-
[2023 Winter Multimodal Seminar] 0. Core research challenges in multimodal learningAI/Multimodal 2023. 1. 5. 14:56728x90
[2023 Winter Multimodal Seminar] 0. Core research challenges in multimodal learning
이번 방학에는 Multimodal에 대해서 함께 공부해보려고 한다 !
어디서부터 시작해야 될 지 모르겠던 찰나에,
CMU에서 공개된 Multimodal Machine Learning Lecture가 있어서 이를 참고하여 스터디를 구성해보았다.
유희왕의 융합카드. 뭐든지 합쳐버리겠다는 마인드로...
목차
0. Core research challenges in multimodal learning
1. Representation
2. Alignment
3. Reasoning
4. Generation
5. Transference
6. Quantification
0. Core research challenges in multimodal learning

Multimodal의 Core Challenge는 위와 같이 크게 6가지로 나눠진다.
각 Challenge에는 여러 개의 Sub Challenges로 이뤄지는데, 밑에서 함께 살펴보도록 하겠다.
(세미나의 진행과 함께 아래 내용을 채우도록 하겠습니다... )
(1) Representation studies how to represent and summarize multimodal data to reflect the heterogeneity and interconnections between individual modality elements.
(2) Alignment aims to identify the connections and interactions across all elements.
(3) Reasoning aims to compose knowledge from multimodal evidence usually through multiple inferential steps for a task.
(4) Generation involves learning a generative process to produce raw modalities that reflect cross-modal interactions, structure, and coherence.
(5) Transference aims to transfer knowledge between modalities and their representations.
(6) Quantification involves empirical and theoretical studies to better understand heterogeneity, interconnections, and the multimodal learning process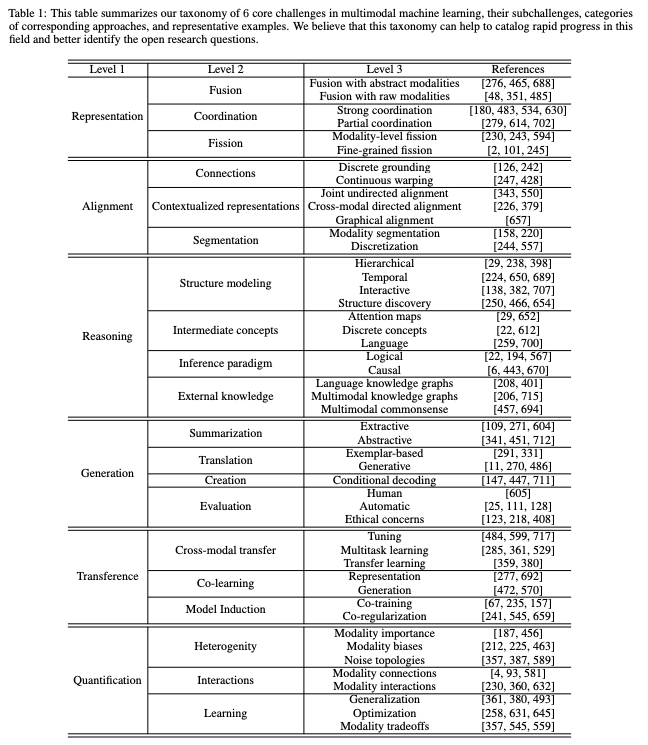
위의 Reference paper들을 다 볼 수 있으면 좋겠지만,,,, 일부만 발췌독 하는 걸루 ~
1. Representation
Representation은 각 모달리티 요소 간의 이질성과 상호 연결을 반영하기 위해 멀티모달 데이터를 표현하고 요약하는 방법을 연구한다.
이 Challenge는 지역적인 표현 또는 전체적인 특징을 사용한 표현을 학습하고 생성해내는 것으로 볼 수 있다.
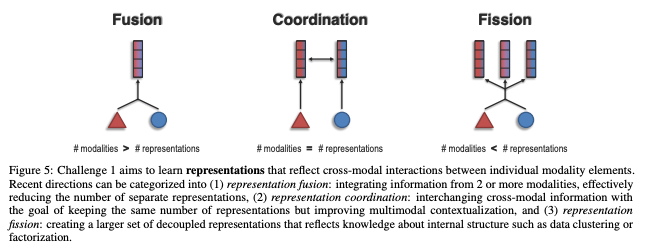
세부 챌린지로는 Fusion, Coordination, Fission으로 구성된다. 나오는 output representation에 따라 구분된다.
A. Fusion
Fusion은 두 개 이상의 모달리티에서 정보를 잘 융합하여 "개별 representation의 수를 효과적으로 줄이는 것"을 의미한다.

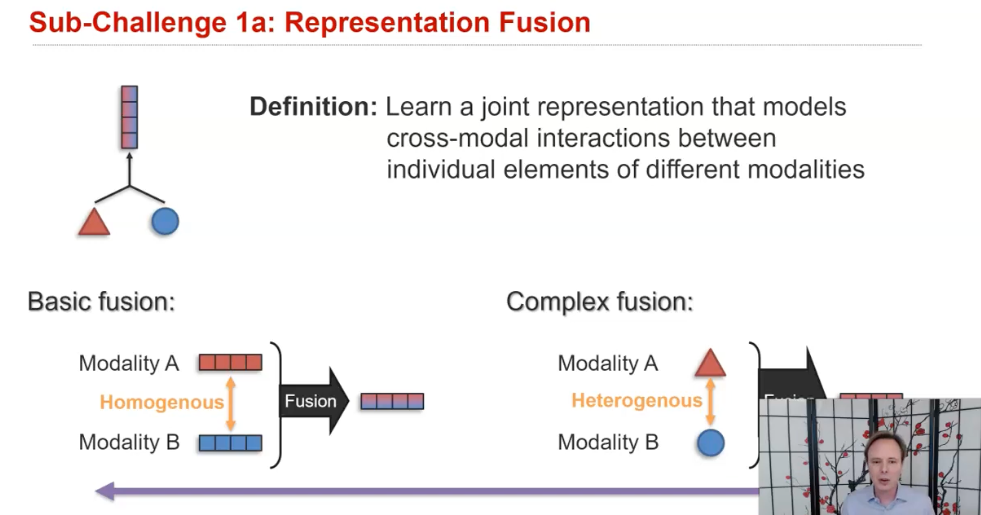
Fusion 내에서도 또 두 갈래로 나눠지는데 1) fusion with abstract modalities , 2) fusion with raw modalities이 바로 그것이다.
1) fusion with abstract modalities/basic fusion에서는
적절한 단일 모달 인코더는 각 요소(또는 전체 양식)의 전체적인 표현을 캡처하기 위해 먼저 적용된 후
비교적으로 비슷한 representation( relatively homogeneous representations)을 생성해내고,
fusion을 위한 여러 blocks을 사용하여 하나의 joint representation를 학습한다.
2) fusion with raw modalities/complex fusion에서는
매우 초기 단계에서 fusion을 수행하며, 아마도 heterogeneous한 raw modalities 그 자체를 포함할 수도 있다
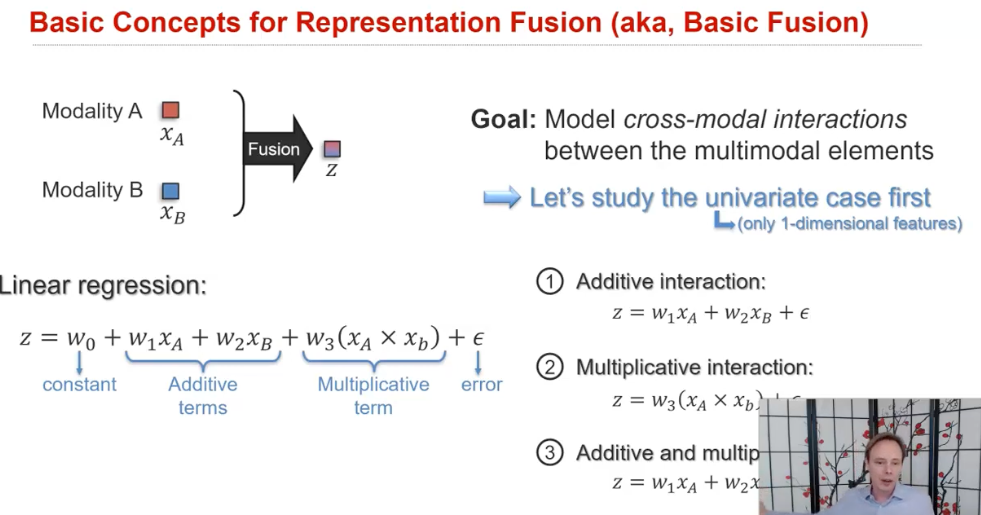
합치는 방식은 다음과 같이 나눌 수 있다.
(1) additive and multiplicative interactions
- 그냥 단순히 더하거나 곱해서 만드는 경우, ...
- 내가 발표할 논문도 여기에 해당된다 (Tensor Fusion Network for Multimodal Sentiment Analysis)
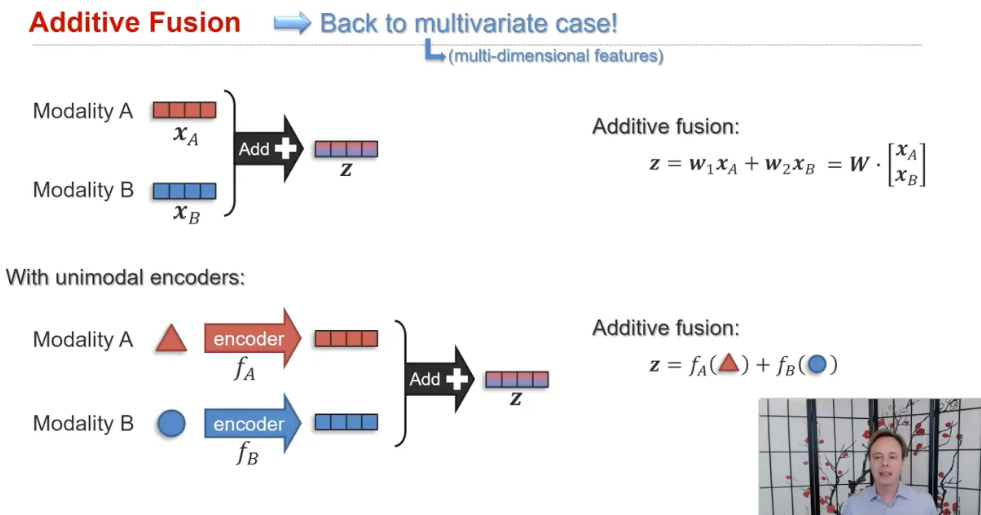

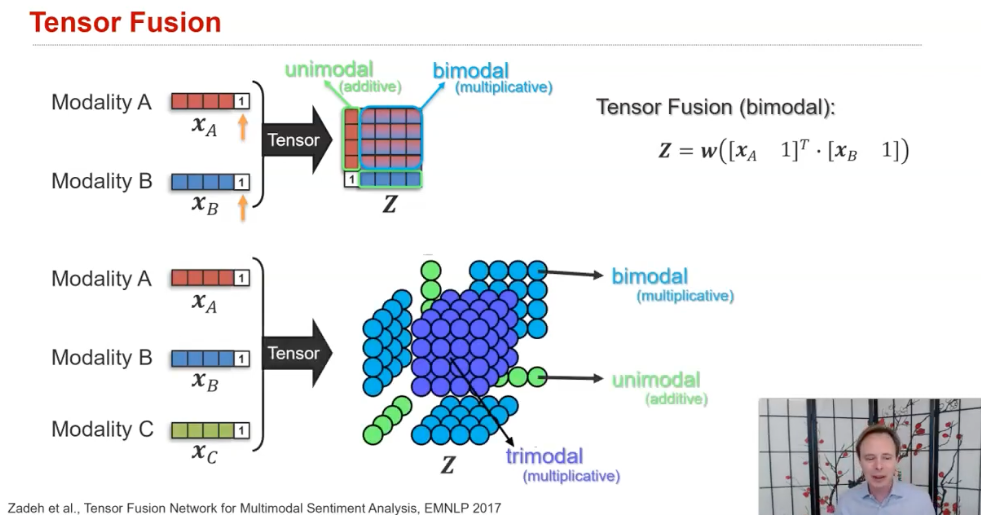
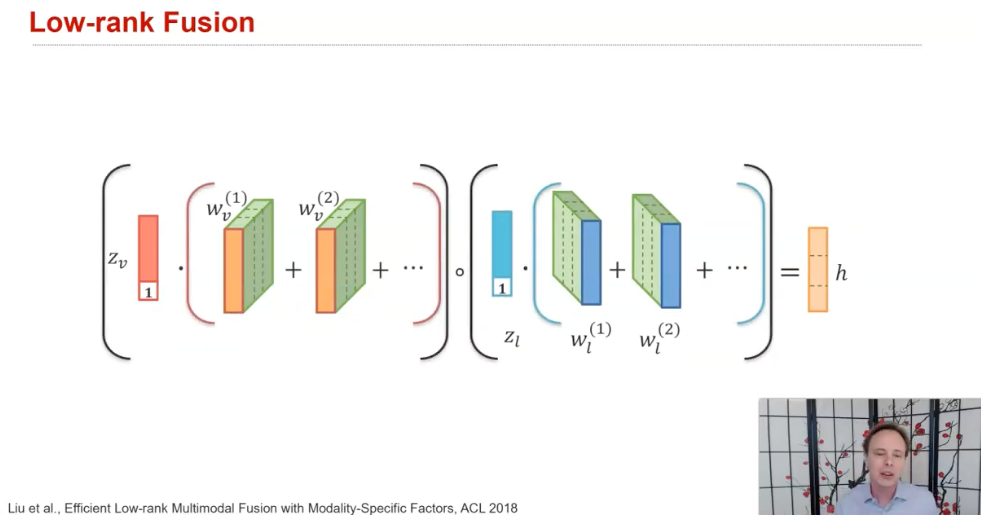

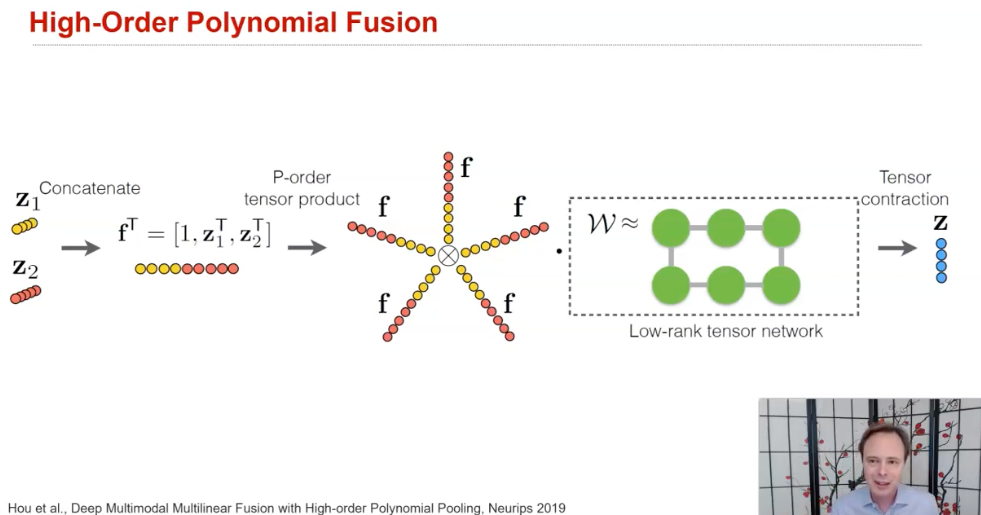
(2) Multimodal gated units/attention units
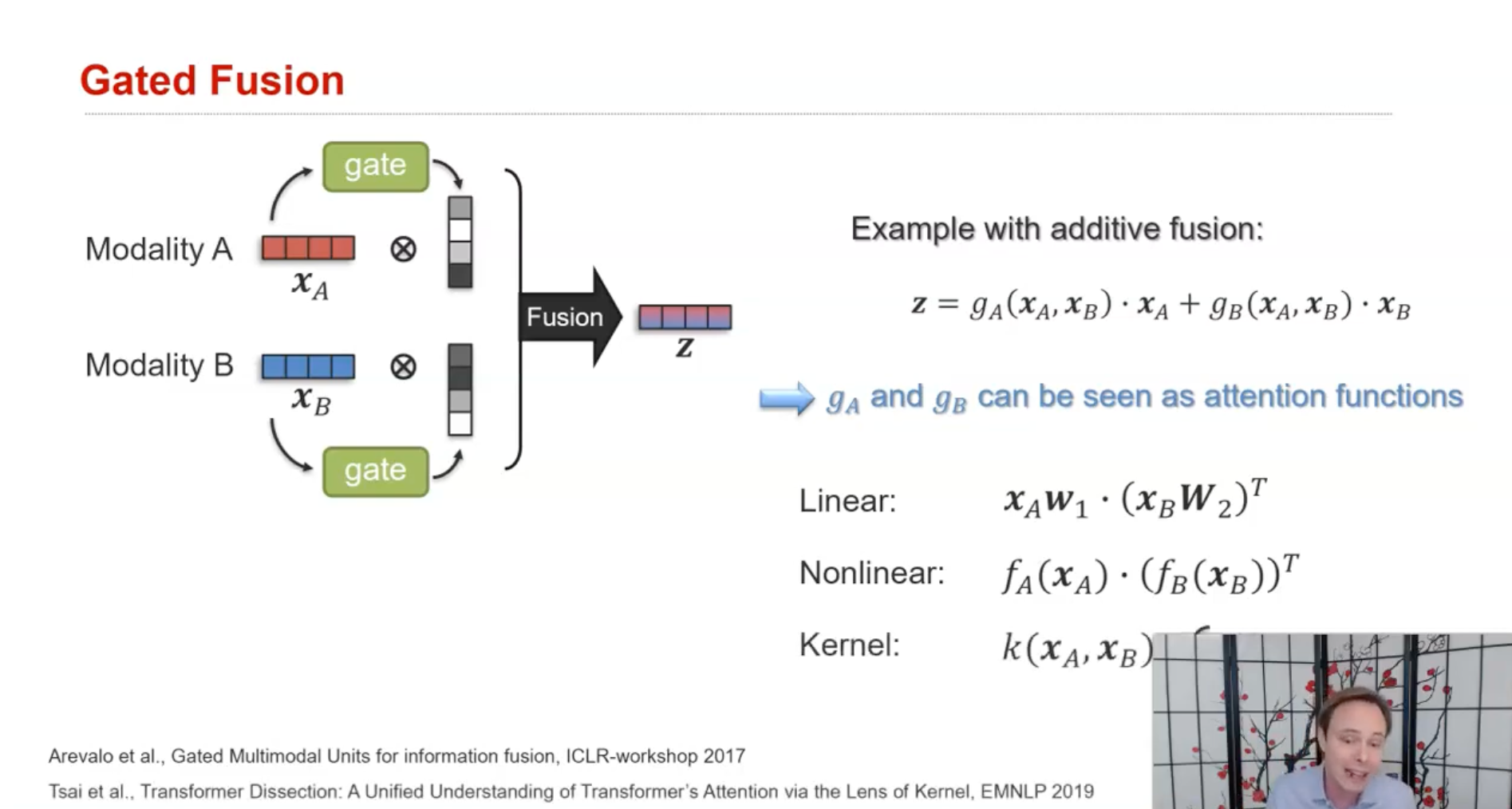
- FC layer, Kernel 기반 방식, attention 메카니즘 등을 적용해서, 각 input마다 동적으로 representation을 학습하는 경우
(3) Probabilistic approaches extend the previous categories of local fusion to probabilistic cases.
- Hidden Conditional Random Fields (HCRFs), deep Boltzmann machines 등 확률 기반으로
(4) Variational autoencoders provide a principled framework for integrating function approximators into latent-variable
modelsB. Coordination
Coordination은 "동일한 수의 representation을 유지하면서" multimodal contextualization를 개선하는 목표로 cross-modal information를 교환하는 것을 의미한다. 즉, 두 개의 모달리티 정보가 들어오면 두 정보를 잘 섞어서 두 개의 representation을 각각 조금씩 "조정"한다.
그 결과, output은 Fusion과 Fission과 달리 들어온 모달리티 정보의 개수와 동일하다.
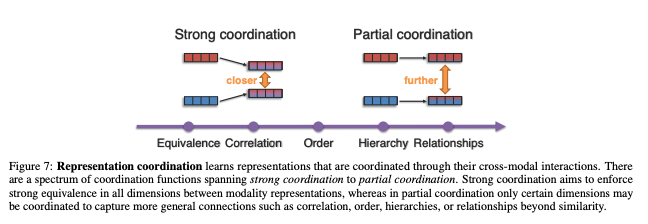

Coordination 내에서도 또 두 갈래로 나눠지는데 1) Strong coordination , 2) Early coordination이 바로 그것이다.
1) Strong coordination 은
의미론적으로 일치하는 모달리티을 조정된 공간에서 가깝게 만들어 모달리티 간의 강력한 동등성을 강화하는 것을 목표
예를 들자면, 단어 "Dog"와 개의 그림 간의 representation을 가깝게 만드는 것이다 ! (단어 "Car"와 개의 그림 간의 representation 아님)
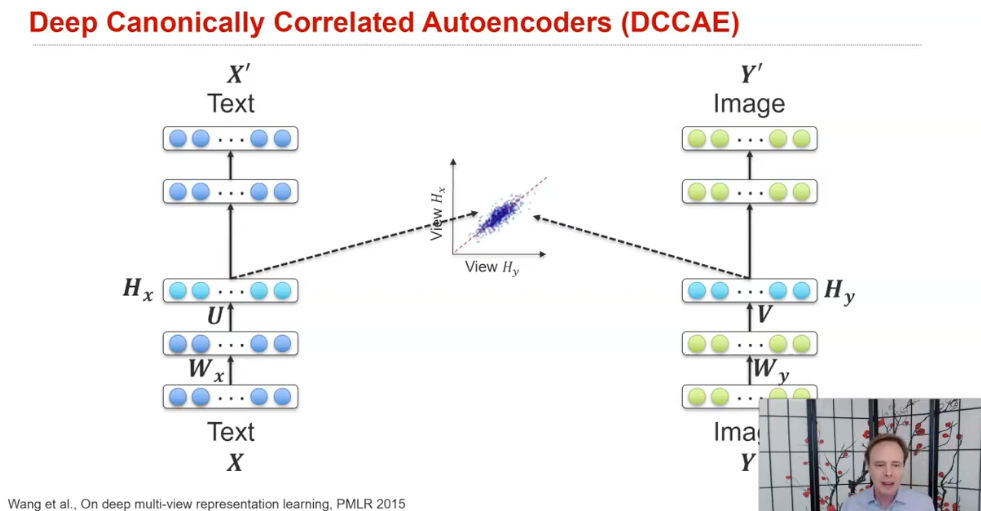
수행하는 방식은 다음과 같이 나눌 수 있다.
(1) Contrastive learning
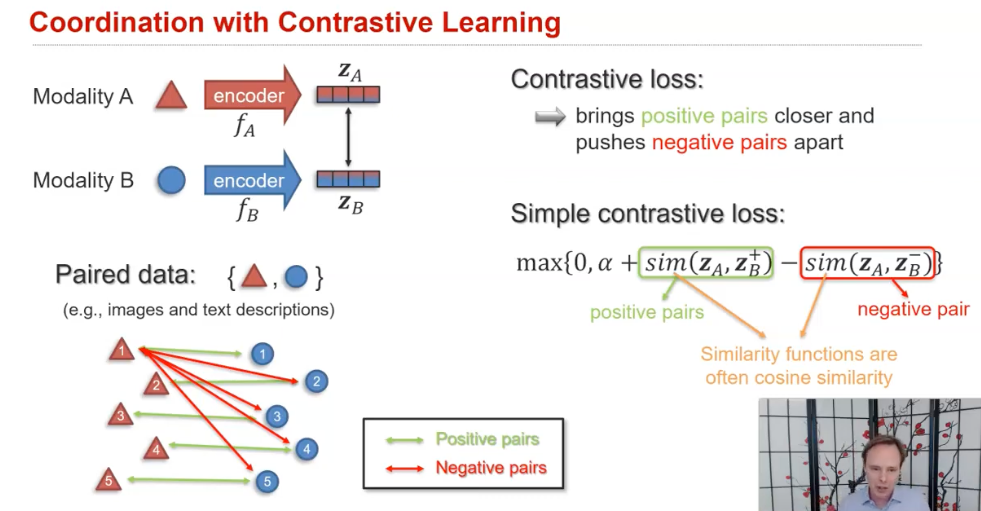


(2) Translation losses
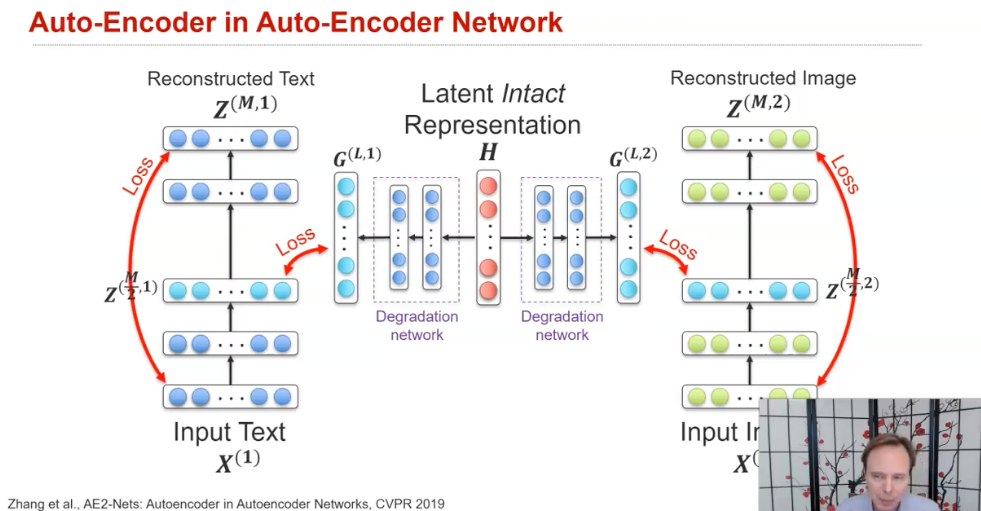
2) Early coordination은
동일성을 강력하게 캡처하려는 Strong Coordination과는 달리, 좀더 general한 모달리티 연결성(correlation, order, hierarchies, or relationships 등)을 만드는 데 초점을 둔다.
(1) Canonical correlation analysis (CCA)
(2) Ordered and hierarchical spaces
(3) Relationship coordination
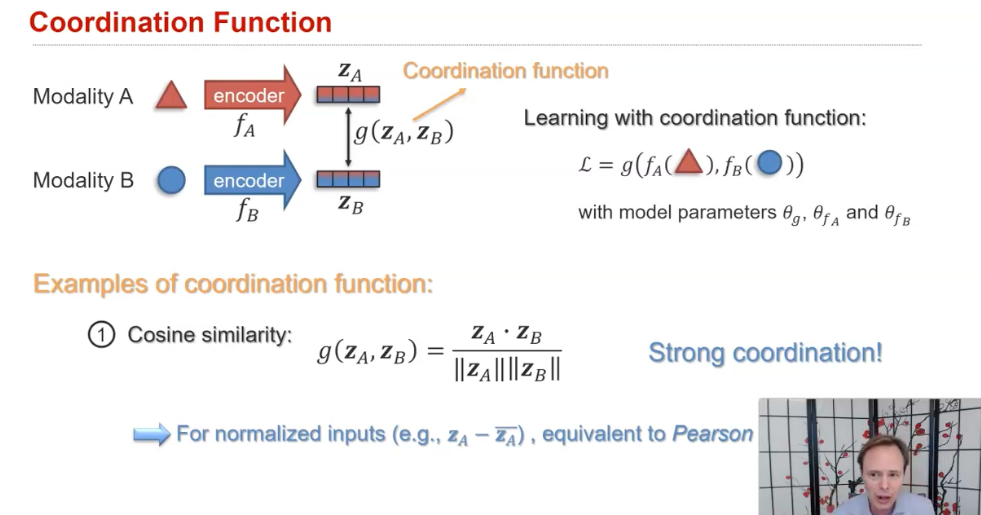
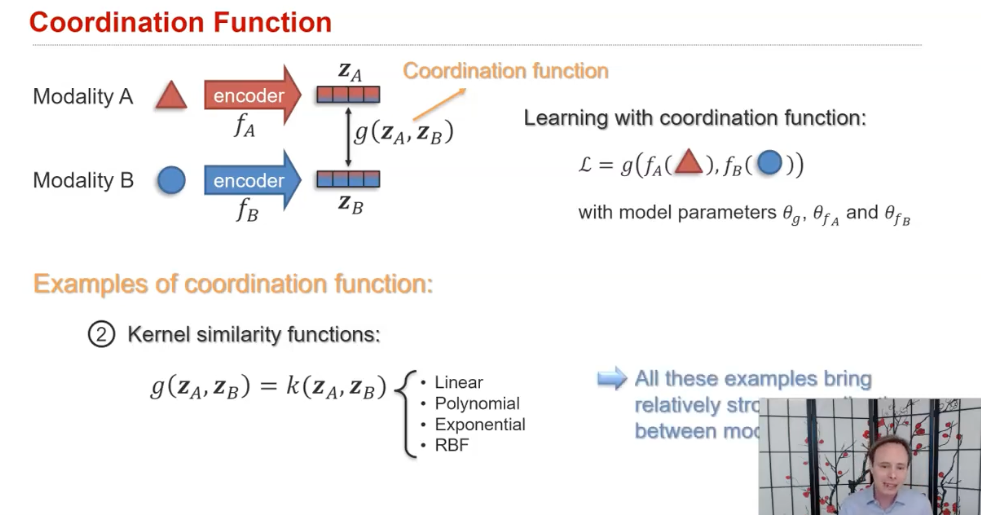

C. Fission
Fission은 input으로 들어온 N개의 모달리티 정보를 잘 결합하는 것까진 동일하나, 그것을 data clustering 이나 factorization을 통해 내부 구조에 대한 N+M개의 representation을 새롭게 생성해내는 것을 의미한다.
일반적으로 input set보다 더 큰 output set를 생성한다.
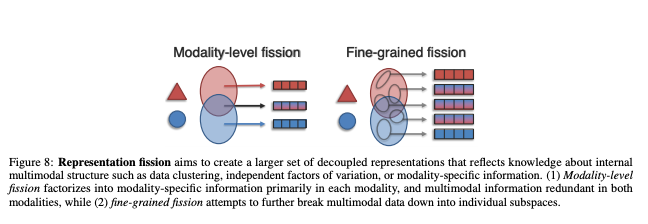
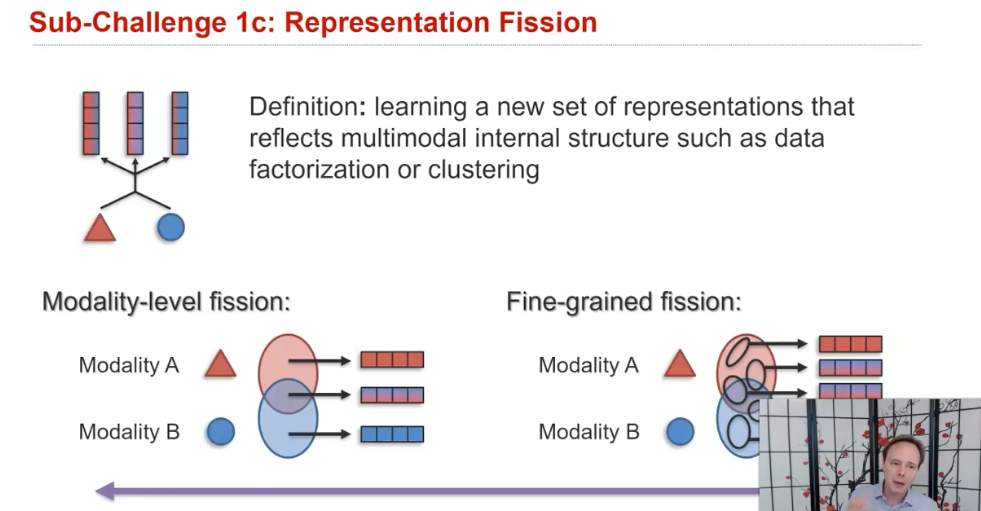
Fission 내에서도 또 두 갈래로 나눠지는데 1) Modality-level fission , 2) Fine-grained fission이 바로 그것이다.
1) Modality-level fission은
멀티모달 데이터를 주로 각 모달리티에 특정한 정보와 두 모달리티에 중복된 멀티모달 정보로 분해하는 것을 목표로 한다.
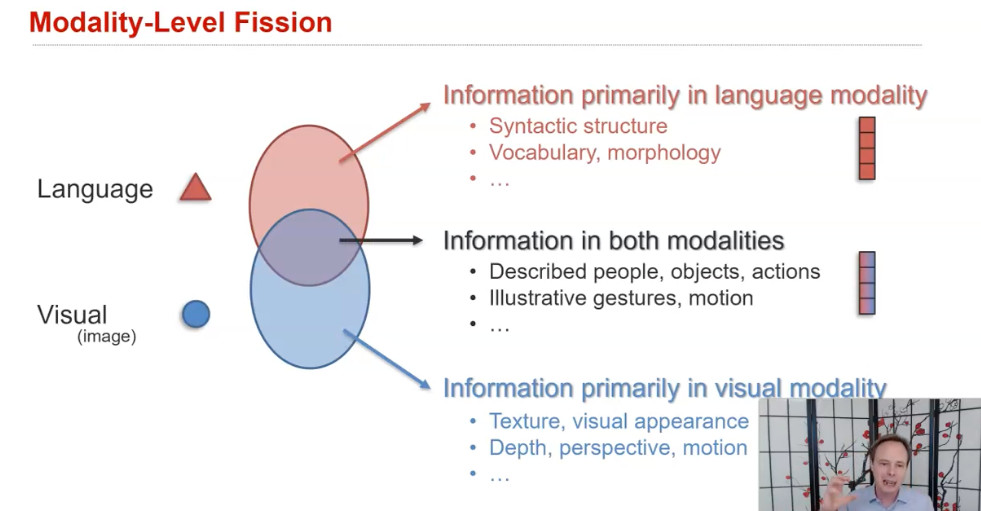
또한, modality-specific characteristics에 대한 도메인 지식(예: 통사적 구조와 형태학은 언어에 고유하다 / 질감, 시각적 외관, 깊이 및 움직임은 시각에 고유하다/ 설명된 objects와 actions은 둘 다에 존재하는 공유 중복 정보다)을 활용할 수 있는 더 해석 가능한 표현을 학습하는 데 유용하다
이 분야는 disentangled representation learning of modality-specific and multimodal latent variables 또는 post-hoc disentanglement of joint representations으로 해결될 수 있다.
2) Fine-grained fission은
각 모달리티 별로 분해하는 것을 넘어, multimodal 데이터를 그 보다 더 하위 공간으로 더 세분화하려고 시도한다.


각 모달리티가 제공하는 정보가 독립적이지 않기 때문에 고차원 멀티모달 데이터가 저차원 잠재 부분 공간으로 표현될 수 있다는 가설에서 영감을 받았다
이 분야는 Clustering과 Factorization을 주로 사용한다.
2. Alignment
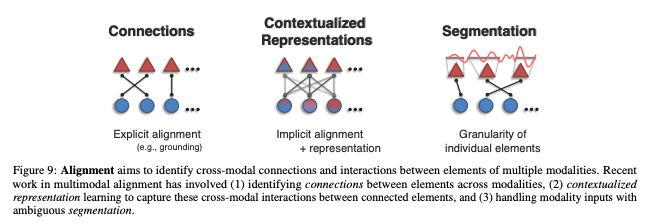
Alignment은 모든 요소의 연결과 상호작용을 식별하는 것을 목표로 한다.
세부 챌린지로는 Connections, Contextualized Representations, Segmentation으로 구성된다.
A. Connections

B. Contextualized Representations
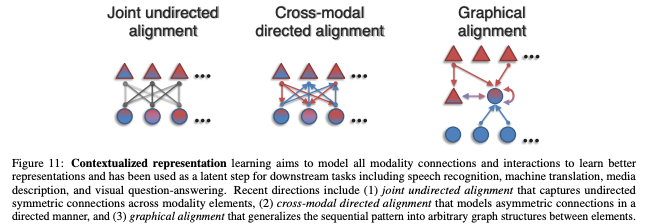
C. Segmentation
3. Reasoning
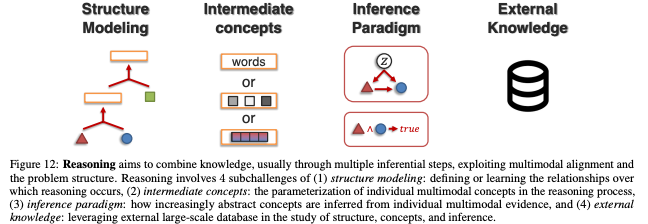
Reasoning은 일반적으로 task에 대한 여러 inferential steps를 통해 multimodal evidence로부터 knowledge을 구성하는 것을 목표로 한다
세부 챌린지로는 Structure Modeling, Intermediate Concepts, Inference Paradigms, External Knowledge으로 구성된다.
A. Structure Modeling

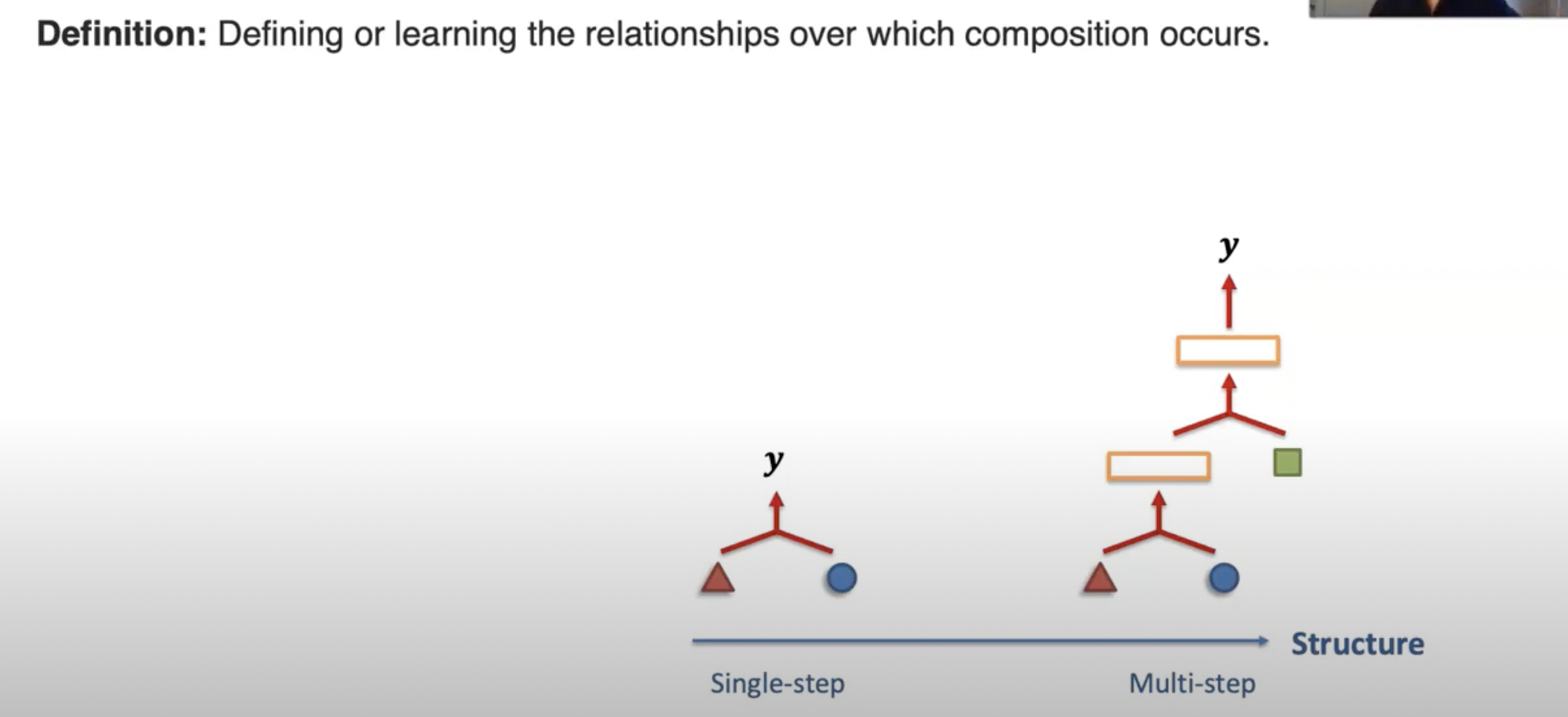
B. Intermediate Concepts
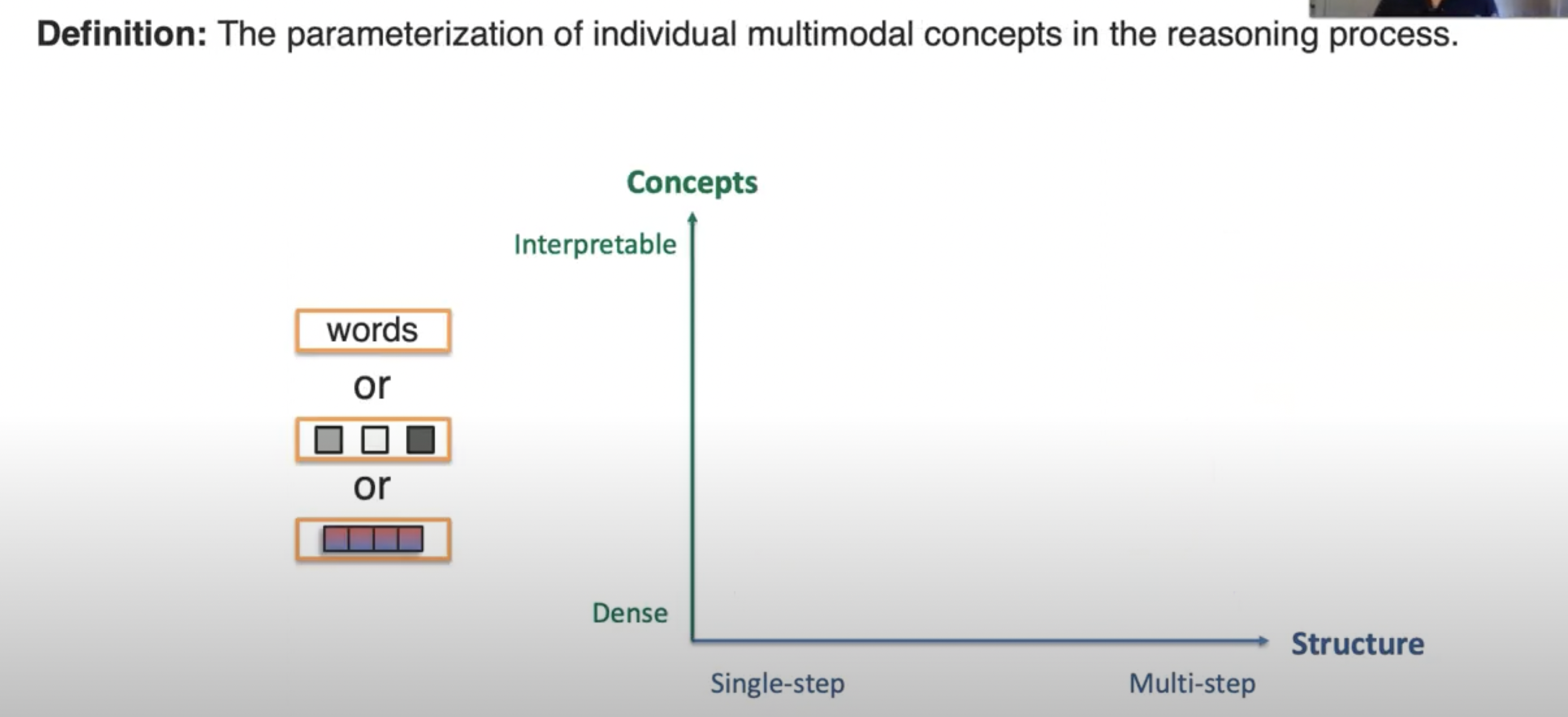
C. Inference Paradigms
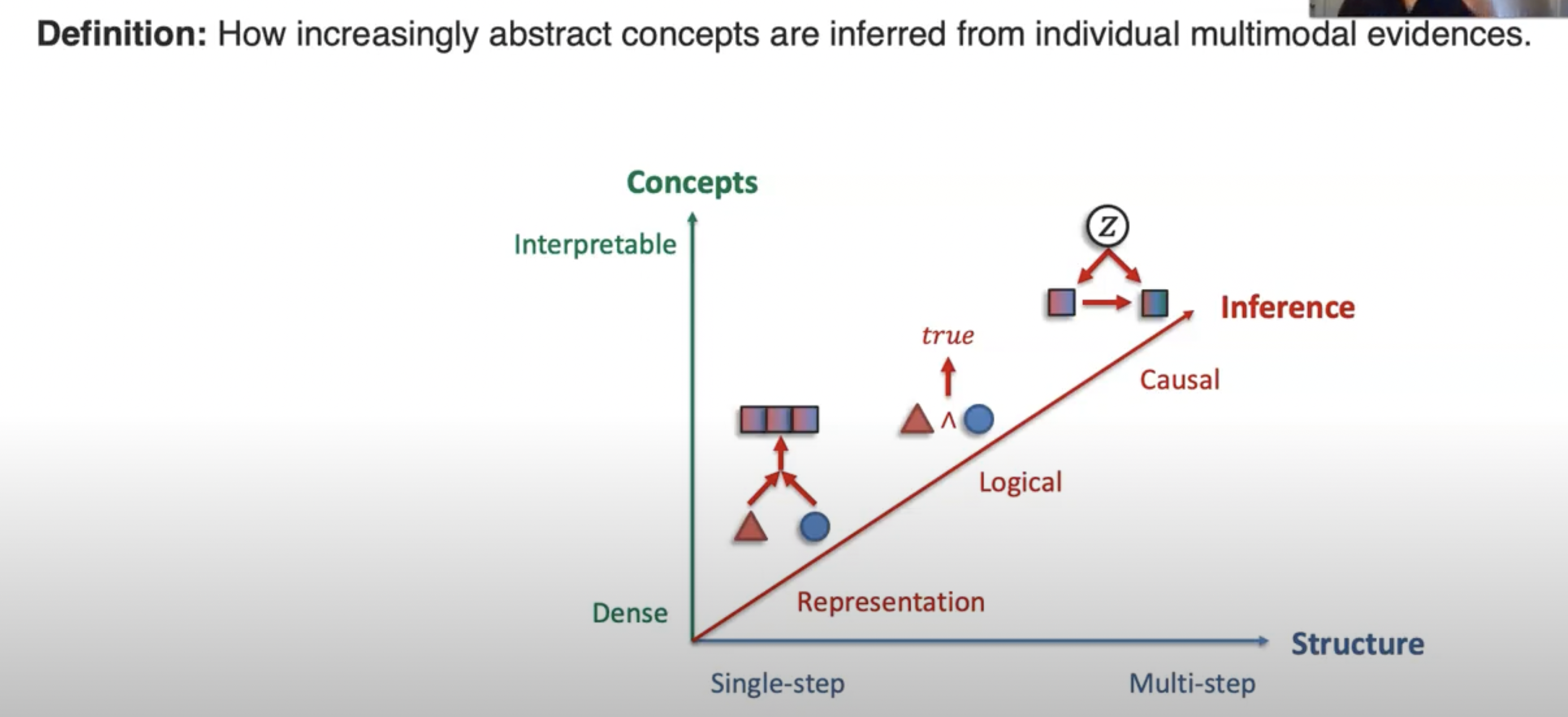
D. External Knowledge
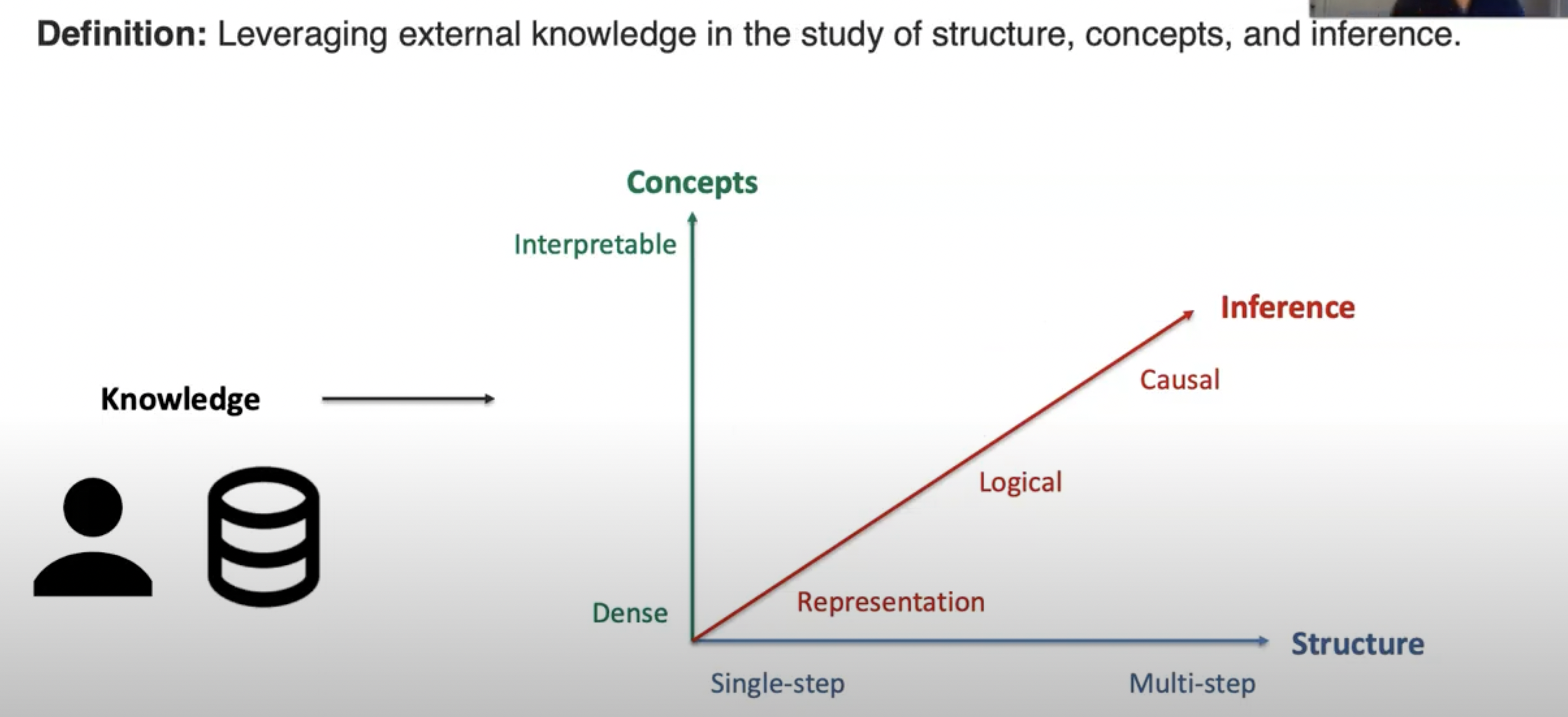
4. Generation
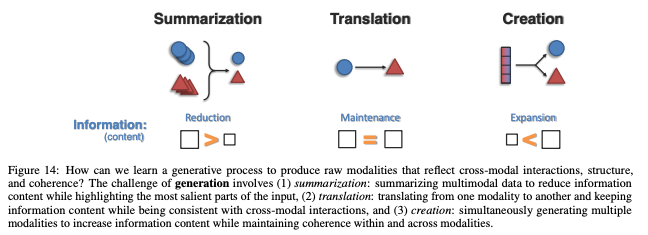
Generation은 멀티 모달 상호 작용, 구조 및 일관성을 반영하는 raw modalities을 생성하는 생성 프로세스를 학습하는 것을 포함한다.
세부 챌린지로는 Summarization, Translation, Creation으로 구성된다.
A. Summarization
B. Translation
C. Creation
5. Transference

Transference는 modalities과 그 Representation들 사이의 knowledge을 전달하는 것을 목표로 한다.
세부 챌린지로는 Cross-modal Transfer, Multimodal Co-learning, Model Induction으로 구성된다.
A. Cross-modal Transfer
B. Multimodal Co-learning
C. Model Induction
6. Quantification
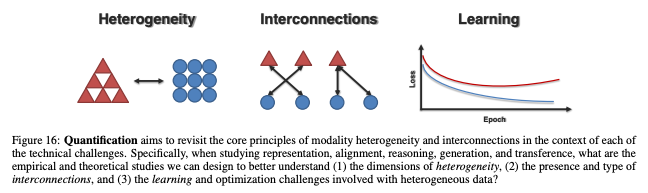
Quantification는 heterogeneity, interconnections 및 multimodal learning process을 더 잘 이해하기 위한 경험적 및 이론적 연구를 포함한다.
세부 챌린지로는 Dimensions of Heterogeneity, Modality Interconnections, Multimodal Learning Process으로 구성된다.
A. Dimensions of Heterogeneity
B. Modality Interconnections
C. Multimodal Learning Process
Reference
https://arxiv.org/pdf/2209.03430.pdf
https://www.youtube.com/watch?v=helW1httyO8&list=PLki3HkfgNEsKPcpj5Vv2P98SRAT9wxIDa&index=1
728x90'AI > Multimodal' 카테고리의 다른 글