-
3D human pose estimation in video with temporal convolutions and semi-supervised training 논문 리뷰AI/Object Detection & Pose Estimation 2023. 1. 12. 19:13728x90
3D human pose estimation in video with temporal convolutions and semi-supervised training 논문 리뷰
인턴할 때 읽은 논문인데 이제야 올리네요... ^^

Abstract
- fully convolutional model을 통해 비디오에서의 3D pose를 추정
- label이 없는 비디오 데이터를 활용하기 위한 back projection 방법 소개(semi supervised training)
- unlabel 비디오에 대해 예측된 2D keypoint 부터 시작하여 3D pose를 예측하고 마지막으로 입력된 2D keypoint를 back project한다.
1. Introduction
- Dilated convolution을 이용한 temporal convolution 모델로 SOTA를 달성했으며 CNN이라서 RNN보다 빠르고 가볍다.
- 3D pose estimation분야에 있어서 유용한 semi supervised 학습방법을 발견했다.
- (보통의, 평범한, 일반적인) 2D keypoint detector를 이용해서 라벨이 부착되지 않은 비디오의 2D keypoint 를 예측하고 이를 다시 2D space에 매핑한다.
- 3D annotation 없이 2D annotation과 카메라 내부 파라미터만 알면 된다.우리가 실제로 보는 세상은 3D이지만 카메라로 찍으면 2D. 영상을 찍을 당시의 카메라의 위치 및 방향에 의해 이미지 상에서의 3차원의 점들의 위치 결정. 3차원 점들이 영상에 투영된 위치를 구하거나 역으로 영상좌표로부터 3차원 공간좌표를 복원할 때에는 이러한 내부 요인을 제거해야만 정확한 계산이 가능해짐. 그리고 이러한 내부 요인의 파라미터 값을 구하는 과정을 카메라 캘리브레이션.
- 카메라 내부 파라미터는 카메라의 초점 거리, aspect ratio, 중심점 등 카메라 자체의 내부적인 파라미터
- 카메라 캘리브레이션 + 카메라 내부 파라미터와 외부 파라미터 [https://darkpgmr.tistory.com/32]
- 필요에 따라 외부 파라미터를 쓸 수도 있다.
- 카메라 외부 파라미터는 카메라의 설치 높이, 방향(팬, 틸트) 등 카메라와 외부 공간과의 기하학적 관계에 관련된 파라미터
- 2D keypoint에서 3D pose 예측을 수행하는 fully conovlutional architecture
- 추가 내용
- 문제를 2D keypoint 검출로 공식화한 후 3D pose 추정을 수행하는 최첨단 방법을 기반으로 설계했다.
- Convolutaional model이 recurrent network에서는 불가능한 여러 프레임의 병렬처리를 가능하게 하고 temporal information modeling을 잘 수행할 수 있기 때문에 Convolutional model 사용,
2. Related Work
Two-step pose estimation
딥러닝을 통한 3D pose estimation에는 크게 3가지 접근법이 있는데
-
- 이미지 ⇒ 3D pose의 end-to-end 방식
- 이미지에서 3D pose를 추출하는 것이기 때문에 feature extraction이 필요하고 이를 위한 ResNet이 동반. 주로 heatmap을 통한 방법이 많음.
- 이미지 + 2D pose ⇒ 3D pose의 lifting 방식
- 2D pose ⇒ 3D pose의 Lifting 방식
2,3 번이 two step pose estimation이고 이 논문은 3번의 two step pose estimation을 사용한다. 최근 연구에서 2D pose 예측을 할 때에는 Cascaded pyramid network이나 mask R-CNN 모델을 사용한다.
- Mask R-CNN
- Mask R-CNN (Object Detection)
Video pose estimation
최근에는 비디오의 시간적 정보를 활용하여 보다 강력한 예측을 하고 noise에 덜 민감하게 대처하려고 한다.
이 논문은 이미지 없이 오직 2d pose만을 이용해 3d pose를 구한다. 2D pose의 변화를 통해서 3D pose를 구하므로 video pose estimation의 범주에 속한다.
Our Work
- heatmap을 사용하지 않고 keypoint 좌표를 사용하여 pose를 설명한다. 따라서 heatmap의 2D convolution을 사용하는 대신 coordinate time series의 1D convolution을 사용할 수 있다.
- time dimension 1D convolution을 수행하여 temporal information을 활용하고 reconstruction error 를 낮추는 몇가지 최적화를 제안한다.
- 이미지로부터 2D keypoints를 검출해내는 것은 mask R-CNN + cascaded pyramid network(deterministic mapping)를 통해!
- Cascaded Pyramid Network for Multi-person pose estimation

3. Temporal dilated convolutional model(모델 구조)

- dilated convolution + 1d convolution + time series datadilated convolution: convolutional layer에 dilation rate을 도입하여 커널 사이의 간격을 정한다. 위 그림과 같이 3X3커널이지만 5X5커널과 동일한 시야를 가지게 된다. 즉, 적은 계산비용으로 넓은 시야를 제공받을 수 있다.Temporal Convolutional Network (TCN)
- dilation factor = 2일 때의 그림
- dilated convolution으로 receptive field(참고되는 영역)를 늘려 RNN없이 효율적으로 높은 성능을 얻어낸다.

모델 설명
- model: 2D pose의 sequence를 input으로 가지고 temporal convolution을 통해 input을 transform시키는 residual connection을 가지는 fully convolutional architecture
- input layer: 각(x,y)좌표.j는 예측하고자 하는 관절의 개수
- 즉 x축은 frame이므로 시간축, y는 예측하고자 하는 관절에 2d이므로 2를 곱한다.
- x = frame =x, y = JX2
- input을 kernel size W과 C output channel을 가지는 temporal convolution에 적용한다.
- 그 다음에는 B개의 ResNet 스타일 block이 나온다.
- 각 block에서 처음에는 W kernel 사이즈, dilation factor D를 통해 1D convolution을 수행한다. dilation factor D는 $D=W^B$
- 그 다음에 커널 크기 1로 변환을 수행한다.
- 그다음 batch normalization, Relu, dropout이 수행된다.
- 마지막 layer는 input sequence의 모든 프레임에 대해서 3D pose 예측을 출력한다. 이 때 과거 및 미래 데이터를 통한 시간 정보가 활용되었다.
- real time scenarios를 평가하기 위해 causal convolution으로도 실험해봄
- padding: 0
- 예시243프레임, B=4, W(kernel size)는 3, C(output channel)는 1024, dropout rate은 0.25 J는 17. 초록색이 convolution layer. dilation rate은 1.
4. Semi-supervised approach (모델 학습 방법론)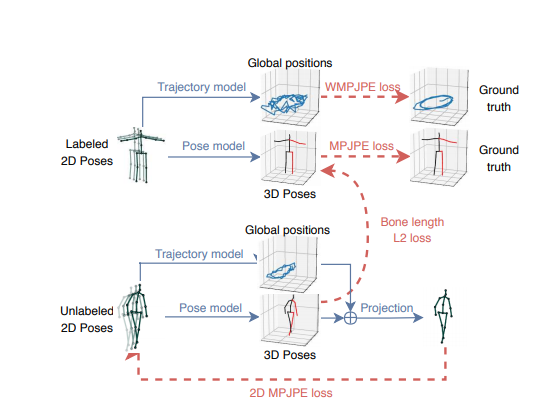
이 학습방법은 unlabeled data에 대한 auto-encoding problem을 푼다. encoder 는 2D joint 좌표로부터 3D pose 추정을 수행하는 pose estimator역할을 한다. decoder는 3D pose를 2D joint 좌표로 project 시킨다.
WMPJPE = weight MPJPE 사람의 3D trajectory를 regress하고 label이 지정되지 않은 prediction의 mean bone length와 label이 지정된 prediction값을 일치시키는 soft constraint인 bone length L2 loss를 추가한다.
위 그림은 supervised component와 정규화 역할을 하는 unsupervised component를 결합한 모습으로 이 논문의 모델 학습 방법을 나타낸다.
- labeled data가 batch의 전반부를 차지하고 unlabeled data가 후반부를 차지한다.
- label data의 경우 GT(ground truth) 3D pose를 target으로 사용하여 supervised loss train을 한다.
- unlabeled data는 예측된 3D pose가 2D로 다시 투영된 다음 input과의 일관성을 확인하는 autoencoder loss를 구현하는 데 사용된다.
- 3D GT label이 있는 비디오의 경우 pose model에서 root-relative 좌표를 예측한다. 그리고 root 좌표는 trajectory model에서 따로 예측한다. 나중에 이 둘을 합치면 실제 좌표를 구하는 것이다.
- semi supervised 방법론에서는 pose model과 trajectory model에서 도출한 3차원 좌표값을 카메라 내/외부 파라미터를 통해 다시 2차원으로 projection하고 이는 입력된 2d label과의 차이가 없어야한다. (그래서 2D MPJPE loss함수사용해서 차이 줄이는 방향)
- perspective projection(3차원 좌표계를 2차원 좌표계로 변환하는 것) 때문에 2D pose는 trajectory(사람 root joint의 global position)과 3D pose(root joint와 관련된 모든 관절 위치)에 따라 달라진다.
- global 위치가 없으면 피사체는 항상 고정된 scale로 screen center 에 다시 project된다. 따라서 2D로의 back projection이 올바르게 수행될 수 있도록 사람의 3D trajectory도 회귀분석한다. (그래서 2개의 model 필요) 2D로 projection하기전에 포즈에 global poistion이 추가된다.
- 두 network는 같은 architecture같지만 어떤 weight라도 공유하지 않는다.
- 피사체가 카메라에서 멀리 떨어져있을 수록 정확한 trajectory를 regress하는 게 점점 어려워지기 때문에 WMPJPE loss 함수를 최적화하는 방향으로 학습한다.Yz = ground truth depth in carmera space
- 입력에 대해 3D pose 예측을 하고자 한다. 이를 위해서는 unlabel batch에 있는 subject의 평균 bone length를 대략 match시키는 soft constraint를 추가하는 게 효과적이다. (Bone length L2 loss)
- 이 방법은 카메라의 파라미터만 요구하며 사용카메라에서 사용할 수 있다. 위에 설명된 network를 통해 2D pose를 3D 에 매핑하고, 3D pose를 2D에 투영하기 위해 단순 project layer를 사용한다.
5. Experimental Setup
5.1 Datasets and Evaluation
- motion capture dataset 두개를 평가: Human 3.6M, HumanEva-I
- Human 3.6M: 11개의 subject 의 3.6 million video frame . 7개의 subject에는 3D pose가 주석으로 첨부됨. 각 subject는 50Hz에서 동기화된 카메라 4개를 사용하여 녹화된 15가지 동작을 수행.
- HumanEva-I: 60Hz 3개의 카메라로부터 녹화된 3개 subject dataset
- 3개의 evaluation protocol
- mean per-joint position error: 예측 joint position과 ground truth joint position의 유클리드 거리
- protocol 2 reports the error after alignment with the ground truth in translation, rotation, scale에서 ground truth
- 예측된 자세를 scale에서만 ground truth와 정렬한다. 이를 가지고 평가한다.
5.2 Implementation details for 2D pose estimation
⇒ 2D keypoint location 예측을 하기위한 implementation의 디테일 설명
이전 연구들은 ground truth bounding box에서 subject를 추출한 다음에 stacked hourglass detector를 적용하여 ground truth box 내의 2D keypoint location을 예측했다.
하지만 이 연구는 특정 2D keypoint detector에 의존하지 않는다. 또한, stacked hourglass detector 외에도 Mask R-CNN과 CPN을 사용한다.
- CPN을 위해 Mask R-CNN을 사용한다. CPN과 Mask R-CNN 모두 COCO dataset을 통해 사전 교육된 모델로 시작하고 detector를 fine tuning한다. 왜 fine tuning 하냐면, COCO에 있는 keypoint랑 Human 3.6는 다르기 때문이다.
- 또한 human 3.6M의 3D joint를 추정하기 위해 사전 훈련된 2D COCO keypoint에 3D pose estimator를 직접 적용하는 실험을 한다.
- Mask R-CNN back bone에 "streched 1x" schedule로 훈련된 ResNet -101 backbone을 채택한다.
- Human3.6M에 기반한 model을 fine tuning 할 때 keypoint network의 last layer를 초기화해야한다. 더불어 새로운 keypoint 집합을 학습하기 위해 heatmap을 regress하는 deconv layer도 다시 초기화한다.
- 4개의 GPU를 가지고 훈련한다. 추론시 heatmap에 softmax를 적용하여 resulting 2D distribution의 기대값을 추출한다.
- CPN에 대해서는 ResNet-50 backnone을 사용한다. fine tune을 위해서 GlobalNet과 Refine Net의 마지막 layer를 재초기화한다.
- ground truth bounding box를 가지고 훈련하고 fine tuning된 mask R-CNN model에 의해 예측된 bounding box를 사용하여 test한다.
5.3 Implementation details for 3D pose estimation
- 카메라 변환에 따라 ground truth pose를 rotating, translating하여 camera space에 있는 3D pose를 훈련하고 평가한다. (global trajectory를 사용하지 않는다.)
- optimizer는 Amsgrad이고 80 epoch으로 train한다.
- batch normalization momentum 사용, 마지막으로 train time, test time에 horizontal flip argumentation 수행한다.
6. Results
자세한 건 논문 참고
6.1 Temporal dilated convolutional model
- 이 모델은 직전 SOTA를 능가한다.
6.2 Semi-supervised approach
- semi supervised 를 사용한게 오류를 줄일 수 있다.
7. Conclusion
- 비디오 속 3D human pose 추정을 위한 간단한 fully convolutional model을 소개했다. ⇒ 이 fully convolutional architecture는 Human 3.6M dataset에 대해 그전 최고 성능 결과에 대해서 평균 6mm의 조인트 오류를 개선했다.
- 이 architecture는 2d keypoint trajectories을 통한 dilated convolution와 함께 temporal information을 활용한다.
- 이 작업의 두 번째 기여는 back projection으로 이는 라벨 데이터가 부족할 때 성능 개선을 위한 semi supervised training method다. 이 방법은 label이 부착되지 않은 비디오와 작동하며 고유 카메라 파라미터만 요구하므로 motion capture가 어려운 상황에서 실용적이다. ⇒ 3D pose 추정 정확도를 약 10mm 향상시킬 수 있었다.
8. Github Repo
https://github.com/facebookresearch/VideoPose3D
GitHub - facebookresearch/VideoPose3D: Efficient 3D human pose estimation in video using 2D keypoint trajectories
Efficient 3D human pose estimation in video using 2D keypoint trajectories - GitHub - facebookresearch/VideoPose3D: Efficient 3D human pose estimation in video using 2D keypoint trajectories
github.com
- inference 해보시면 재밌습니다 ㅎㅎ
++) 정리 해놨던 거잖아 .. .?
ㅋㅋ
728x90'AI > Object Detection & Pose Estimation' 카테고리의 다른 글
Pose Estimation 관련 참고 블로그 (0) 2021.11.21 Feature Pyramid Network for Object Detection (0) 2021.09.09 Mask R-CNN 흐름 정리 (R-CNN, Fast R-CNN, Faster R-CNN) (0) 2021.09.09 Cascaded Pyramid Network for Multi-person pose estimation (0) 2021.09.09 Detectron2 이란? Pytorch 기반의 Object Detection, Segmentation 라이브러리! (0) 2021.09.09