-
Feature Pyramid Network for Object DetectionAI/Object Detection & Pose Estimation 2021. 9. 9. 20:53728x90
Object Detection 분야에서 Scale-Invariant 문제 매우 중요.
- Variants 는 Scale, Shift, Rotation 등... Shift Variant는 Pooling을 통해 해결. Scale Variant는 CNN을 통해 어느 정도 해결 가능하나 Standard Convolution Filter에선 해결 불가.
예전엔 다양한 크기의 물체를 탐지하기 위해 이미지 자체의 크기를 resize하며 물체 detect했지만 이는 메모리 및 시간 측면에서 비효율적. 이를 해결하기 위한 방법이 FPN.
기존의 방식
(a) Featurized Image Pyramid
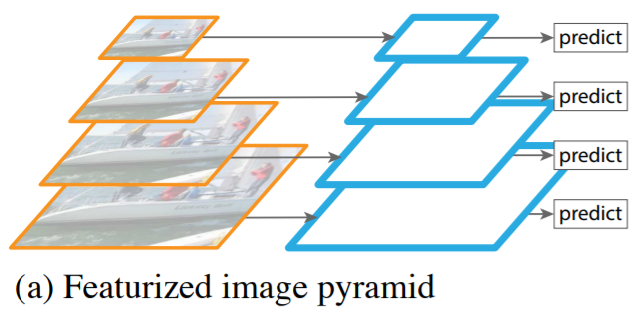
- 각 레벨에서 독립적으로 특징을 추출하여 객체를 탐지
(b) Single Feature Map

- Convolution Layer가 Scale 변화에 Robust하기 때문에, 이를 통해 특징 압축.
- 하지만 Multi Scale을 사용하지 않고 한 번에 특징을 압축하여 마지막에 압축된 특징만을 사용하기 때문에 성능 저하.
(c) Pyramidal Feature Hierarchy
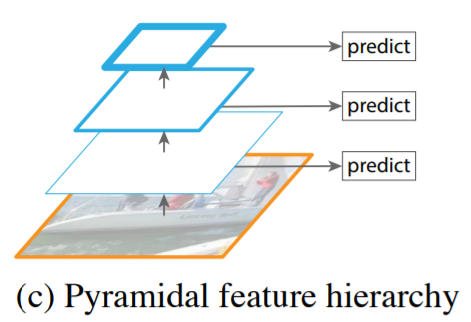
- 서로 다른 Scale의 Feature Map을 사용하여 Multi Scale 특징을 추출
- 각 레벨에서 독립적으로 특징을 추출하여 객체를 추출하는데 이는 이미 계산되어 있는 레벨의 특징을 재사용하지 않음
Feature Pyramid Network
- Top-Down 방식으로 특징 추출, 각 추출된 결과들인 low-resolution (낮은 해상도) 및 high-resolution(높은 해상도) 들을 묶는 방식
- 각 레벨에서 독립적으로 특징을 추출하여 객체를 탐지하게 되는데, 상위 레벨의 이미 계산된 특징을 재사용하므로 Multi Scale 특징들을 효율적으로 사용할 수 있음
- CNN 자체가 레이어를 거치면서 피라미드 구조를 만들고 forward를 거치면서 더 많은 의미(Semantic)를 가짐. 각 레이어마다 예측 과정을 넣어서 Scale Variant에 더 강한 모델이 됨.
- Skip Connection, Top-Down, CNN forward에서 생성되는 피라미드 구조를 친 형태. forward에서 추출된 의미 정보들을 Top-Down 과정에서 Upsampling하여 해상도를 올리고, forward에서 손실된 지역적인 정보들을 Skip Connection으로 보충하여 Scale Variant에 Robust하게 되는 것
: Semantic Segmentation을 할 때 Sliding Window나 FC layer를 거치는 방법보다는 FC + Downsampling (Pooling, Strided Convolution을 통해) + Upsampling하는 방법을 주로 사용함
- Upsampling의 종류 [CS231N Lecture 11]
1) Unpooling 2) Max Unpooling 3) Transpose Convolution (Learnable Upsampling)

- FPN은 RPN(Region Proposal Network)과 Fast R-CNN을 기반으로 함
- Input으로는 임의의 크기의 단일 스케일 영상, Output으로는 전체적으로 Convolutional 방식으로 비례된 크기의 Feature map을 다중 레벨로 출력
- Backbone Convolutional Architecture와 해당 프로세스는 독립적이며, ResNet을 사용해 결과를 보여줌

- 크게 Bottom-up과 Top-down 프로세스로 설명할 수 있음. Top-down없이 Bottom-up만으로 네트워크를 만들면 성능이 안 좋을 뿐만 아니라 레이어 별로 semantic 수준이 다르며, 레이어가 깊어질 수록 현상이 심화됨
Bottom-up Pathway
- Backbone ConvNet의 FeddFoward 계산이 진행됨
- 위로 올라가는 forward단계에서는 매 레이어마다의 의미 정보를 응축하는 역할을 함
: 깊은 모델의 경우 가로, 세로 크기가 같은 레이어들이 여러 개 있을 수 있는데 이 경우에 같은 레이어들은 하나의 단계로 취급해서 각 단계의 맨 마지막 레이어를 skip-connection 에 사용하게 됨
- 각 단계의 마지막 레이어의 출력을 feature map의 Reference Set으로 선택. 각 단계의 가장 깊은 레이어에는 가장 영향력 있는 특징이 있어야 함.
Top-down Pathway & Lateral Connections
- 많은 의미 정보들을 가지고 있는 Feature Map을 2배로 Upsampling하여 더 높은 해상도의 이미지를 만드는 역할을 수행. 여기서 Skip Connection을 통해 같은 사이즈의 Bottom-up 레이어와 합쳐서 손실된 지역 정보들을 보충함.
- 업샘플링된 맵은 Element-wise addition 에 의해 상향식 맵과 병합되는 과정을 거침. 이 때 채널 수를 줄이기 위해 1 x 1 컨볼루션 레이어를 거치게 됨.
- 각 합쳐진 맵에 3 x 3 컨볼루션을 추가하여 업샘플링의 앨리어싱(Aliasing) 효과를 줄이는 최종 특징 맵을 생성함.
728x90'AI > Object Detection & Pose Estimation' 카테고리의 다른 글
3D human pose estimation in video with temporal convolutions and semi-supervised training 논문 리뷰 (2) 2023.01.12 Pose Estimation 관련 참고 블로그 (0) 2021.11.21 Mask R-CNN 흐름 정리 (R-CNN, Fast R-CNN, Faster R-CNN) (0) 2021.09.09 Cascaded Pyramid Network for Multi-person pose estimation (0) 2021.09.09 Detectron2 이란? Pytorch 기반의 Object Detection, Segmentation 라이브러리! (0) 2021.09.09