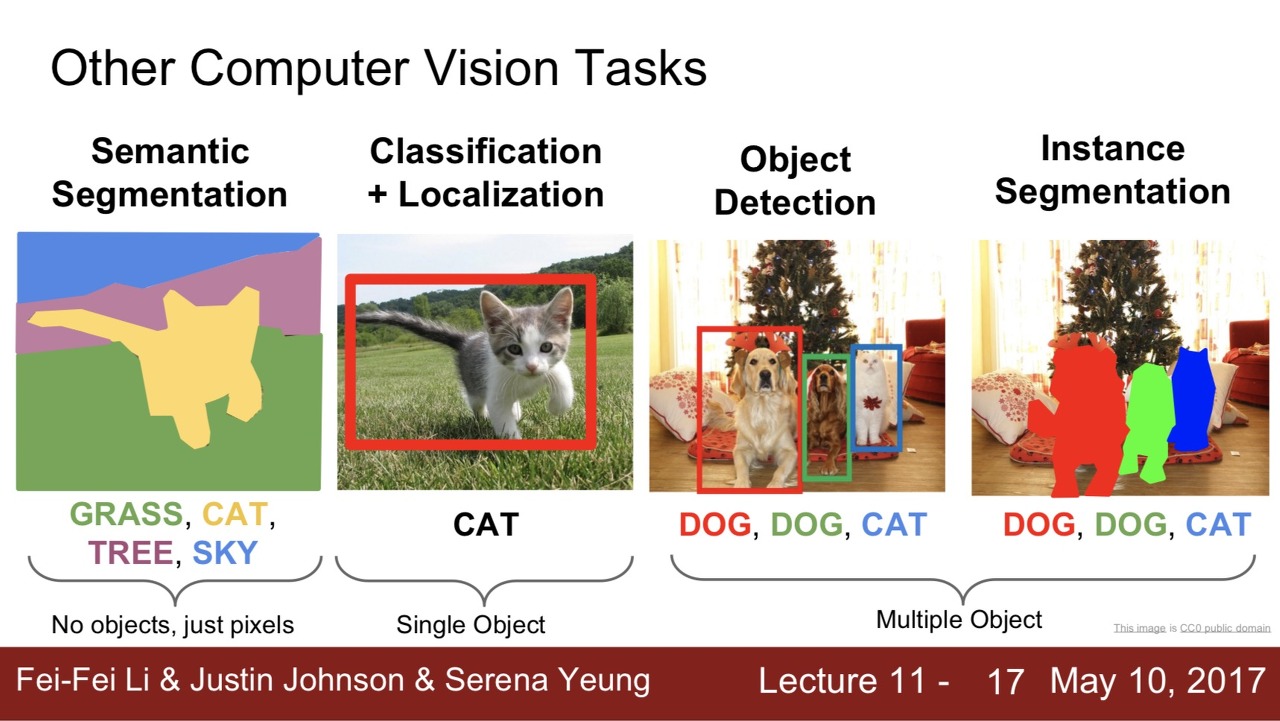
1. Semantic Segmentation
a. 이미지의 모든 픽셀에 카테고리를 정함
b. 하지만, 픽셀로 카테고리를 정해서 instance를 구별할 수 없음
2. Classification+Localization
a. Single Object Detection
b. Single object에 대해서 object의 위치를 bounding box로 찾고 (Localization) + 클래스를 분류하는 문제 (Classification)
c. Localization(Pixel) 문제를 Regression 문제로 취급할 수 있음
3. Object Detection
a. Multiple Object Detection
b. Multiple objects에서 각각의 object에 대해 Classification + Localization을 수행하는 것
c. 하지만 고정된 클래스 내에서 instance 구별해내지 못함 (ex. 여러 사람이 있다면 사람들이라는 것만 구분할 뿐, 블랙핑크의 지수인지 리사인지 구분해내지 못함)
d. R-CNN, Fast R-CNN, Faster R-CNN 방식으로 해결
4. Instance Segmentation
a. Multiple Object Detection
b. object의 위치를 bounding box가 아닌 실제 edge로 찾는 것
c. 이미지 내의 모든 객체를 찾고, 찾은 객체에 대해 instance들을 Pixel-wise Classification
d. Mask R-CNN 방식으로 해결
기존의 Object Detection 방식들

1. R-CNN
기존의 Sliding Window 방식 대신에 Region Proposal 방식 사용!
- Sliding Window 방식은 일정한 크기를 가지는 Window를 통해 Window의 크기와 비율을 바꿔가며 이미지의 모든 영역을 탐색하여 비효율적.
- 그 대신 Region Proposal (Selective Search) 방식을 통해 이미지로부터 Object가 있을 만한 범위를 찾는다.

1. Hypothesize Bounding Boxes (Proposals)
a. Image로부터 Object가 존재할 적절한 위치에 Bounding Box Proposal (Selective Search)
b. 2000개의 Proposal이 생성됨. 각각의 Region Proposal들은 사각형 모양의 Bounding Box 안의 이미지 형태
2. Resampling pixels / Features for each boxes
a. 위의 모든 Region Proposal을 crop한 후 동일한 크기로 만듦 (244 X 244)
3. Classifier / Bounding Box Regressor
a. 위의 영상을 Classifier와 Bounding Box Regressor로 처리.
b. CNN Classifier만으로 Region Proposal을 통해 이미지 분류하면 물체의 정확한 위치를 파악할 수 없기 때문에, 각각의 Bounding Box가 그 내부에 포함된 물체의 위치와 크기를 잡아줄 수 있도록 하는 작업을 수행하는 Regressor 추가적으로 이용
⇒ 하지만 (1) 모든 Proposal 에 대해 CNN을 거쳐야 하므로 연산량이 매우 많은 단점과, (2) multi-stage pipelines으로써 모델을 한번에 학습시키지 못한다는 단점이 존재
2. Fast R-CNN
각 Proposal들이 CNN을 거치는 R-CNN의 단점을 개선하고자,
(1) 전체 이미지에 대해 CNN을 한번 거친 후 출력된 Feature map단에서 RoI Pooling을 통해 객체 탐지를 수행하며,
(2) CNN 특징 추출부터 classification, bounding box regression까지 하나의 모델에서 학습한다

1. R-CNN에서와 마찬가지로 Selective Search를 통해 RoI를 찾은 후, 전체 이미지를 CNN에 통과시켜 feature map을 추출한다.
2. Selective Search로 찾았었던 RoI를 feature map크기에 맞춰서 projection시킨다.
3. projection시킨 RoI에 대해 RoI Pooling을 진행하여 고정된 크기의 feature vector를 얻는다.
a. 미리 설정한 HxW크기로 만들어주기 위해서 (h/H) * (w/H) 크기만큼 grid를 RoI위에 만든다.
b. RoI를 grid크기로 split시킨 뒤 max pooling을 적용시켜 결국 각 grid 칸마다 하나의 값을 추출한다. 즉, feature map에 투영했던 hxw크기의 RoI는 HxW크기의 고정된 feature vector로 변환.
4. feature vector는 FC layer를 통과한 뒤, 구 브랜치로 나뉘게 된다.
5. 하나는 softmax를 통과하여 RoI에 대해 object classification을 한다. bounding box regression을 통해 selective search로 찾은 box의 위치를 조정한다.
⇒ 하지만 아직도 Region Proposal을 생성하는 방식, 즉 Selective Search 자체(2000개의 Region Proposal 생성)가 병목 현상을 일으킴.
3. Faster R-CNN
Fast R-CNN의 RP 생성하는 방식을 개선하고자, CNN을 활용하여 RPN(Region Proposal Network)으로 RP 생성함. 즉, Region Proposal을 생성하는 방법 자체를 CNN 내부에 네트워크 구조로 넣어 놓음.
RPN을 통해, RoI Pooling을 수행하는 레이어와 Bounding Box를 추출하는 레이어가 같은 특징 맵을 공유할 수 있음.
https://velog.io/@minkyu4506/Faster-R-CNN-리뷰-with-Code 에 구현 코드 有

1. 입력 이미지에 대해 통째로 Convolution Layer를 여러 번 거쳐서 특징 추출. 이 출력 특징 맵을 RPN과 RoI Pooling Layer가 공유하게 됨.
2. RPN은 특징맵에서 Region Proposal들을 추출해 내고, RoI Pooling Layer는 RPN에서 추출된 Region Proposal들에 대해 RoI 풀링을 수행함.
a. 출력 특징 맵 위를 도는 지정한 크기의 Window를 Sliding 하면서, Window가 지나가는 각 지점마다 지정된 크기의 anchor를 지정한 개수만큼 생성
b. 모든 anchor들에 대해서 가능한 Bounding Box의 좌표와 그 안에 물체가 들어있을 확률을 계산. anchor들 자체가 Bounding Box의 후보군이 되는 것.
c. cls layer는 해당 박스 안에 물체가 존재하는지의 여부를 분류하고, reg layer는 물체를 감싸는 Bounding Box의 정확한 위치를 예측. 두 layer들의 학습을 통해 물체가 들어 있는 정확한 Bounding Box, 즉 RoI들을 추출할 수 있게 됨.
3. 각 Region에 대한 특징 맵이 모두 다 동일하게 고정된 사이즈로 생성된 각 RoI 내의 물체들에 대해 분류를 시행할 수 있음.
4. Mask R-CNN
Faster R-CNN을 확장하여 instance segmentation을 한다. (instance segmentation: 이미지 내에 존재하는 모든 객체를 탐지하는 동시에 각각의 instance를 정확하게 픽셀 단위로 분류한다. 객체를 탐지하는 object detection task + 각각의 픽셀의 카테고리를 분류하는 semantic segmentation task가 결합된 모습.)
Faster R-CNN에 Mask Branch, FPN, RoI Align을 추가함
- classification, localization(bounding box regression) branch에 Mask Branch가 추가
- RPN 전에 FPN(feature pyramid network) 추가
- Image Segmentation의 masking을 위해 RoI pooling을 대신 RoI align 도입


- stage 1 : RPN (Region Proposal Network)
- stage 2 : Predict the class, box offset and a binary mask for each ROI
1. 800~1024 사이즈로 이미지를 resize해준다. (using bilinear interpolation)
2. Backbone network의 인풋으로 들어가기 위해 1024 x 1024의 인풋사이즈로 맞춰준다. (using padding)
3. ResNet-101을 통해 각 layer(stage)에서 feature map (C1, C2, C3, C4, C5)를 생성한다.
4. FPN을 통해 이전에 생성된 feature map에서 P2, P3, P4, P5, P6 feature map을 생성한다.
5. 최종 생성된 feature map에 각각 RPN을 적용하여 classification, bbox regression output값을 도출한다.
6. output으로 얻은 bbox regression값을 원래 이미지로 projection시켜서 anchor box를 생성한다.
7. Non-max-suppression을 통해 생성된 anchor box 중 score가 가장 높은 anchor box를 제외하고 모두 삭제한다.
8. 각각 크기가 서로다른 anchor box들을 RoI align을 통해 size를 맞춰준다.
9. Fast R-CNN에서의 classification, bbox regression branch와 더불어 mask branch에 anchor box값을 통과시킨다.
Network Architecture
1. Backbone: Backbone으로 ResNet 모델과 FPN을 사용. 이미지의 feature를 추출하기 위해 사용한다.
a. FPN: 마지막 layer의 feature map에서 점점 이전의 중간 feature map들을 더하면서 이전 정보까지 유지할 수 있도록 하여, 더이상 여러 scale값으로 anchor를 생성할 필요가 없게 됐고 모두 동일한 scale의 anchor를 생성한다. 따라서 작은 feature map에서는 큰 anchor를 생성하여 큰 object를, 큰 feature map에서는 다소 작은 anchor를 생성하여 작은 object를 detect할 수 있도록 설계하였다.
i. 이전의 Faster R-CNN에서는 backbone의 결과로 나온 1개의 feature map에서 roi를 생성하고classification 및 bbox regression을 진행했다. 해당 feature map은 backbone 모델에서 최종 layer에서의 output인데 이렇게 layer를 통과할수록 아주 중요한 feature만 남게되고 중간중간의 feature들은 모두 잃어버리고 만다. 그리고 최종 layer에서 다양한 크기의 object를 검출해야하므로 여러 scale값으로 anchor를 생성하므로 비효율적이다.
2. RoI Align : bilinear interpolation을 이용해서 extract한 feature를 input에 적절하게 위치정보를 담는 RoI align을 이용한다.
a. 기존의 Faster R-CNN에서 RoI pooling은 object detection을 위한 모델이였기에, 정확한 위치 정보를 담는 것이 중요하지 않고, 각 RoI에서 small feature map를 extract하는 연산을 하였다. RoI가 소수점 좌표를 가지면 좌표를 반올림하는 식으로 이동시킨후 pooling을 했는데, 이러면 pixel 단위로 예측하는 mask에 대해서 input image의 위치정보가 왜곡되기 때문에 segmentation에서는 문제가 된다.
b. bilinear interpolation 연산을 사용하여 각 RoI bin의 샘플링된 4개의 위치에서 input feature의 정확한 value를 계산.




3. Head: bounding box recognition과 Mask prediction을 위해 사용된다. Faster R-CNN의 Head(Classification and Regression)에 Mask branch를 추가!
a. Mask Branch:
i. Mask란 input object의 spatial layout의 encode 결과. mask는 convolutions 연산에 의해 공간적 정보 손실을 최소화. (class, box 정보들은 FC(Fully Connected) layers에 의해 고정된 vector로 변환되기 때문에 공간적 정보 손실 발생)
ii. per-pixel sigmoid + binary loss를 사용함으로써 classification과 segmentation를 decoupling 함으로써 더 좋은 instance segmentation 결과를 얻게 됨.
iii. 각 RoI마다 K개의 Mask를 예측함 (K : classification branch에서 예측된 class들)
iv. score 점수가 높은 상위 100개 box에서 적용됨
728x90'AI > Object Detection & Pose Estimation' 카테고리의 다른 글
Pose Estimation 관련 참고 블로그 (0) 2021.11.21 Feature Pyramid Network for Object Detection (0) 2021.09.09 Cascaded Pyramid Network for Multi-person pose estimation (0) 2021.09.09 Detectron2 이란? Pytorch 기반의 Object Detection, Segmentation 라이브러리! (0) 2021.09.09 Cifar10 Dataset 정리 (0) 2021.09.01