-
[2023 Winter Multimodal Seminar 1. Representation 1) Fusion] Tensor Fusion Network for Multimodal Sentiment Analysis 리뷰 (EMNLP, 2017, Oral)AI/Multimodal 2023. 1. 5. 16:56728x90
[2023 Winter Multimodal Seminar 1. Representation 1) Fusion]
Tensor Fusion Network for Multimodal Sentiment Analysis 리뷰 (EMNLP, 2017, Oral)목차
0. 들어가기 전에... : Representation Fusion
1. Introduction
2. Dataset : CMU-MOSI Dataset
3. Method : Tensor Fusion Network
4. Experiments
5. Qualitative Analysis
6. Conclusion
7. Code Review
0. 들어가기 전에... : Representation Fusion
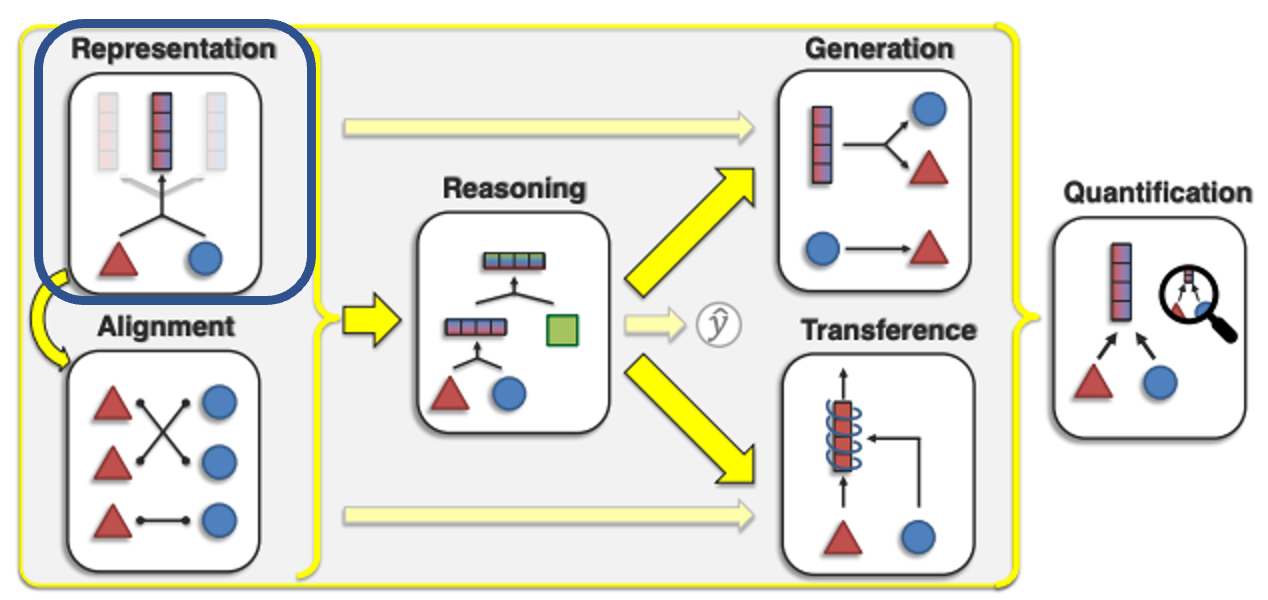
Multimodal의 Core Challenge는 위와 같이 크게 6가지로 나눠진다.
오늘 발표할 논문은 그 중 Representation에 해당한다.
Representation은 각 모달리티 요소 간의 이질성과 상호 연결을 반영하기 위해 멀티모달 데이터를 표현하고 요약하는 방법을 연구한다.
이 Challenge는 지역적인 표현 또는 전체적인 특징을 사용한 표현을 학습하고 생성해내는 것으로 볼 수 있다.
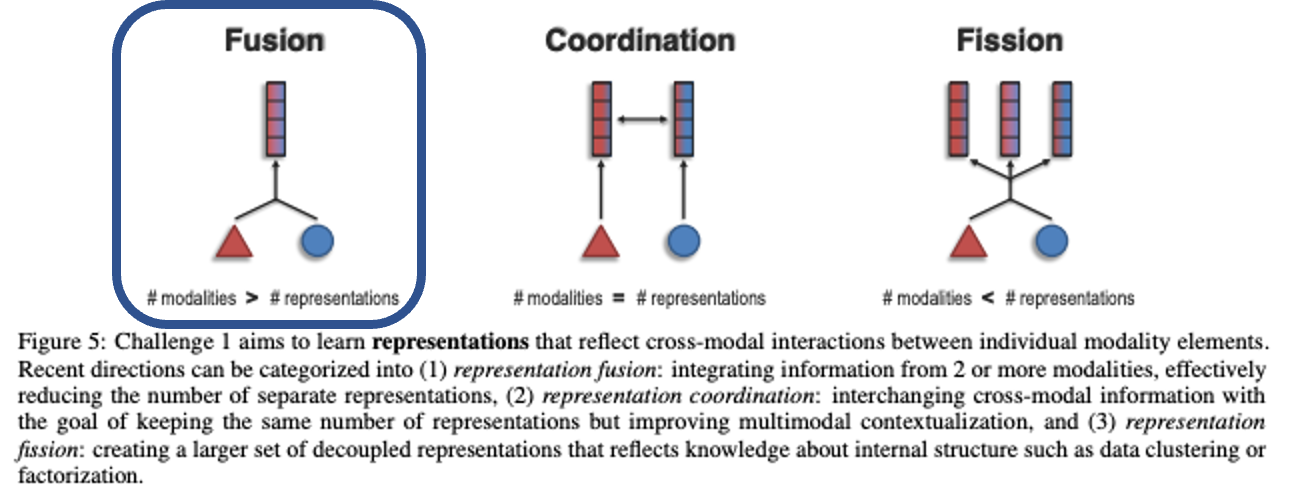
세부 챌린지로는 위와 Fusion, Coordination, Fission으로 구성된다. 나오는 output representation에 따라 구분된다.
- Fusion
- 두 개 이상의 모달리티에서 정보를 잘 융합하여 "개별 representation의 수를 효과적으로 줄이는 것"을 의미한다.
- Coordination
- "동일한 수의 representation을 유지하면서" multimodal contextualization를 개선하는 목표로 cross-modal information를 교환하는 것을 의미한다. 즉, 두 개의 모달리티 정보가 들어오면 두 정보를 잘 섞어서 두 개의 representation을 각각 조금씩 "조정"한다.
- 그 결과, output은 Fusion과 Fission과 달리 들어온 모달리티 정보의 개수와 동일하다.
- Fission은 input으로 들어온 N개의 모달리티 정보를 잘 결합하는 것까진 동일하나, 그것을 data clustering 이나 factorization을 통해 내부 구조에 대한 N+M개의 representation을 새롭게 생성해내는 것을 의미한다.
- 일반적으로 input set보다 더 큰 output set를 생성한다.
오늘 발표할 논문은 그 중 Fusion에 해당한다.
Coordination은 민한님이 Learning Transferable Visual Models From Natural Language Supervision에서,
Fission은 주호님이 Self-supervised Learning from a Multi-view Perspective에서 설명해주실 예정이다.
또한 Fusion 내에서도 합치는 방식에 따라 다음과 같이 나눌 수 있다.
1. Additive and multiplicative interactions
2. Multimodal gated units/attention units
3. Probabilistic approaches
4. Variational autoencoders
오늘 발표할 논문은 그 중 1. Additive and multiplicative interactions의 연장선인 Tensor Fusion에 해당한다.
자세한 것은 후술하도록 하겠다.
그렇다면,,,

시작 ! 1. Introduction
특히 소셜 미디어(Facebook, YouTube 등)에서 텍스트 대신 비디오에서 의견을 공유하는 추세가 증가하고 있기 때문에
음성 + 텍스트 + 비디오의 세 가지 모달리티를 사용한 multimodal sentiment analysis이 특히 중요하다

이 밈도 글자만 봤을 때나 그림만 봤을 때는 별로 안 웃기지만, 둘을 같이 봐야 비로소 그 의미가 빛을 발한다 
- Unimodal
- "This movie is sick"만 들으면 어떤 감정인지 모름
- 단순히 목소리가 큰 것만으론 어떤 감정인지 모름
- Bimodal
- "This movie is sick"를 큰 소리로 말하는 것도 어떤 감정인지 모름
- Trimodal
- "This movie is sick"를 큰 소리로 웃으면서 말하는 것은 좋은 의미!
➜ 각 모달리티 간의 정보를 잘 모델링하는 것이 중요함
- 이전 multimodal sentiment analysis 연구들의 한계점
- 모달리티 내(intra)에서의 정보와 모달리티 간(inter)의 정보를 직접적으로 설명하지 않는다
- 이전의 fusion 방식들(early fusion, late fusion)은 모달리티 정보를 효율적으로 모델링할 수 없다
- early fusion은 input level에서 단순히 feature들을 concatenate
- late fusion은 각 단일 모달 Classifier들을 학습시킨 후 decision voting을 하는 식으로 진행
- 어떻게 해결하려고 하였는가 ?
- Tensor Fusion Network 제시 : 모달리티 내에서의 정보와 모달리티 간의 정보를 모두 학습할 수 있도록
- Modality Embedding Subnetworks를 통해 각 모달리티 내의 정보를 잘 학습한다
- Tensor Fusion이라는 새로운 fusion 방식을 통해 모달리티 간의 정보를 잘 학습한다
- Tensor Fusion Network 제시 : 모달리티 내에서의 정보와 모달리티 간의 정보를 모두 학습할 수 있도록
➜ 당시 SOTA였던 unimodal과 multimodal sentiment analysis 모델의 성능을 능가함
2. Dataset : CMU-MOSI Dataset

CMU-MOSI(Multimodal Corpus of Sentiment Intensity) 데이터 셋은 2199개의 opinion video clip들로 되어있다.
비디오는 YouTube에서 영화 리뷰에 대한 의견으로, [-3,3] 범위의 감정으로 주석이 달려있다고 한다.
각 비디오의 평균 길이는 4.2초고, 총 26,295개의 단어가 등장했다.
현재는 어떤 모델이 SOTA일까 궁금해서 봤더니,

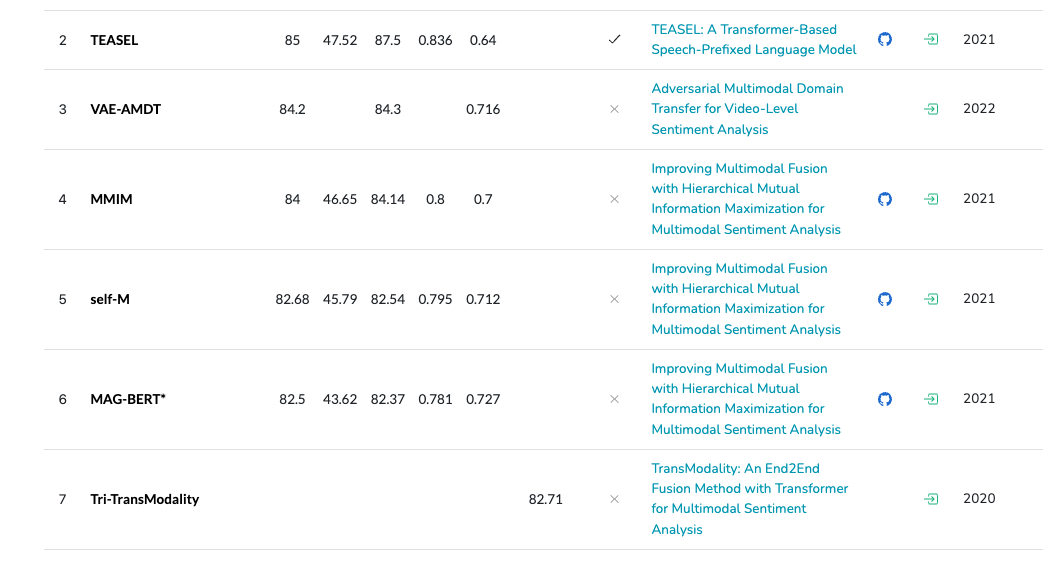
이미 오래 전 논문이라 리더보드에서도 이 논문에서 제안된 모델의 성능이 안 보인지 꽤 됐나 보다...
하지만 여기에 있는 논문만 따로 봐도 재밌고 흥미로운 게 많을 듯 하다 ! >0^
데이터 접근도 아주 간편하게 ~ 최고 ~
git clone git@github.com:A2Zadeh/CMU-MultimodalSDK.git export PYTHONPATH="/path/to/cloned/directory/CMU-MultimodalSDK:$PYTHONPATH" pip install h5py validators tqdm numpy argparse requestshttps://github.com/A2Zadeh/CMU-MultimodalSDK
GitHub - A2Zadeh/CMU-MultimodalSDK: CMU MultimodalSDK is a machine learning platform for development of advanced multimodal mode
CMU MultimodalSDK is a machine learning platform for development of advanced multimodal models as well as easily accessing and processing multimodal datasets. - GitHub - A2Zadeh/CMU-MultimodalSDK: ...
github.com
3. Method : Tensor Fusion Network
아까 맨 처음에 Fusion을 소개할 때, 합치는 방식도 다양하다고 말한 바 있다.
이 논문에서 소개된 Tensor Fusion을 소개하기 이전에 먼저 짚고 넘어가야 할 것이 있다.
왜 이전의 fusion 방식들(early fusion, late fusion)은 모달리티 정보를 효율적으로 모델링할 수 없다는 것인지 자세히 보도록 하겠다.
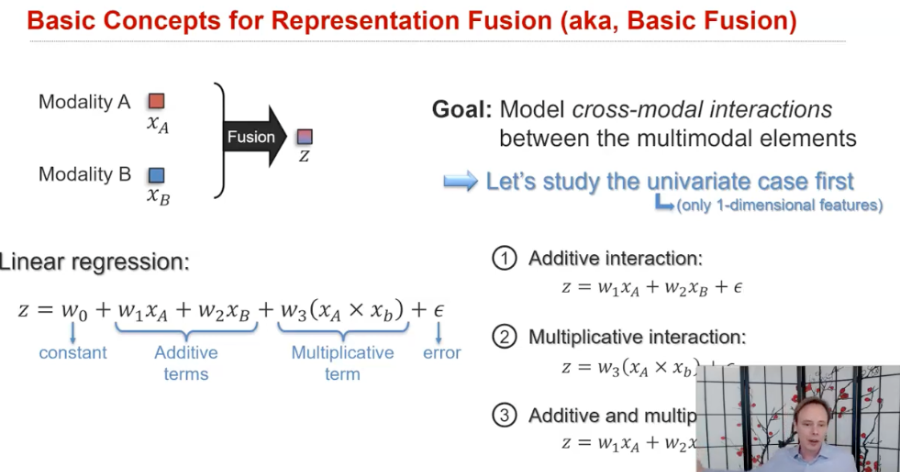
두 모달리티에서 나온 representation을 합친다고 할 때, 가장 간단하게 생각 할 수 있는 방식은 더하는 것과 곱하는 것이다.
단순히 두 벡터를 더하기만 하면 당연히 1차원의 벡터가 나올 것이고,
두 벡터를 벡터 곱(vector product, 내적 아님 내적은 결과값 스칼라, 얘는 외적임)해주면 그 아웃풋도 벡터로 나오고,
한 벡터를 transpose해주고 곱한다면 2차원 행렬로도 표현이 가능하다
하지만 이런 방법은 저자가 한계점으로 꼽았듯이, 한 모달리티 내의 원래 정보가 사라지고 혼합된 이후의 정보만 남게 된다따라서 본 논문에서 처음 소개된 Tensor Fusion은
(1) 합쳐지기 전의 각 모달리티 내의 representation과,(2) 합쳐지고 나서의, 모달리티 간의 representation이 모두 존재할 수 있도록 하는 방식인 것이다.
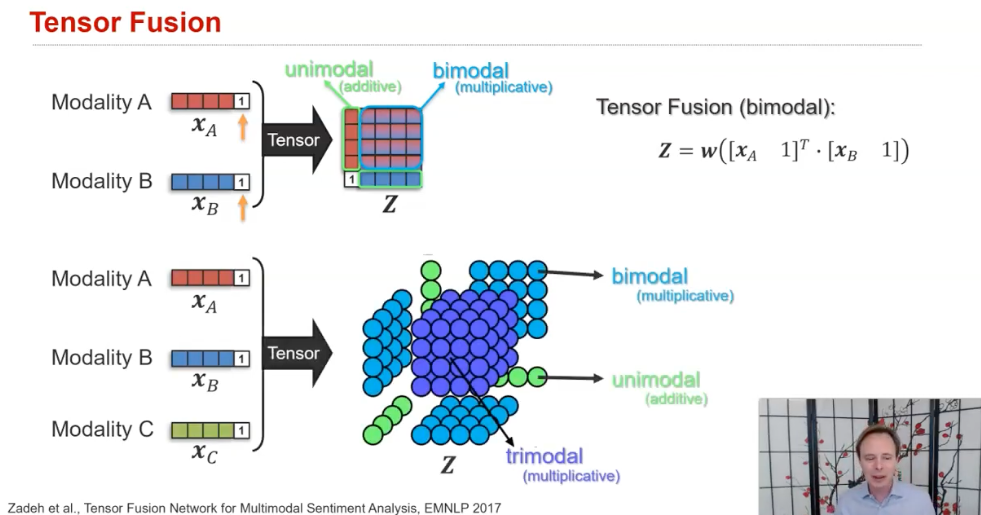
본 논문에서 제시한 모델은 크게 세 부분으로 이뤄진다.
1) Modality Embedding Subnetworks
2) Tensor Fusion Layer
3) Sentiment Inference Subnetwork
1. Modality Embedding Subnetworks
- input : 각 모달리티 feature들
- output : 각 모달리티에 대한 embedding 값
(1) Spoken Language Embedding Subnetwork
- 문어체와 구어체는 문법적으로나, 구성적으로 차이가 있다
- 구어체 : “I think it was alright . . . Hmmm . . . let me think . . . yeah . . . no . . . ok yeah”
- 처음 발화에서는 강하게 말하다가, 뒤에서는 흐릿하게 말하는 등의 변동성

➜ Glove로 300차원의 word vector 뽑고, LSTM을 통해 128차원의 time-dependent language representations 뽑음
(2) Visual Embedding Subnetwork
- FACET이라는 facial expression analysis framework을 통해 비디오 속의 얼굴 표정(anger, contempt, disgust, fear, joy, sadness,surprise, frustration, confusion) 9개를 뽑아냄
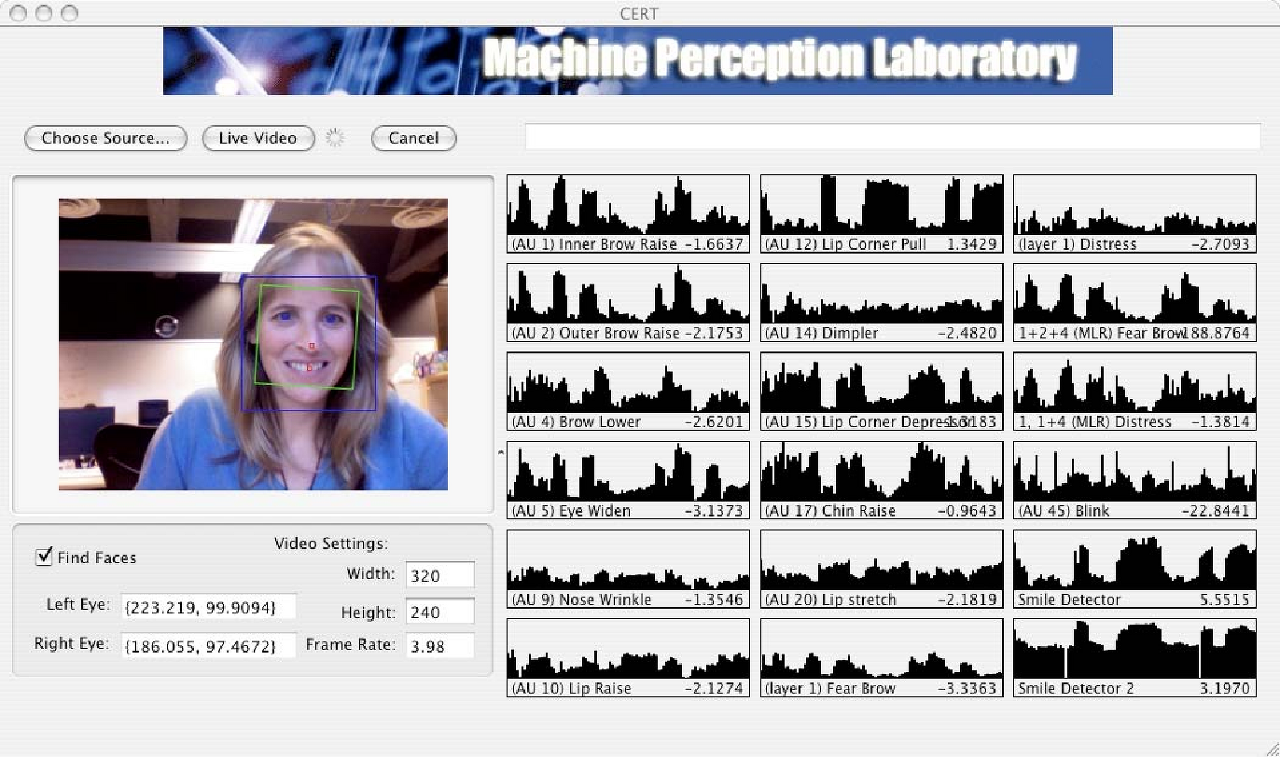
- OpenFace을 통해 각 프레임마다 head position, head rotation, and 68 facial landmark 뽑아냄

https://cmusatyalab.github.io/openface/
OpenFace
From here you can search these documents. Enter your search terms below.
cmusatyalab.github.io
- frame j개마다, p개의 feature들 뽑아서 mean pooling 쳐줘서 v 만들었대
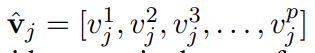

- network는 3개의 linear layer 쌓아서 만들었단다
- We use a deep neural network with three hidden layers of 32 ReLU units and weights Wv.
- 32차원

(3) Acoustic Embedding Subnetwork
- COVAREP 을 통해 아래와 같은 acoustic feature들을 뽑았다
- 12 MFCCs
- pitch tracking
- Voiced/UnVoiced segmenting features (using the additive noise robust Summation of Residual Harmonics (SRH) method (Drugman and Alwan, 2011)),
- glottal source parameters (estimated by glottal inverse filtering based on GCI synchronous IAIF (Drugman et al., 2012; Alku, 1992; Alku et al., 2002, 1997; Titze and Sundberg, 1992; Childers and Lee, 1991))
- peak slope parameters (Degottex et al., 2014)
- maxima dispersion quotients (MDQ) (Kane and Gobl, 2013),
- estimations of the Rd shape parameter of the Liljencrants-Fant (LF) glottal model (Fujisaki and Ljungqvist, 1986)
https://covarep.github.io/covarep/
COVAREP by COVAREP
COVAREP A Cooperative Voice Analysis Repository for Speech Technologies Homepage Contributions Contributors Contribute! Aim COVAREP is an open-source repository of advanced speech processing algorithms and stored in a GitHub project where researchers in sp
covarep.github.io
- frame j개마다, p개의 feature들 뽑아서 mean pooling 쳐줘서 v 만들었대


- network는 3개의 linear layer 쌓아서 만들었단다
- We use a deep neural network with three hidden layers of 32 ReLU units and weights Wv.
- 32차원
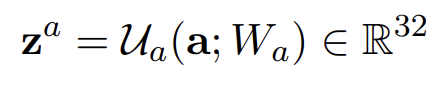
2. Tensor Fusion Layer
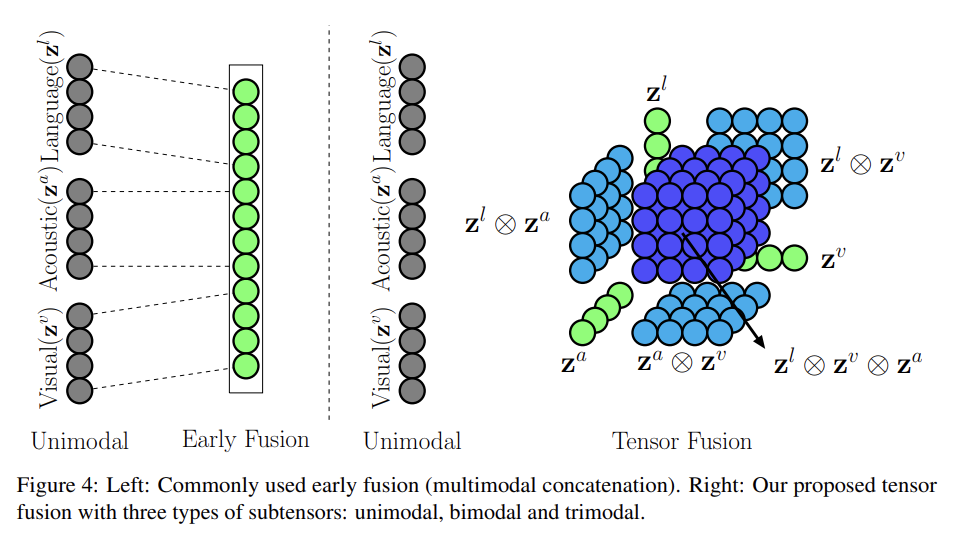
- 곱집합(Cartesian Product)을 통해 unimodal, bimodal, trimodal tensor들을 생성

(128 + 1) * (32 + 1) * (32 * 1)
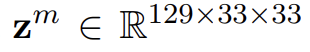
3. Sentiment Inference Subnetwork
- 2개 층의 FC layers+ 128 ReLU activation units
- variations
- binary sentiment classification
- a single sigmoid output neuron
- binary cross-entropy loss
- five-class sentiment classification
- uses a softmax probability function
- categorical cross-entropy loss
- sentiment regression
- a single sigmoid output,
- mean squarred error loss
- binary sentiment classification
4. Experiments
실험은 세 가지로 이뤄진다
- Multimodal Sentimental Analysis 분야에서의 이전 SOTA 모델들과의 비교
- Ablation Study
- 각 모달리티별 Sentimental Analysis 분야(Unimodal Sentimental Analysis)에서의 SOTA 모델들과의 비교
- Multimodal Sentimental Analysis 분야에서의 이전 SOTA 모델들과의 비교

- 특히 5 class classification에서 성능차이가 크게 보인다
- C-MKL
- 당시 SOTA 모델이었음
- CNN으로 피쳐 뽑고 커널 러닝으로 clf
- SAL-CNN
- SVM-MD, RF
- Early Fusion 방식으로 했고 non-neural 방식과 비교하기 위해서
2. Ablation Study
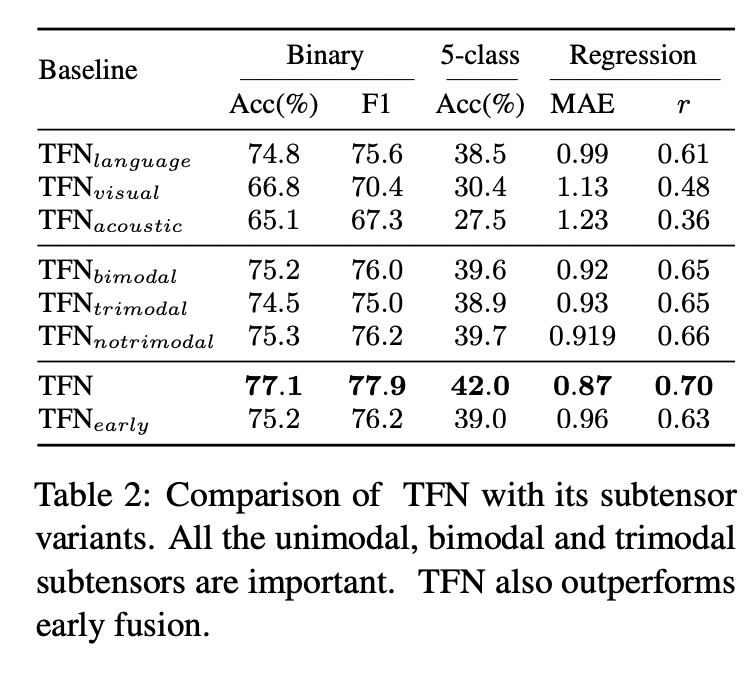
- TFN_bimodal
- only the bimodal subtensors are used
- TFN_trimodal
- when only the trimodal subtensor is used
- TFN_notrimodal
- the trimodal subtensor is removed (but all the unimodal and bimodal subtensors are present)
➜ unimodal, bimodal, trimodal 정보 다 중요하기에 다 반영해야 된다 ~
3. 각 모달리티별 Sentimental Analysis 분야(Unimodal Sentimental Analysis)에서의 SOTA 모델들과의 비교


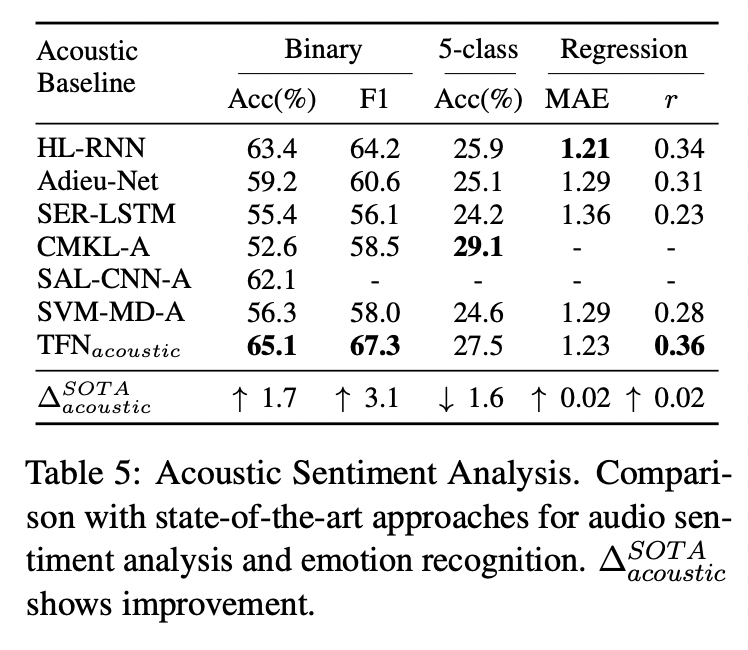
- Language Model :
- 이전 SOTA들은 Written language에선 잘 작동하고 spoken language에 대해선 잘 모델링하지 못한다
- 문법적인 차이 때문에....
5. Qualitative Analysis

3가지 단일 모달 모델들(TFN-Acoustic / TFN-VIsual / TFN-Language)와 Early Fusion 모델(TFN-Early), 그리고 본 논문의 모델 TFN의 결과를 비교한 Case Study 결과다.
결과를 해석하자면, Early Fusion 모델은 주로 TFN-Language의 성능을 많이 따르는 반면,
우리의 TFN은 각 모달리티의 정보들을 골고루 잘 반영하는 것을 알 수 있다.
물론 성능도 Early Fusion 모델보다 좋은 것을 확인할 수 있다.
실제 Case와 함께 살펴보자면,
첫 번째 경우는 그 화자가 영화에서 재미있는 농담이 부족했다는 언급을 했는데, 그 말 자체는 약한 부정이다.
만약 우리가 영상을 통해 화자의 얼굴 표정을 봤다면, 얼굴 찡그림을 통해 강하게 부정적인 의사를 표현했다는 것을 알 수 있었을 텐데 !
다행히도 이는 TFN 접근 방식에 의해 올바르게 포착된다.

이런 경우였나 보다 6. Conclusion
이 이후에도 Fusion 방식이 많이 발전하게 되어
Multimodal gated units나 attention units를 사용하여 FC layer, Kernel 기반 방식, attention 메카니즘 등을 적용해서, 각 input마다 동적으로 representation을 학습하는 모델도 등장했고,
Hidden Conditional Random Fields (HCRFs), deep Boltzmann machines 등 확률론 기반으로 Fusion하는 방식들과,
Variational autoencoders를 사용하는 모델들도 나타났다고 한다 ~
논문의 장점 :
1. Case Study를 잘해서 확실히 논문에서 강조하고자 하는 본 모델의 강점을 잘 파악할 수 있었다.
2. 쉬운데 기발한 것이 더 어려운데 그 부분에서 Tensor Fusion 짱이당
논문의 단점 :
1. 2017년 논문이라 너무 간단했다 ! 논문 자체의 문제는 아니지만 케케
개인적 소감 :
1. 우리 연구도 어떻게 Fusion을 잘할지가 관건일 듯 하다
2. 찾아보니 치매와 경도인지 장애를 진단키 위해서 Multimodal Fusion 방식을 제안한 2014년 논문이 있다! 한국인 저자다... multimodal survey 논문에서 소개해줌, 우리 논문도 이렇게 크게 되길 🙏
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4165842/
Hierarchical Feature Representation and Multimodal Fusion with Deep Learning for AD/MCI Diagnosis
For the last decade, it has been shown that neuroimaging can be a potential tool for the diagnosis of Alzheimer’s Disease (AD) and its prodromal stage, Mild Cognitive Impairment (MCI), and also fusion of different modalities can further provide ...
www.ncbi.nlm.nih.gov
7. Code Review
1) 데이터 준비
여기서 문제 ....

- 본 논문이 나왔던 게 벌써 2017년인데 그 동안 데이터 불러오는 게 계속 많이 바뀌어서, 깃헙 코드가 돌아가지 않을 거란 말이 써져있다
➜ 불가피하게 실행은 못하고 코드만 뜯어보는 것으로 하겠다....
2) 코드
(1) SubNet
- video와 audio를 32차원으로 만들어주기 위한 linear layer + relu 층
from __future__ import print_function import torch import torch.nn as nn import torch.nn.functional as F from torch.autograd import Variable from torch.nn.parameter import Parameter from torch.nn.init import xavier_uniform, xavier_normal, orthogonal class SubNet(nn.Module): ''' The subnetwork that is used in TFN for video and audio in the pre-fusion stage ''' def __init__(self, in_size, hidden_size, dropout): ''' Args: in_size: input dimension hidden_size: hidden layer dimension dropout: dropout probability Output: (return value in forward) a tensor of shape (batch_size, hidden_size) ''' super(SubNet, self).__init__() self.norm = nn.BatchNorm1d(in_size) self.drop = nn.Dropout(p=dropout) self.linear_1 = nn.Linear(in_size, hidden_size) self.linear_2 = nn.Linear(hidden_size, hidden_size) self.linear_3 = nn.Linear(hidden_size, hidden_size) def forward(self, x): ''' Args: x: tensor of shape (batch_size, in_size) ''' normed = self.norm(x) dropped = self.drop(normed) y_1 = F.relu(self.linear_1(dropped)) y_2 = F.relu(self.linear_2(y_1)) y_3 = F.relu(self.linear_3(y_2)) return y_3- Text는 128차원으로 만들어지는 LSTM
class TextSubNet(nn.Module): ''' The LSTM-based subnetwork that is used in TFN for text ''' def __init__(self, in_size, hidden_size, out_size, num_layers=1, dropout=0.2, bidirectional=False): ''' Args: in_size: input dimension hidden_size: hidden layer dimension num_layers: specify the number of layers of LSTMs. dropout: dropout probability bidirectional: specify usage of bidirectional LSTM Output: (return value in forward) a tensor of shape (batch_size, out_size) ''' super(TextSubNet, self).__init__() self.rnn = nn.LSTM(in_size, hidden_size, num_layers=num_layers, dropout=dropout, bidirectional=bidirectional, batch_first=True) self.dropout = nn.Dropout(dropout) self.linear_1 = nn.Linear(hidden_size, out_size) def forward(self, x): ''' Args: x: tensor of shape (batch_size, sequence_len, in_size) ''' _, final_states = self.rnn(x) h = self.dropout(final_states[0].squeeze()) y_1 = self.linear_1(h) return y_1(2) Tensor Fusion Network
- 각 모달리티에 대한 값들의 외적을 구한다
class TFN(nn.Module): ''' Implements the Tensor Fusion Networks for multimodal sentiment analysis as is described in: Zadeh, Amir, et al. "Tensor fusion network for multimodal sentiment analysis." EMNLP 2017 Oral. ''' def __init__(self, input_dims, hidden_dims, text_out, dropouts, post_fusion_dim): ''' Args: input_dims - a length-3 tuple, contains (audio_dim, video_dim, text_dim) hidden_dims - another length-3 tuple, similar to input_dims text_out - int, specifying the resulting dimensions of the text subnetwork dropouts - a length-4 tuple, contains (audio_dropout, video_dropout, text_dropout, post_fusion_dropout) post_fusion_dim - int, specifying the size of the sub-networks after tensorfusion Output: (return value in forward) a scalar value between -3 and 3 ''' super(TFN, self).__init__() # dimensions are specified in the order of audio, video and text self.audio_in = input_dims[0] self.video_in = input_dims[1] self.text_in = input_dims[2] self.audio_hidden = hidden_dims[0] self.video_hidden = hidden_dims[1] self.text_hidden = hidden_dims[2] self.text_out= text_out self.post_fusion_dim = post_fusion_dim self.audio_prob = dropouts[0] self.video_prob = dropouts[1] self.text_prob = dropouts[2] self.post_fusion_prob = dropouts[3] # define the pre-fusion subnetworks self.audio_subnet = SubNet(self.audio_in, self.audio_hidden, self.audio_prob) self.video_subnet = SubNet(self.video_in, self.video_hidden, self.video_prob) self.text_subnet = TextSubNet(self.text_in, self.text_hidden, self.text_out, dropout=self.text_prob) # define the post_fusion layers self.post_fusion_dropout = nn.Dropout(p=self.post_fusion_prob) self.post_fusion_layer_1 = nn.Linear((self.text_out + 1) * (self.video_hidden + 1) * (self.audio_hidden + 1), self.post_fusion_dim) self.post_fusion_layer_2 = nn.Linear(self.post_fusion_dim, self.post_fusion_dim) self.post_fusion_layer_3 = nn.Linear(self.post_fusion_dim, 1) # in TFN we are doing a regression with constrained output range: (-3, 3), hence we'll apply sigmoid to output # shrink it to (0, 1), and scale\shift it back to range (-3, 3) self.output_range = Parameter(torch.FloatTensor([6]), requires_grad=False) self.output_shift = Parameter(torch.FloatTensor([-3]), requires_grad=False) def forward(self, audio_x, video_x, text_x): ''' Args: audio_x: tensor of shape (batch_size, audio_in) video_x: tensor of shape (batch_size, video_in) text_x: tensor of shape (batch_size, sequence_len, text_in) ''' audio_h = self.audio_subnet(audio_x) video_h = self.video_subnet(video_x) text_h = self.text_subnet(text_x) batch_size = audio_h.data.shape[0] # next we perform "tensor fusion", which is essentially appending 1s to the tensors and take Kronecker product if audio_h.is_cuda: DTYPE = torch.cuda.FloatTensor else: DTYPE = torch.FloatTensor _audio_h = torch.cat((Variable(torch.ones(batch_size, 1).type(DTYPE), requires_grad=False), audio_h), dim=1) _video_h = torch.cat((Variable(torch.ones(batch_size, 1).type(DTYPE), requires_grad=False), video_h), dim=1) _text_h = torch.cat((Variable(torch.ones(batch_size, 1).type(DTYPE), requires_grad=False), text_h), dim=1) # _audio_h has shape (batch_size, audio_in + 1), _video_h has shape (batch_size, _video_in + 1) # we want to perform outer product between the two batch, hence we unsqueenze them to get # (batch_size, audio_in + 1, 1) X (batch_size, 1, video_in + 1) # fusion_tensor will have shape (batch_size, audio_in + 1, video_in + 1) fusion_tensor = torch.bmm(_audio_h.unsqueeze(2), _video_h.unsqueeze(1)) # next we do kronecker product between fusion_tensor and _text_h. This is even trickier # we have to reshape the fusion tensor during the computation # in the end we don't keep the 3-D tensor, instead we flatten it fusion_tensor = fusion_tensor.view(-1, (self.audio_hidden + 1) * (self.video_hidden + 1), 1) fusion_tensor = torch.bmm(fusion_tensor, _text_h.unsqueeze(1)).view(batch_size, -1) post_fusion_dropped = self.post_fusion_dropout(fusion_tensor) post_fusion_y_1 = F.relu(self.post_fusion_layer_1(post_fusion_dropped)) post_fusion_y_2 = F.relu(self.post_fusion_layer_2(post_fusion_y_1)) post_fusion_y_3 = F.sigmoid(self.post_fusion_layer_3(post_fusion_y_2)) output = post_fusion_y_3 * self.output_range + self.output_shift return output- 외적하는 부분은 여기 !
- 먼저 audio와 video 곱해주고, 그 다음에 text랑 곱한다
# _audio_h has shape (batch_size, audio_in + 1), _video_h has shape (batch_size, _video_in + 1) # we want to perform outer product between the two batch, hence we unsqueenze them to get # (batch_size, audio_in + 1, 1) X (batch_size, 1, video_in + 1) # fusion_tensor will have shape (batch_size, audio_in + 1, video_in + 1) fusion_tensor = torch.bmm(_audio_h.unsqueeze(2), _video_h.unsqueeze(1)) # next we do kronecker product between fusion_tensor and _text_h. This is even trickier # we have to reshape the fusion tensor during the computation # in the end we don't keep the 3-D tensor, instead we flatten it fusion_tensor = fusion_tensor.view(-1, (self.audio_hidden + 1) * (self.video_hidden + 1), 1) fusion_tensor = torch.bmm(fusion_tensor, _text_h.unsqueeze(1)).view(batch_size, -1)Reference
https://arxiv.org/pdf/1707.07250.pdf
http://multicomp.cs.cmu.edu/resources/cmu-mosi-dataset/
CMU-MOSI Dataset | MultiComp
The Multimodal Corpus of Sentiment Intensity (CMU-MOSI) dataset is a collection of 2199 opinion video clips. Each opinion video is annotated with sentiment in the range [-3,3]. The dataset is rigorously annotated with labels for subjectivity, sentiment int
multicomp.cs.cmu.edu
https://github.com/pliang279/MultiBench
GitHub - pliang279/MultiBench: [NeurIPS 2021] Multiscale Benchmarks for Multimodal Representation Learning
[NeurIPS 2021] Multiscale Benchmarks for Multimodal Representation Learning - GitHub - pliang279/MultiBench: [NeurIPS 2021] Multiscale Benchmarks for Multimodal Representation Learning
github.com
728x90'AI > Multimodal' 카테고리의 다른 글
- Fusion